- A+
本章将和大家分享ES的数据同步方案和ES集群相关知识。废话不多说,下面我们直接进入主题。
一、ES数据同步
1、数据同步问题
Elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,Elasticsearch也必须跟着改变,这个就是Elasticsearch与mysql之间的数据同步。
在微服务中,负责酒店管理(操作mysql )的业务与负责酒店搜索(操作Elasticsearch )的业务可能在两个不同的微服务上,数据同步该如何实现呢?
2、数据同步方案一:同步调用
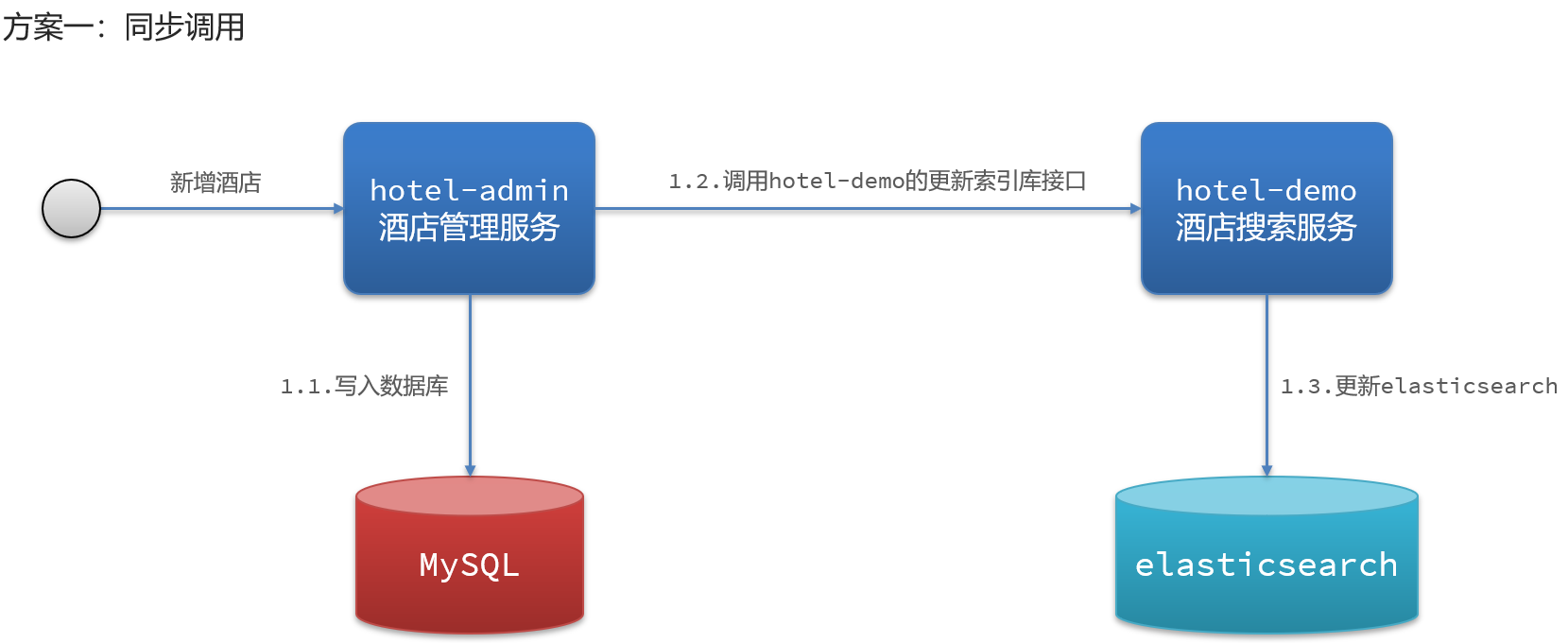
3、数据同步方案二:异步通知
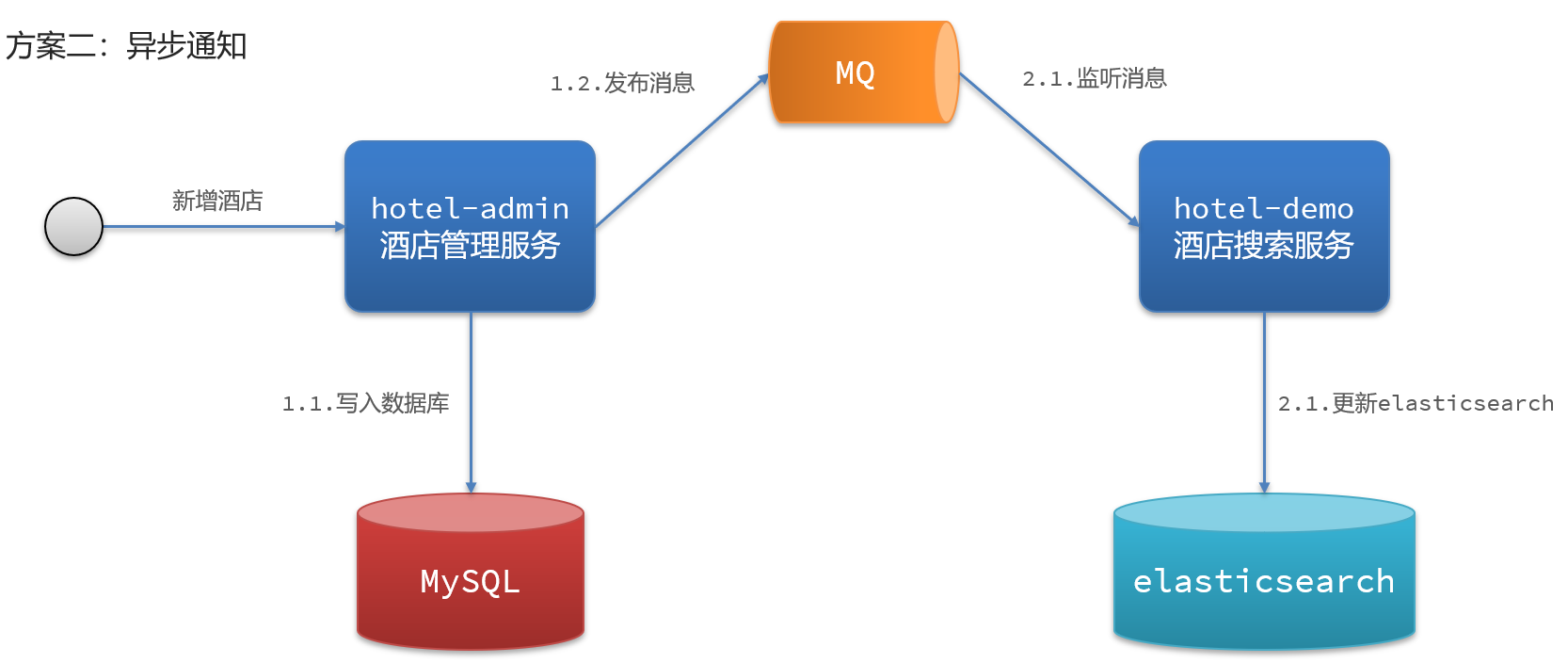
4、数据同步方案三:监听binlog
