- A+
XPath 通常用来进行网站、XML (APP )和数据挖掘,通过元素和属性的方式来获取指定的节点,然后抓取需要的信息。
学习 XPath 语法之前,首先了解一下一些概念。
概念介绍
节点之间的关系
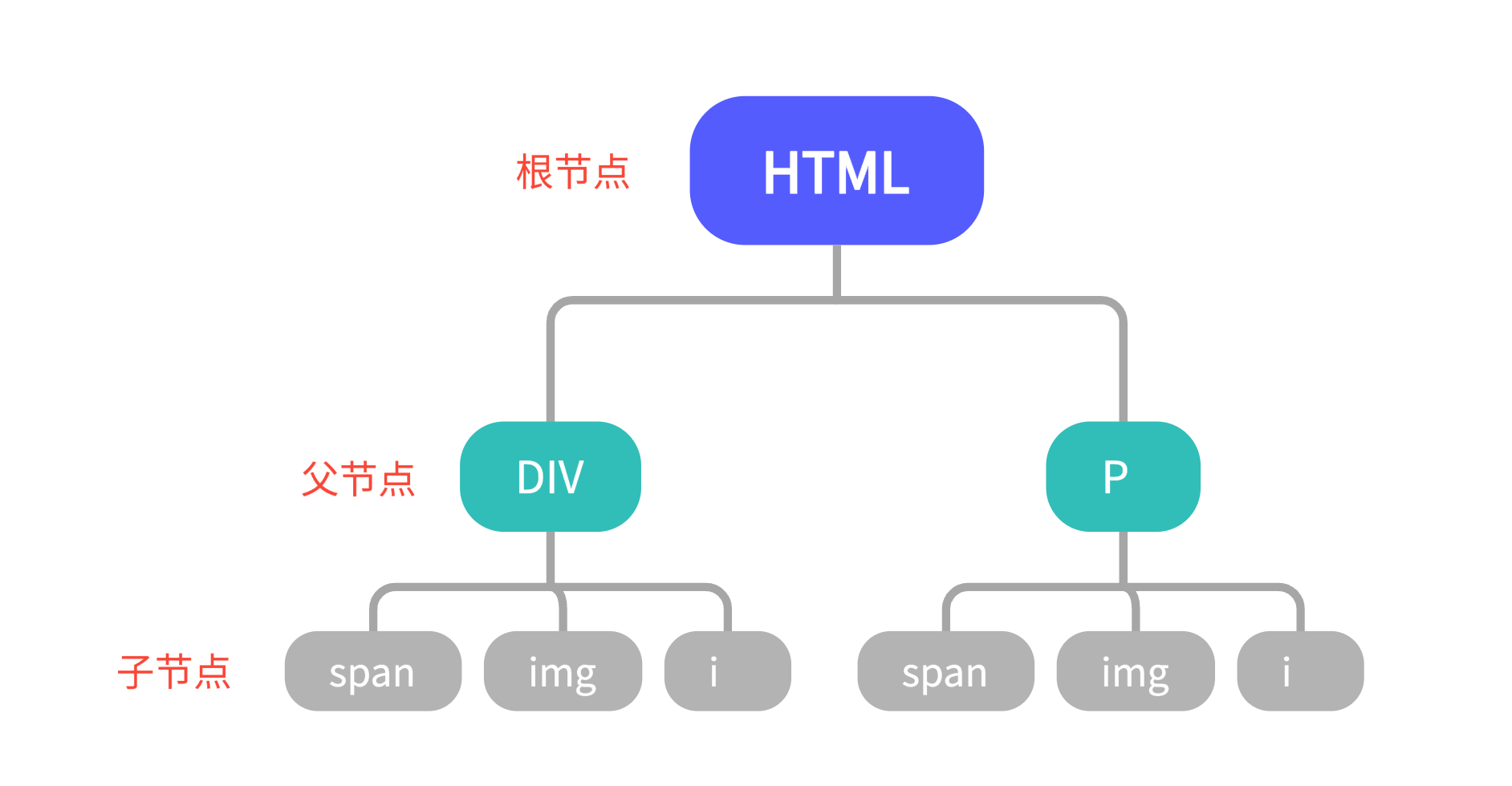
以上面的 HTML 节点树为例,节点之间包含了下列的关系:
- 父节点 (Parent): HTML 是 DIV 和 P 节点的父节点;
- 子节点 (Child):DIV 和 P 是 HTML 的子节点;
- 兄弟节点 (Sibling):拥有同样的一个父节点,DIV 和 P 就是兄弟节点。类似的 span、img 和 i 也是兄弟节点。
- 祖先节点 (Ancestor):html 是 span 的祖先节点,隔开一级;
- 后代节点 (Descendant):span 是 HTML 的后代节点,隔开一级。
除了了解这些概念,parent、sibling 等关键词也非常关键,在匹配复杂的结构时常常用到。
绝对和相对路径
