- A+
问题:对于超大的 string V8不能支持
问题背景
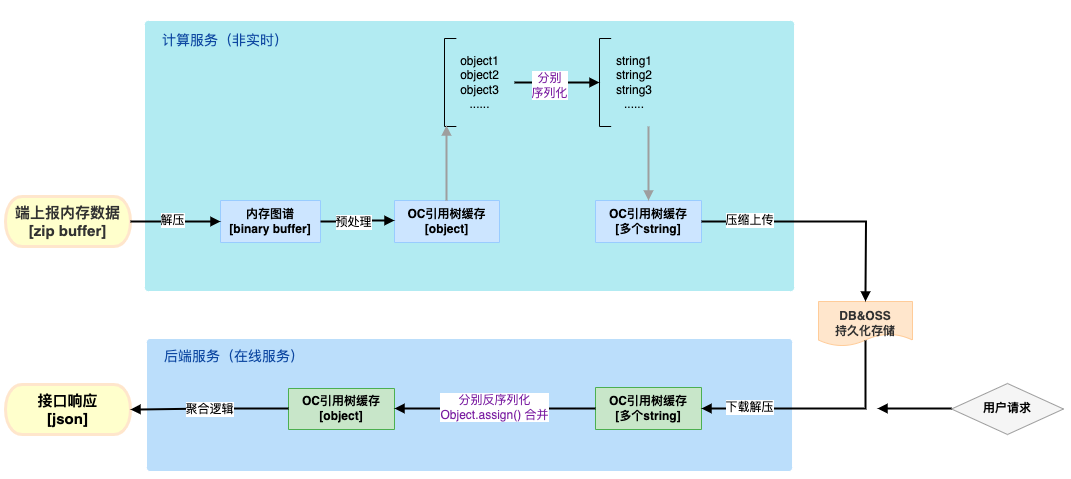
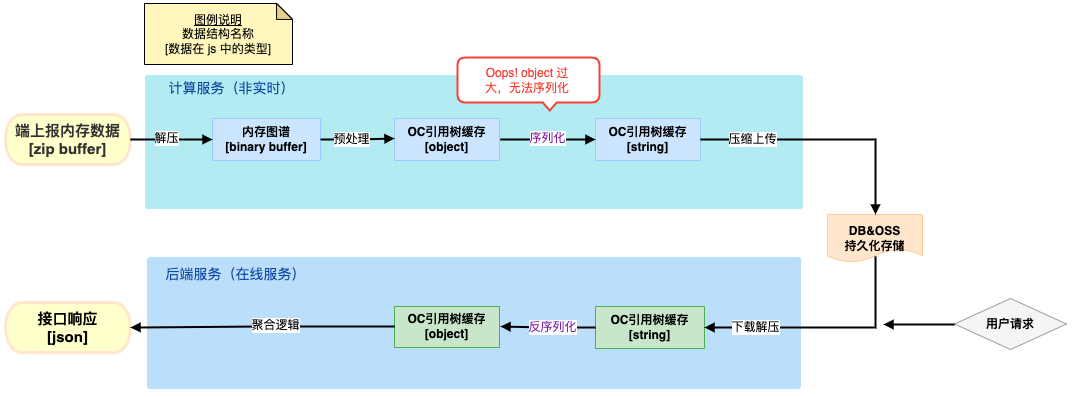
在 Nodejs 计算服务中,对端上上报的内存信息二进制数据进行预处理+缓存时,遇到了一个奇怪的报错:RangeError: Invalid string length 。根据该报错信息,查找得知是字符串长度超过了 node.js 的限制,即 2^29-1 (约 5 亿+)个字符。整体流程如图所示。
关于 node.js string 的长度上限,主要和 V8 引擎「压缩指针」技术有关。按个人理解,其通过压缩指向变量的地址(64 位)中固定的 32 位的方式,从而减少引擎的内存占用。
代码细节
由于需要快速访问某地址,因此缓存的数据结构必须是个对象,即 INodeGraph。具体结构如下:
type IAddr = string;// 内存图谱 declare interface INodeGraph { [addr: IAddr]: IParsedNode; }// 内存节点信息 declare interface IParsedNode { addr: IAddr; // size, nodeType 等辅助信息 parentNodeAddr: IAddr[]; // addr childNodeAddr: string[]; // addr edgeMap: { [addr: IAddr]: { // 当前节点与父子节点之间的边(关系)的信息 }; }; } |
我们目的很明确,就是实现这样一个 js 大对象的持久化存储,并且能够方便快速的转回 js object。为解决此问题,首先想到的能否利用 protobuf 替代 JSON 实现持久化。可惜的是 protobuf 并不适用于动态 key 的场景,它适用于处理数组中存储多个相似结构对象的数据结构。
随后尝试了减少对象中不必要的信息,即缩短对象的固定 key,例如用「pNode」取代冗长的「parentNodeAddr」。对于一个百万个键值对的 object 而言,虽然牺牲了代码的可读性,但在实际的 case 中,能承载的键值对数量大约多了 20%。
事实上回过头来看,更好的处理方式或许是用另外的 Map 存储对象的 key。例如 : 将 nodeGraph.parentNodeAddr 这个 key 最大程度缩短为 nodeGraph.p
声明 const GraphKey = { parentNodeAddr: 'p' } 保存一个 key 的映射,需要访问某属性时,使用nodeGraph[GraphKey.parentNodeAddr]
更进一步
上述手段只是治标不治本,对于 key 更多的大对象并不能彻底解决问题。因此在不改变项目整体架构的前提下(如使用图数据库/改用 go 开发等),提出以下两个最终方案:
方案 1:借助 Node.js C++ Addons 的能力,绕开 js string 的限制,将相关序列化逻辑交给 C++ 处理,并直接将处理好的引用树 js object 进行后续处理。
- 优势:如果能实现,性能会获得优先提升;扩展了 Node.js 的能力
- 劣势:实现难度大;维护可能是个问题
方案 2:生成引用树缓存时,拆分为多个较小的对象,分别进行序列化和存储,使用时再合并为一个大对象。
- 优势:无需 C++ 侧开发,难度更小;维护方便
- 劣势:合并对象需要额外的时间,这一步骤可能会让未命中缓存时的首次请求更慢