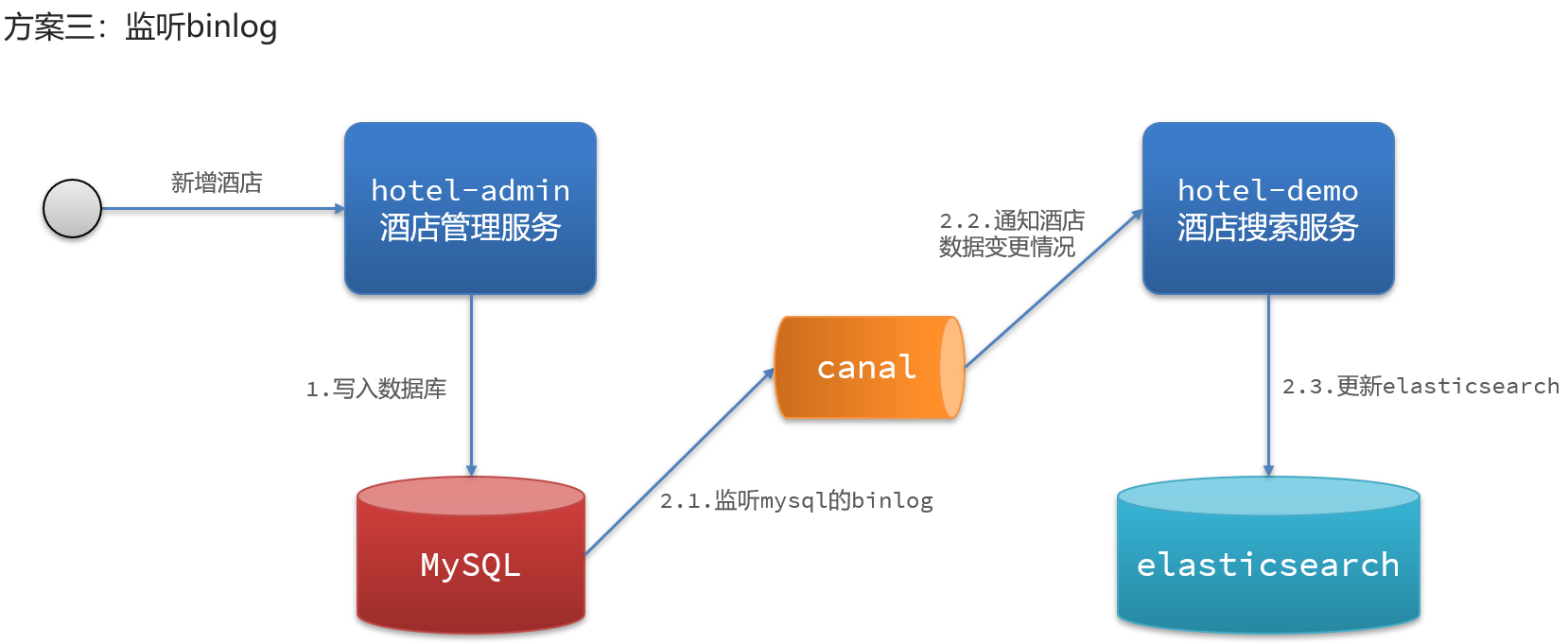
5、数据同步三种方案对比总结
方案一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方案二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方案三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
二、ES集群
1、ES集群结构
单机的Elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点。
- 单点故障问题:将分片数据在不同节点备份(replica )。
| 单点 | 集群 |
|
|
|
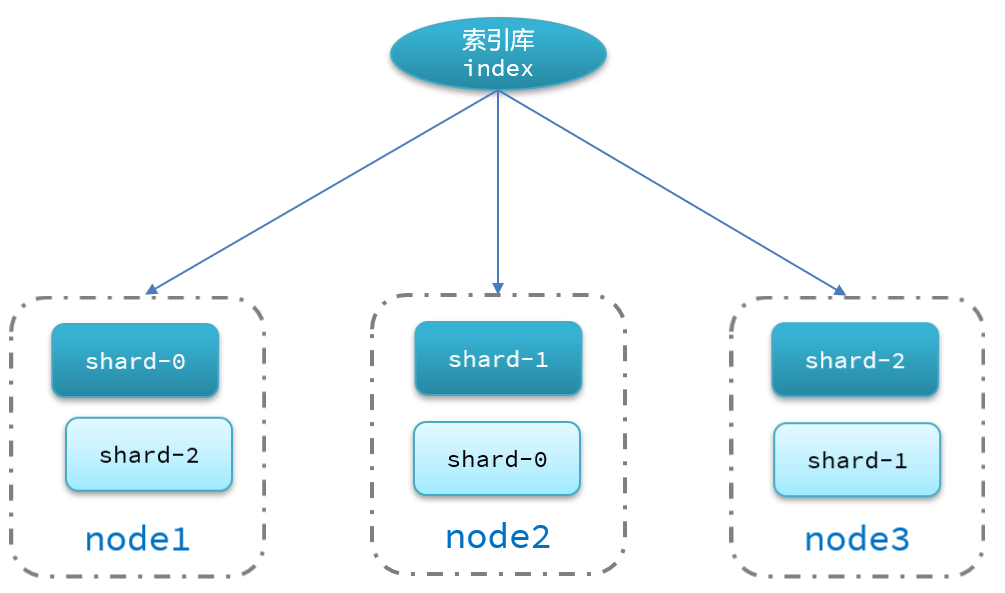