xpath 中绝对路径使用 / 开始,比如:/html/body/div[1]/a/img,绝对路径较长,其中可能包含变化的部分,不建议单独使用绝对路径来选择元素,最好配合其它语法。
比如下面的情况单独使用绝对路径进行定位就会出错:
// 本意是匹配第三个div下的span,但因为第一个div因为是动态显隐的,导致匹配第而个div匹配到之前的第三个了 /html/body/div[2]/span 相对路径以 // 开始,比如 //*[@class],表示只要包含 class 属性的元素均可匹配,无论从哪一个节点开始。
下面是一些常见选择节点示例:
| 表达式 | 说明 | 举例 |
|---|---|---|
| / | 下一个节点,或者根节点开始 | /html/body/div |
| // | 从任意节点开始 | //img |
| . | 选取当前节点 | //a/. |
| .. | 当前节点的父节点 | //a/.. |
| @ | 选取包含某属性的元素 | //div[@class]或//@class |
| * | 表示任意元素或者任意属性 | //*[@class] |
除此之外,通过谷歌浏览器-元素上审查元素-复制 xpath,可以直接获取绝对路径和相对路径。
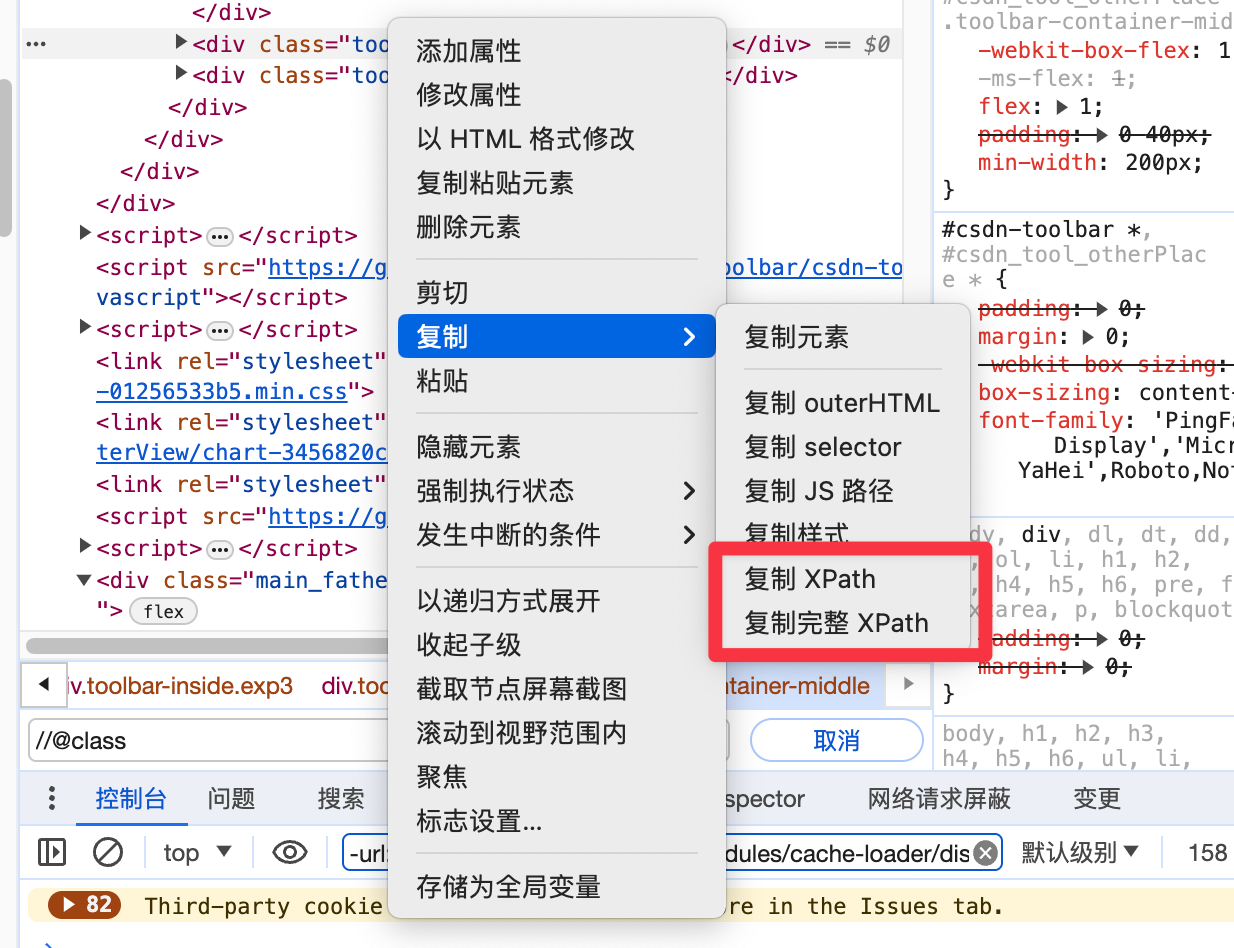
但复制下来的代码,通常还需要进行一些修改,才能具备通用性。
基础语法
定位需要的信息通常通过元素、属性名、属性值以及三者结合等方式进行。
下面来分别看一下,也这段 html 代码为例:
<div id="app"> <p class="title">喜欢的动物</p> <ul> <li class="cat">猫</li> <li class="dog">狗</li> <li id="panda">熊猫</li> </ul> <p class="title">喜欢的电影</p> <ul> <li>阿甘正传</li> <li>霸王别姬</li> <li>阿凡达</li> </ul> <p>其它不需要信息</p> </div> 1. 通过元素名定位
示例:
1.1 //div/p
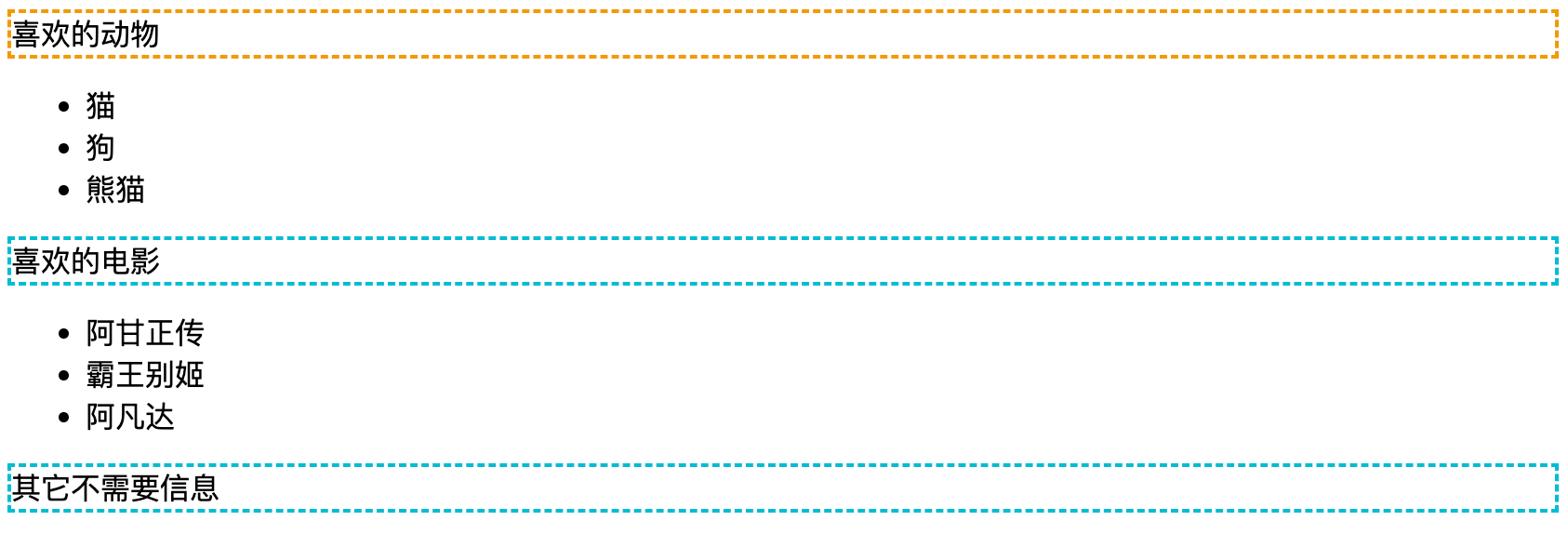
定位所有 div 下的 p 子元素,可以是任何 div,只要这个 div 的子节点包含 p 就可以匹配
1.2 //ul