2、搭建ES集群
每个索引库的分片数量、副本数量都是在创建索引库时指定的,并且分片数量一旦设置以后无法修改。语法如下:
PUT /itcast { "settings": { "number_of_shards": 3, // 分片数量 "number_of_replicas": 1 // 副本数量 }, "mappings": { "properties": { // mapping映射定义 ... } } }
具体的ES搭建此处先不做介绍。
3、ES集群的节点角色
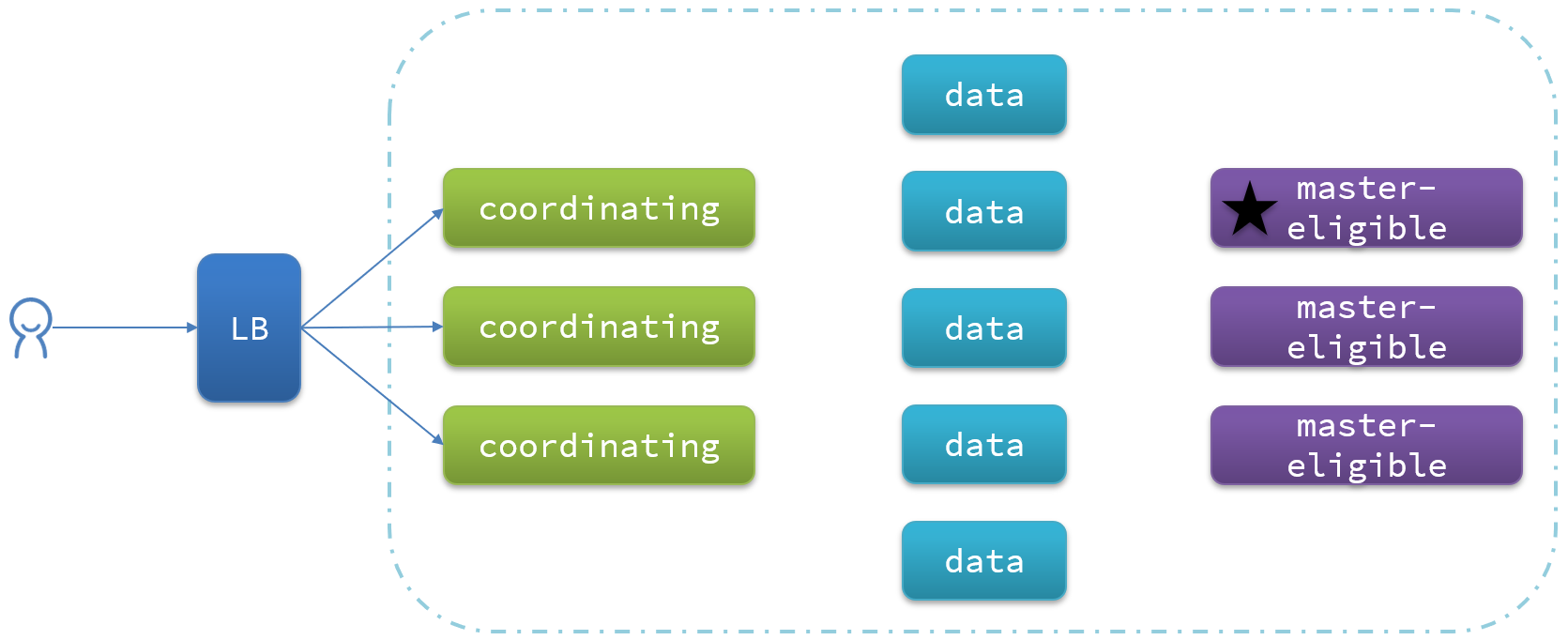
Elasticsearch中集群节点有不同的职责划分:
| 节点类型 | 配置参数 | 默认值 | 节点职责 |
| master eligible | node.master | true | 备选主节点:主节点可以管理和记录集群状态、决定分片在哪个节点、处理创建和删除索引库的请求。 |
| data | node.data | true | 数据节点:存储数据、搜索、聚合、CRUD |
| ingest | node.ingest | true | 数据存储之前的预处理 |
| coordinating | 上面3个参数都为false则为coordinating节点 | 无 | 协调节点:路由请求到其它节点,合并其它节点处理的结果,返回给用户 |
4、ES集群的分布式查询
Elasticsearch中的每个节点角色都有自己不同的职责,因此建议集群部署时,每个节点都有独立的角色。
5、ES集群的脑裂
默认情况下,每个节点都是master eligible节点,因此一旦master节点宕机,其它候选节点会选举一个成为主节点。当主节点与其他节点网络故障时,可能发生脑裂问题。
为了避免脑裂,需要要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题。
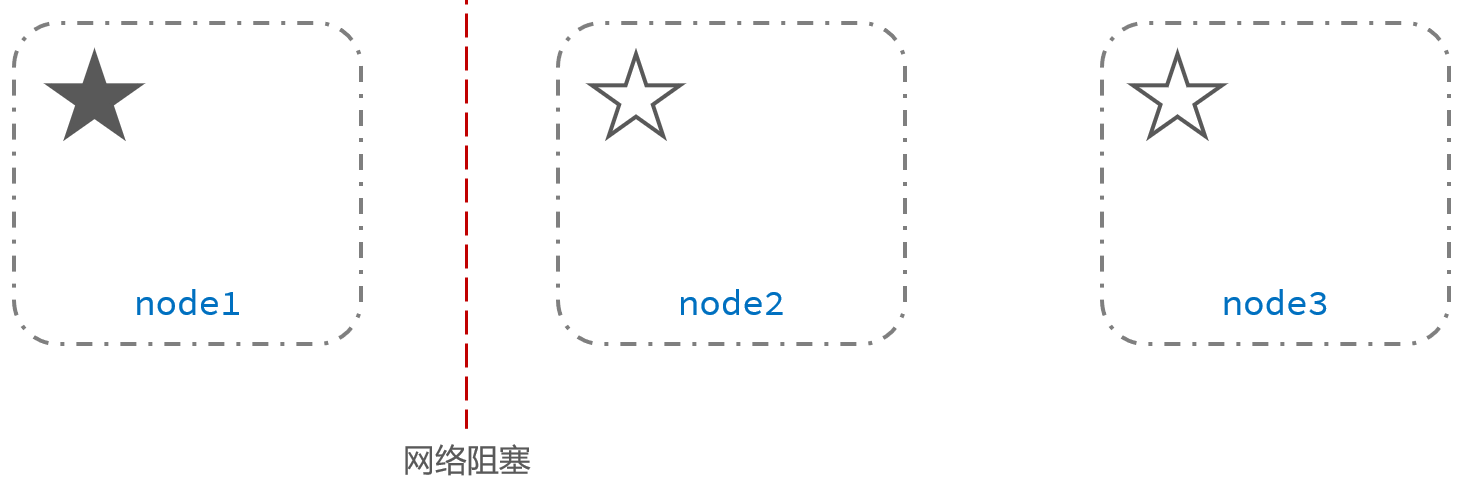
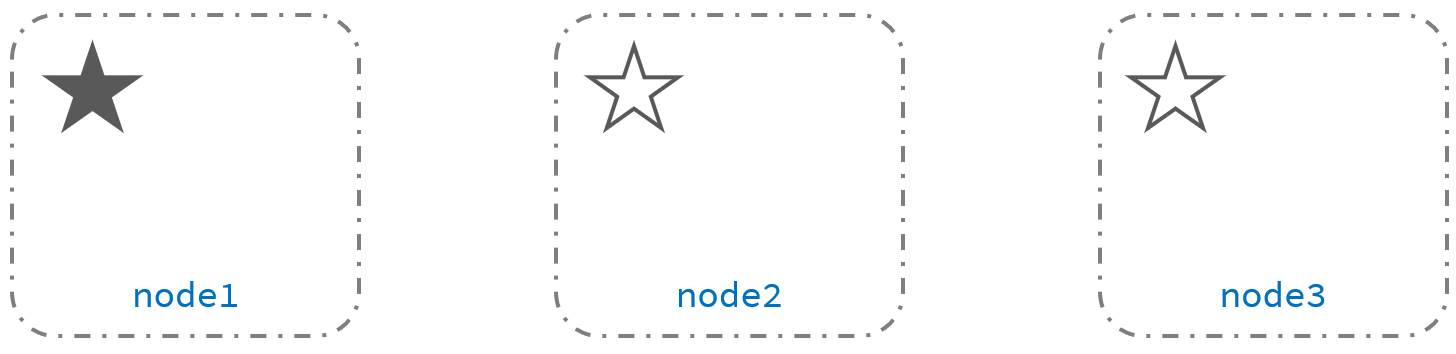
主从结构脑裂问题示意图:
|
1、正常时只有一个主节点
|
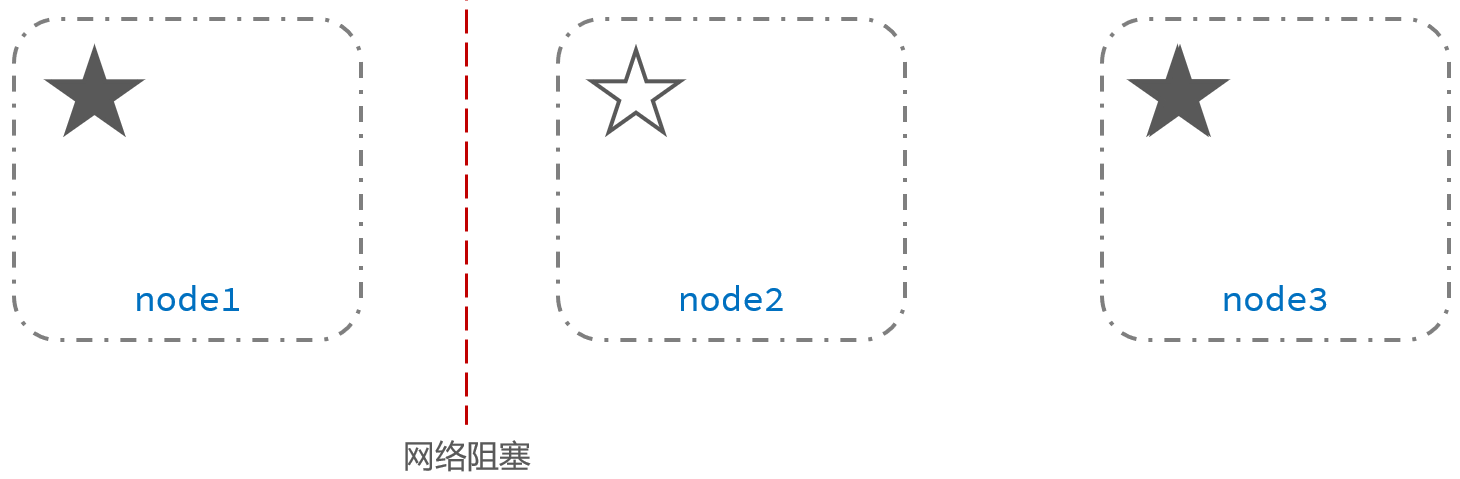
2、网络阻塞 |
|
|
 |
|
3、另外两个候选节点node2和node3重新选举主节点
|
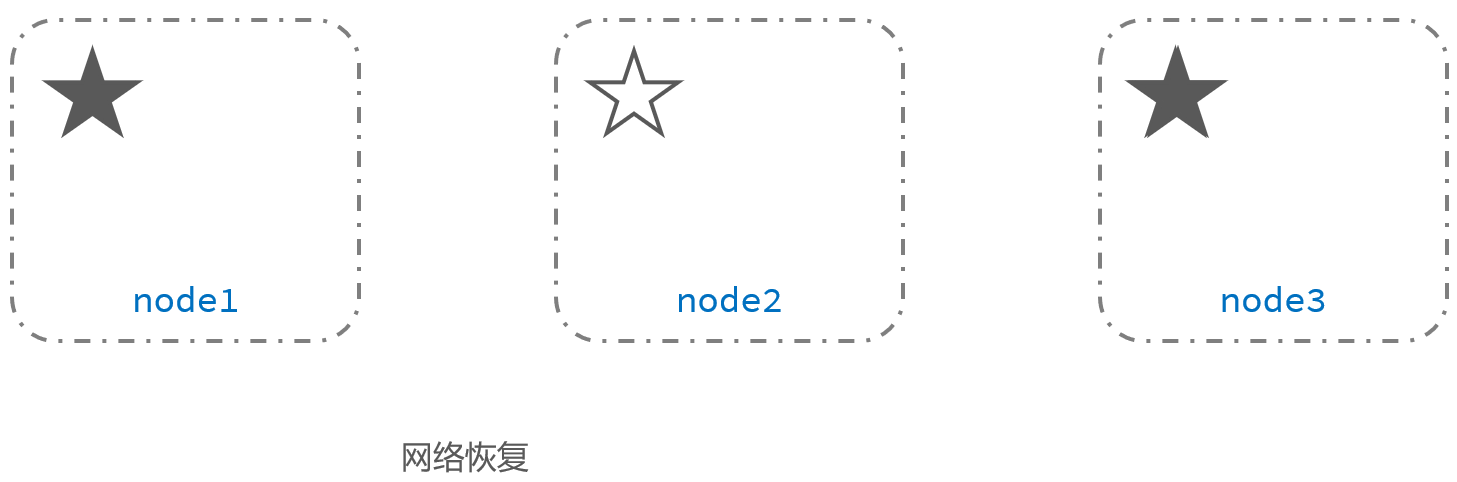
4、网络恢复,此时就出现了两个主节点,这就是脑裂问题 |
|
|
|
6、小结1
1)master eligible节点的作用是什么?