会定位从任何节点开始的 ul 元素
1.3 /html/body/div/p

使用绝对路径定位元素,必须从 /html 开始,否则最好使用 // 相对路径开始
2. 通过属性名定位
通过元素是否包含某个属性来进行定位,属性名需要使用 @ 开始,同时放在 [] 内
2.1 //*[@class]
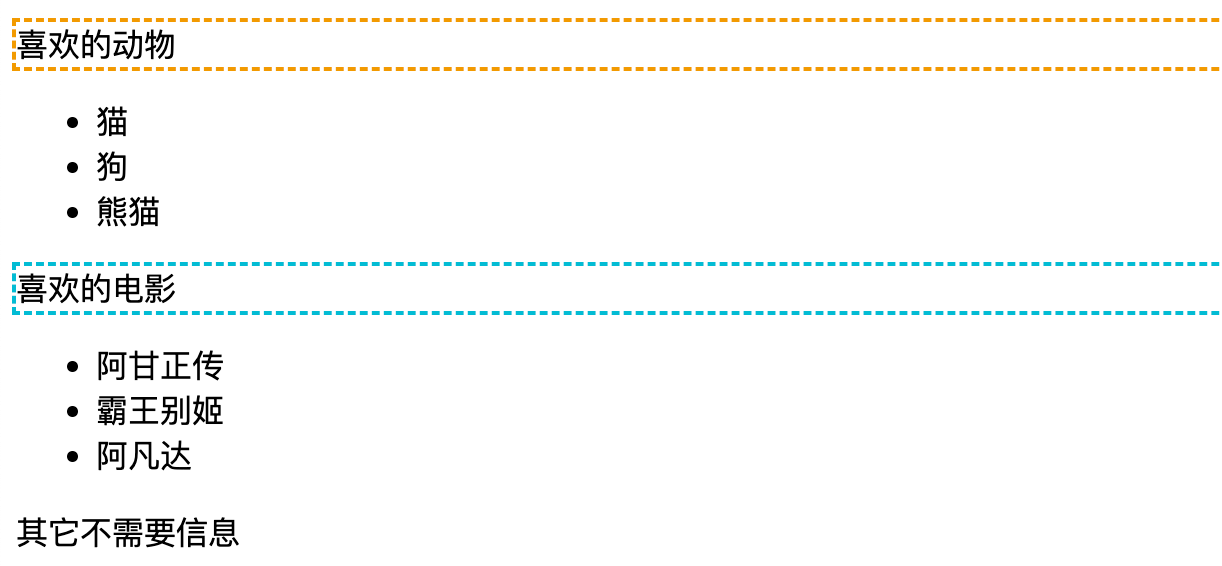
定位包含 class 属性的元素
2.2 //@class