- 参与集群选主
- 主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
2)data节点的作用是什么?
- 数据的CRUD
3)coordinator节点的作用是什么?
- 路由请求到其它节点
- 合并查询到的结果,返回给用户
7、ES集群的分布式存储
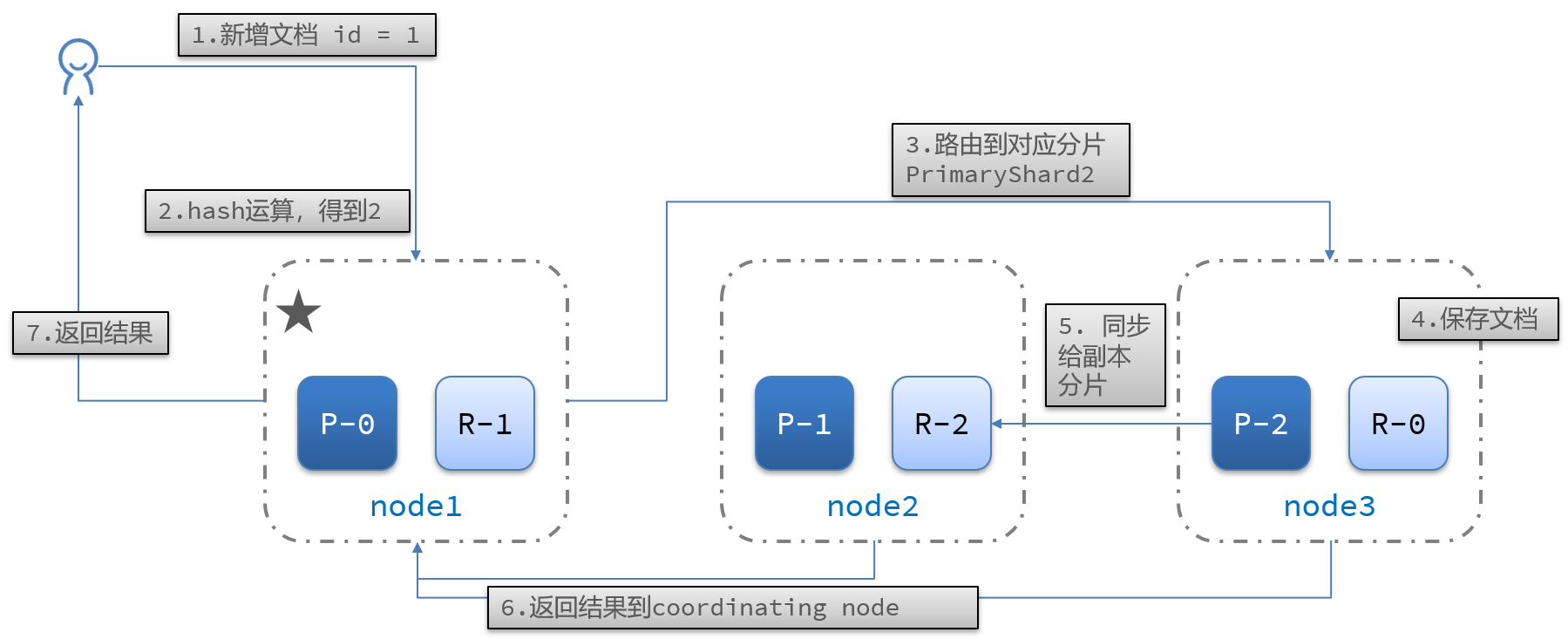
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到哪个分片呢?
Elasticsearch会通过hash算法来计算文档应该存储到哪个分片:
shard = hash(_routing) % number_of_shards
说明:
- _routing默认是文档的id
- 算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增文档流程:
8、ES集群的分布式查询
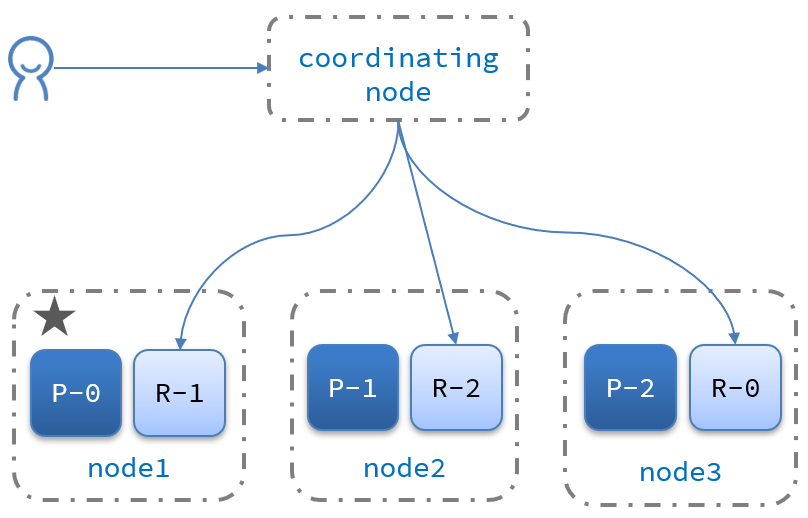
Elasticsearch的查询分成两个阶段:
- scatter phase:分散阶段,coordinating node会把请求分发到每一个分片。
- gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户。
9、小结2
1)分布式新增如何确定分片?
- coordinating node根据id做hash运算,得到结果对shard数量取余,余数就是对应的分片。
2)分布式查询的两个阶段
- 分散阶段:coordinating node将查询请求分发给不同分片