这种语法定位到的是属性里面的具体值 title,而不是元素,所有没有元素没选中
3. 通过属性值定位
示例:
//li[@class="cat"]

定位包含 class 属性,值为 cat 的 li 属性元素
4. 使用逻辑运算符定位
常用逻辑运算符包括:and、or、not 三种
示例:
4.1 //li[@class and @class="cat"]

选中包含 class 属性,并且属性值为 cat 的 li 元素对象。
4.2 //li[@class or @id]

选中包含 class 或者 id 属性的 li 元素对象。
4.3 //li[not(@class)]
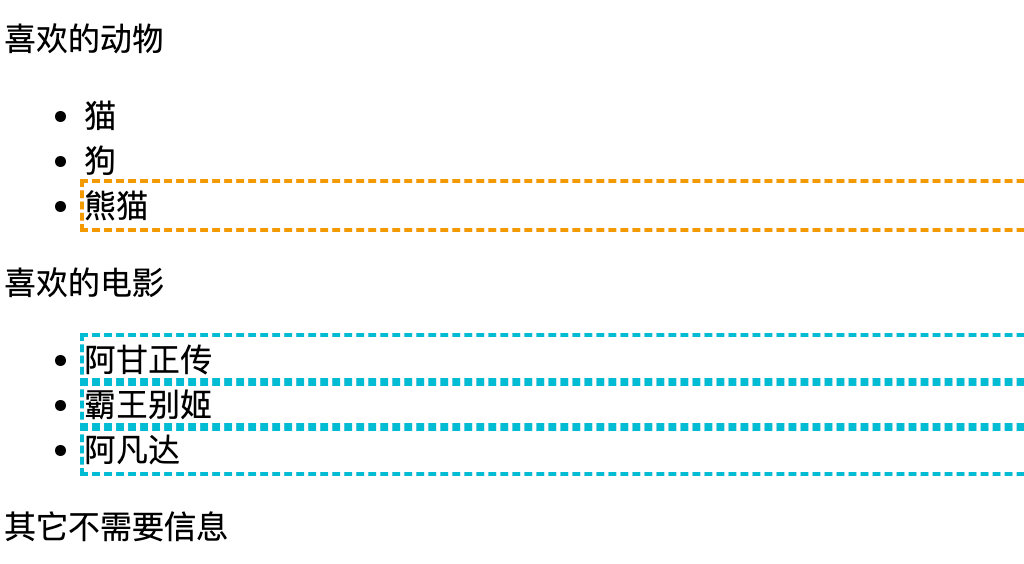
选中不包含 class 属性的 li 元素对象。
5. 使用谓语定位
5.1 //li[1]

定位任意元素下的第一个 li。
注意
xpath 中索引从 1 开始。
5.2 (//li)[1]

两者区别如下:
//li[1]任意元素下第一个li,也就是说这个 li 在任意的 ul 下是第一个就会被选中
(//li)[1]将所有的 li 选出来的结果数组中取第一个,这两者是完全不同的含义
6. 使用文本定位
使用元素中文本的内容进行定位。
示例:
6.1 //li[text()="猫"]