- 收集阶段:将查询结果汇总到coordinating node,整理并返回给用户
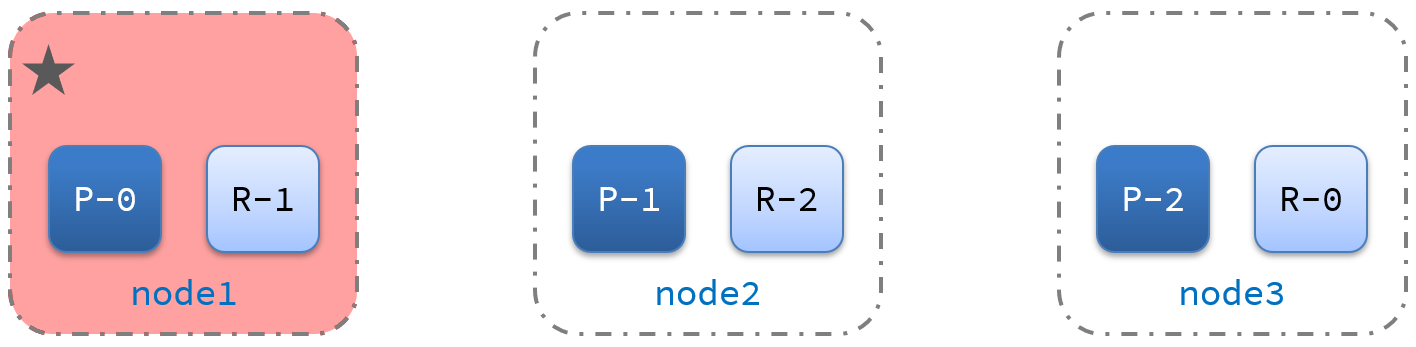
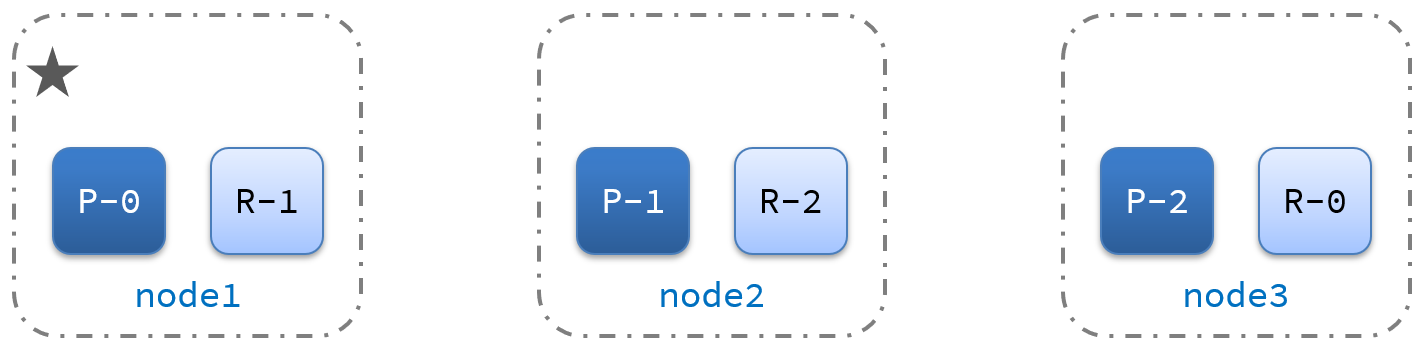
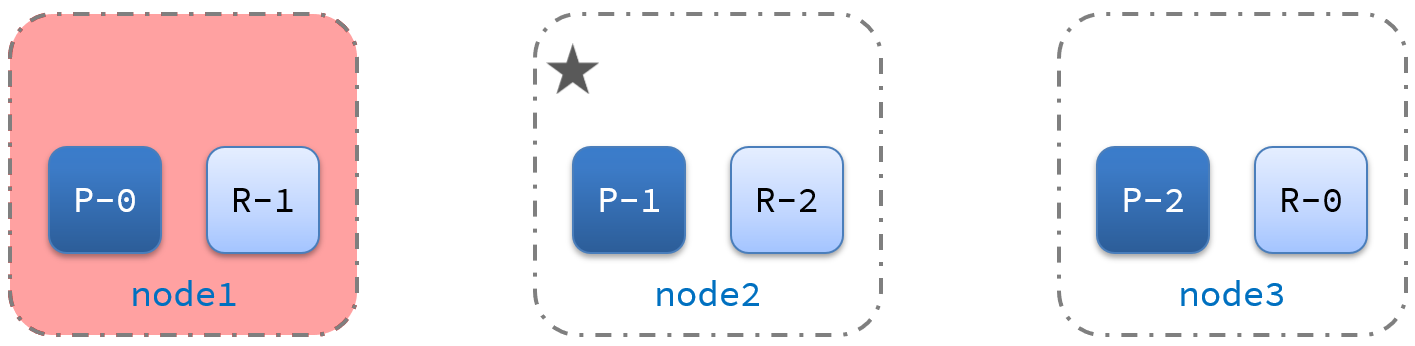
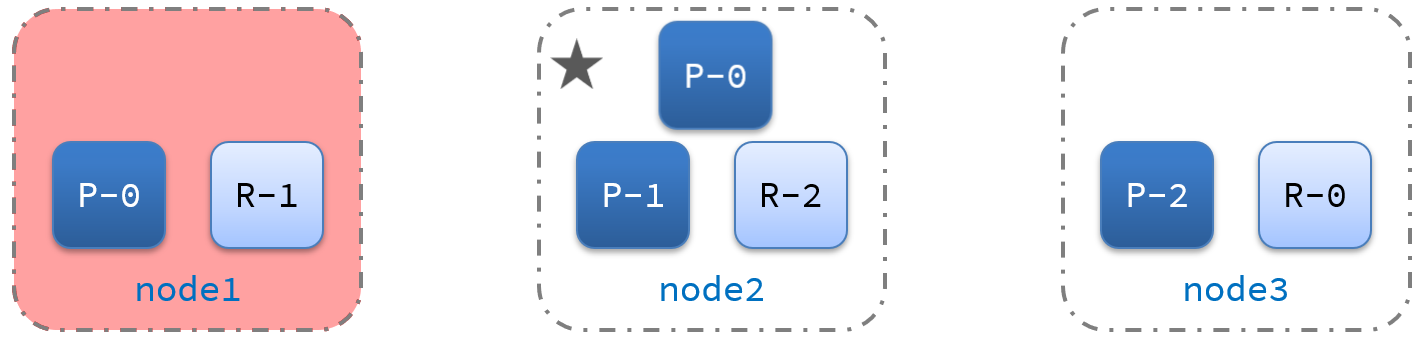
10、ES集群的故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
故障转移示意图:
| 1、正常状态 | 2、主节点宕机 |
|
|
 |
| 3、重新选举主节点 |
|
|
| 4.1、数据迁移 | 4.2、数据迁移 |
|
|
|
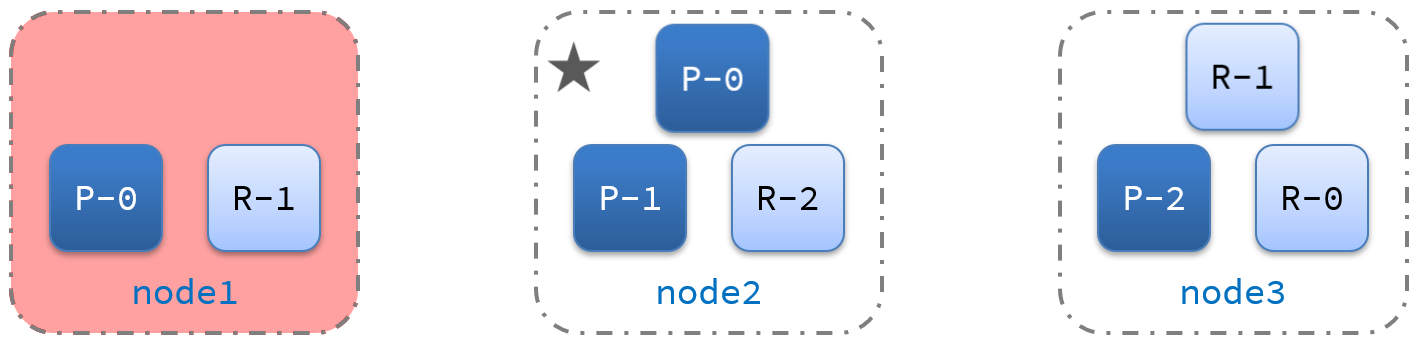
故障转移:
- master宕机后,EligibleMaster选举为新的主节点。
- master节点监控分片、节点状态,将故障节点上的分片转移到正常节点,确保数据安全。
至此本文就全部介绍完了,如果觉得对您有所启发请记得点个赞哦!!!