选中文本内容为 猫 的 li 元素对象。
6.2 //*[contains(text(),"喜欢")]

选中任意元素文本中包含 喜欢 两个字的元素,其中 * 表示所有元素是通配符,contains() 表示包含函数。
类似的有:starts-with 和 ends-with 函数,表示以什么字符开始和字符结尾的文本。
节点选择器
除了相对和绝对选择之外,下面这些选择器在处理较复杂的匹配场景可以发挥关键作用。
parent:::选中父级节点,/..也是选中父级,但是通常parent::用于写在[]里面作为条件来判断child:::选中子级节点,/也是选中子级,通常也是作为条件来使用preceding-sibling:::选中同一层级的前面所有兄弟节点following-sibling:::选中同一层级的后面所有兄弟节点ancestor:::选中祖先节点,包括父级以及更上层的节点descendant:::选中当前节点下面的所有节点,包括子级
举例:
//*[ancestor::div]

选中所有元素中,上级是 div 的元素,其实也就是选中了所有元素,来看看这个
//ancestor::div

只选中了一个元素。
两者的区别如下:
//*[ancestor::div]选中的*表示所有元素,这些元素条件是[ancestor::div]父级及以上有 div。
//ancestor::div选中的是作为别人父级及以上的 div,也就是选中的是 div,这个 div 的是别人的父级或者爷级等
两者是完全不同的概念
美团 APP 匹配示例
看了半天 HTML,我们来了解一下 APP 中的 XML,通常匹配 APP 比网页复杂太多,基本就那几个元素,而且属性名基本都一样,所以常用的手段还是使用各种条件来进行限制匹配,下面来看一个例子。
<android.view.View index="5" class="android.view.View" text="" checked="false" clickable="true"> <android.widget.TextView index="1" class="android.widget.TextView" text="象山酥院(湛江印象汇店)" checked="false"/> <android.widget.TextView index="2" class="android.widget.TextView" text="" checked="false" clickable="true"/> <android.view.View index="3" class="android.view.View" text="" checked="false"> <android.widget.TextView index="0" class="android.widget.TextView" text="5.0" checked="false" /> </android.view.View> <android.widget.TextView index="4" class="android.widget.TextView" text="周销量 872" checked="false" /> </android.view.View> <android.view.View index="5" class="android.view.View" text="" checked="false" clickable="true"> <android.widget.TextView index="1" class="android.widget.TextView" text="蜜雪冰城" checked="false"/> <android.widget.TextView index="2" class="android.widget.TextView" text="" checked="false" clickable="true"/> <android.view.View index="3" class="android.view.View" text="" checked="false"> <android.widget.TextView index="0" class="android.widget.TextView" text="5.0" checked="false"/> </android.view.View> <android.widget.TextView index="4" class="android.widget.TextView" text="周销量 2322" checked="false"/> </android.view.View> 上面代码为美团的城市列表页面的 UI XML 代码,其中每个元素都包含大量相同的属性和属性值,关键在于整个页面,任何地方基本就是 android.view.View 和 android.widget.TextView ,像匹配 HTML 那样元素显然行不通。
示例:获取两个商品的评分
//*[@text and ancestor::*/following-sibling::*[contains(@text, '周销量')]]
规则解释:获取任何包含 text 属性的元素,它的父级的的兄弟元素必须是一个 text 值中包含 "周销量"的元素。
我这里没有使用 [1][2][3] 来定位,是因为不同商品的属性很多时候不一样。
通常还是根据想要的元素的位置,以及相邻元素的特征来定位,首先找到独特的文本,比如上面的周销量是固定会出现的,还有 ¥ 符号也可以,这些都是位置和文本值固定的,找到这个的位置,再去定位需要的元素的位置。
工具推荐
- 谷歌浏览器-审查元素-
ctrl + f,可以直接输入 xpath 语句 - 谷歌浏览器-selectorshub 插件,文中使用的是这个插件




