- A+
eBPF 中实现内核态代码与用户态代码是可以实时通信的,这主要靠 BPF 映射 来实现。
BPF 映射 是内核空间的一段内存,以 键值对 的方式存储。内核态程序可以直接访问 BPF 映射,用户态需要通过系统调用才能访问这段地址。
BPF 映射有很多种类型,如下表所示。
| 类型 | 说明 |
|---|---|
| BPF_HASH | 哈希表 |
| BPF_ARRAY | 数组 |
| BPF_HISTOGRAM | 直方图 |
| BPF_STACK_TRACE | 跟踪栈 |
| BPF_PERF_ARRAY | 硬件性能数组 |
| BPF_PERCPU_HASH | 单CPU哈希表 |
| BPF_PERCPU_ARRAY | 单CPU数组 |
| BPF_LPM_TRIE | 最长前缀匹配映射 |
| BPF_PROG_ARRAY | 尾调用程序数组 |
| ... | ... |
本文列举了使用 eBPF + BCC 实现的多个工具源码,索引如下表。
| 工具名称 | 工具用途 | 工具使用的 MAP | 涉及的具体 MAP 用法 |
|---|---|---|---|
| killsnoop | 检测进程被 kill 时的状态 | BPF_HASH | 内核态传递数据 |
| filetop | 检测指定时间周期内读写文件的 top 列表 | BPF_HASH | 内核态向用户态传递数据 |
| usercheck | 检测当前进程执行的用户 | BPF_HASH | 用户态向内核态传递数据 |
| pidpersec | 检测周期内通过 fork 创建的进程总数 | BPF_ARRAY | 保存全局数据 |
| vfsreadlat | 周期性打印 vfs 文件读取操作耗时分布情况 | BPF_HISTOGRAM | 直方图统计 |
| stacksnoop | 打印内核某个函数执行时的调用栈信息 | BPF_STACK_TRACE | 内核函数跟踪栈 |
1 哈希表
哈希表与我们熟悉的 hash_map 实现和用法相似,都是由 key/value 组成,在 eBPF 程序中按需分配和释放。
我们来看几个应用了 BPF_HASH 的例子。
工具1 killsnoop
(改编自 Brendan Gregg 大神给出的源码)—— 用来检测进程被 kill 时的状态。
点击查看代码
from bcc import BPF from bcc.utils import printb from time import strftime # define BPF program bpf_text = """ #include <uapi/linux/ptrace.h> #include <linux/sched.h> struct val_t { u32 pid; int sig; int tpid; char comm[TASK_COMM_LEN]; }; struct data_t { u32 pid; int tpid; int sig; int ret; char comm[TASK_COMM_LEN]; }; // 定义 BPF_HASH 名称为 infotmp,key 类型为 u32,val 类型为 struct val_t BPF_HASH(infotmp, u32, struct val_t); BPF_PERF_OUTPUT(events); int syscall__kill(struct pt_regs *ctx, int tpid, int sig) { u64 pid_tgid = bpf_get_current_pid_tgid(); u32 pid = pid_tgid >> 32; u32 tid = (u32)pid_tgid; struct val_t val = {.pid = pid}; if (bpf_get_current_comm(&val.comm, sizeof(val.comm)) == 0) { val.tpid = tpid; val.sig = sig; infotmp.update(&tid, &val); // 根据 (key, val) 更新 BPF_HASH } return 0; }; int do_ret_sys_kill(struct pt_regs *ctx) { struct data_t data = {}; struct val_t *valp; u64 pid_tgid = bpf_get_current_pid_tgid(); u32 pid = pid_tgid >> 32; u32 tid = (u32)pid_tgid; valp = infotmp.lookup(&tid); // 根据 key 查找 BPF_HASH if (valp == 0) { // missed entry return 0; } bpf_probe_read_kernel(&data.comm, sizeof(data.comm), valp->comm); data.pid = pid; data.tpid = valp->tpid; data.ret = PT_REGS_RC(ctx); data.sig = valp->sig; events.perf_submit(ctx, &data, sizeof(data)); infotmp.delete(&tid); // 根据 key 删除 BPF_HASH 记录 return 0; } """ # initialize BPF b = BPF(text=bpf_text) kill_fnname = b.get_syscall_fnname("kill") b.attach_kprobe(event=kill_fnname, fn_name="syscall__kill") b.attach_kretprobe(event=kill_fnname, fn_name="do_ret_sys_kill") # header print("%-9s %-16s %-16s %-4s %-16s %s" % ("TIME", "PID", "COMM", "SIG", "TPID", "RESULT")) # process event def print_event(cpu, data, size): event = b["events"].event(data) printb(b"%-9s %-16d %-16s %-4d %-16d %d" % (strftime("%H:%M:%S").encode('ascii'), event.pid, event.comm, event.sig, event.tpid, event.ret)) # loop with callback to print_event b["events"].open_perf_buffer(print_event) while 1: try: b.perf_buffer_poll() except KeyboardInterrupt: exit() 这个例子给出了 BPF_HASH 在内核态不同函数事件阶段之间传递消息的基本使用方式。主要有几个关键点:
-
BPF_HASH(infotmp, u32, struct val_t):定义一个 BPF 哈希表,前三个参数分别为:哈希表名称,key 的类型,val 的类型; -
infotmp.update(&tid, &val):更新 (key, val); -
infotmp.lookup(&tid):查询 key 对应的 val; -
infotmp.delete(&tid):删除 (key, val);
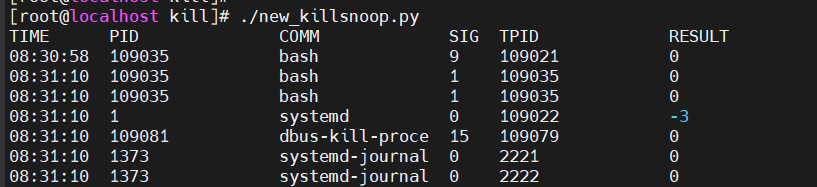
这段程序最终的运行结果如下。
工具2 filetop
(同样改编自 Brendan Gregg 的源码)—— 用来检测指定时间周期内读写文件的 top 列表。
点击查看代码
#!/usr/bin/python3 from bcc import BPF from time import sleep, strftime # define BPF program bpf_text = """ #include <uapi/linux/ptrace.h> #include <linux/blkdev.h> // the key for the output summary struct info_t { unsigned long inode; dev_t dev; dev_t rdev; u32 pid; u32 name_len; char comm[TASK_COMM_LEN]; // 进程名 // de->d_name.name may point to de->d_iname so limit len accordingly char name[DNAME_INLINE_LEN]; // 文件名 char type; }; // the value of the output summary struct val_t { u64 reads; u64 writes; u64 rbytes; u64 wbytes; }; BPF_HASH(counts, struct info_t, struct val_t); // 定义 HASH 表,key 和 val 均为一个结构体 static int do_entry(struct pt_regs *ctx, struct file *file, char __user *buf, size_t count, int is_read) { u32 tgid = bpf_get_current_pid_tgid() >> 32; u32 pid = bpf_get_current_pid_tgid(); // skip I/O lacking a filename struct dentry *de = file->f_path.dentry; int mode = file->f_inode->i_mode; struct qstr d_name = de->d_name; if (d_name.len == 0) return 0; // store counts and sizes by pid & file struct info_t info = { .pid = pid, .inode = file->f_inode->i_ino, .dev = file->f_inode->i_sb->s_dev, .rdev = file->f_inode->i_rdev, }; bpf_get_current_comm(&info.comm, sizeof(info.comm)); info.name_len = d_name.len; bpf_probe_read_kernel(&info.name, sizeof(info.name), d_name.name); // 区分操作的类型 if (S_ISREG(mode)) { info.type = 'R'; } else if (S_ISSOCK(mode)) { info.type = 'S'; } else { info.type = 'O'; } struct val_t *valp, zero = {}; valp = counts.lookup_or_try_init(&info, &zero); // 内核态尝试获取指定 key 的 val,若 val == NULL,则赋予一个默认值 if (valp) { if (is_read) { valp->reads++; valp->rbytes += count; } else { valp->writes++; valp->wbytes += count; } } return 0; } int trace_read_entry(struct pt_regs *ctx, struct file *file, char __user *buf, size_t count) { return do_entry(ctx, file, buf, count, 1); } int trace_write_entry(struct pt_regs *ctx, struct file *file, char __user *buf, size_t count) { return do_entry(ctx, file, buf, count, 0); } """ # initialize BPF b = BPF(text=bpf_text) b.attach_kprobe(event="vfs_read", fn_name="trace_read_entry") b.attach_kprobe(event="vfs_write", fn_name="trace_write_entry") # check whether hash table batch ops is supported htab_batch_ops = True if BPF.kernel_struct_has_field(b'bpf_map_ops', b'map_lookup_and_delete_batch') == 1 else False DNAME_INLINE_LEN = 32 # linux/dcache.h interval = 1 exiting = 0 def sort_fn(counts): return (counts[1].rbytes + counts[1].wbytes + counts[1].reads + counts[1].writes) while 1: try: sleep(interval) except KeyboardInterrupt: exit() print('Tracing... Output every %d secs. Hit Ctrl-C to end' % interval) print("%-7s %-16s %-6s %-6s %-7s %-7s %1s %s" % ("TID", "COMM", "READS", "WRITES", "R_Kb", "W_Kb", "T", "FILE")) # 用户态获取 BPF_HASH counts = b.get_table("counts") # 这里遍历整个 BPF_HASH for k, v in reversed(sorted(counts.items_lookup_and_delete_batch() if htab_batch_ops else counts.items(), key=sort_fn)): name = k.name.decode('utf-8', 'replace') if k.name_len > DNAME_INLINE_LEN: name = name[:-3] + "..." # print line print("%-7d %-16s %-6d %-6d %-7d %-7d %1s %s" % (k.pid, k.comm.decode('utf-8', 'replace'), v.reads, v.writes, v.rbytes / 1024, v.wbytes / 1024, k.type.decode('utf-8', 'replace'), name)) # 用户态清空 BPF_HASH if not htab_batch_ops: counts.clear() 这个例子给出了 BPF_HASH 用于内核态向用户态传递数据的场景。主要有以下几个关键点:
-
BPF_HASH(counts, struct info_t, struct val_t):本次声明的哈希表,key 和 val 均为一个结构体,这在实操上是常见的。不过要注意 eBPF 运行栈大小限制。 -
valp = counts.lookup_or_try_init(&info, &zero):内核态的查找辅助函数,和lookup()用法相同,不过此函数安全性更高。若获取的 val 为空,则为其赋予一个初始值zero。(注意,获取的 val 是一个指针,可以直接操作器结构体数据) -
counts = b.get_table("counts"):用于用户态获取定义的eBPF_HASH。 -
counts.items():返回所有的 (key, val),用于用户态遍历哈希表。 -
counts.clear():清空整张哈希表。 -
htab_batch_ops:这段代码定义了一个特殊的标志位,用来判断当前版本的eBPF是否支持items_lookup_and_delete_batch()辅助函数。 -
items_lookup_and_delete_batch():内核 5.6 版本才引入该函数。作用同items() + clear(),即,获取所有的 (key, val),并清空整个哈希表。
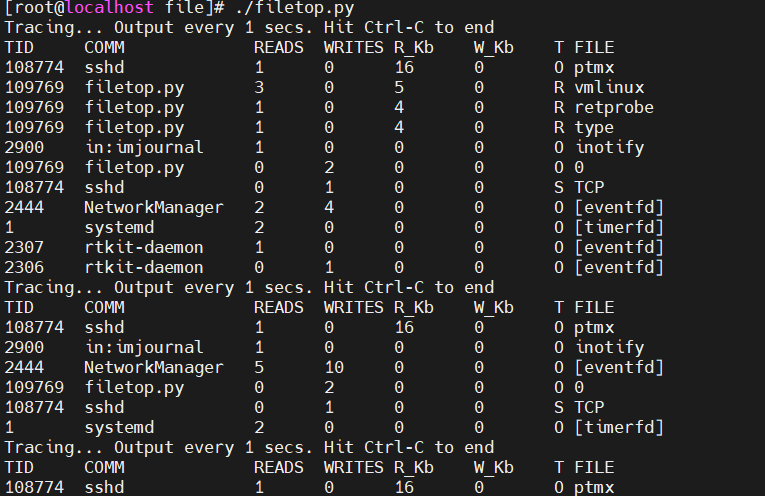
这段代码通过 interval 变量控制检测周期(当前为 1s),并按照这个周期,检测打印进程访问文件的一个热度表,按照字节降序排列。如下图所示:
工具3 usercheck
(改编自《Learning eBPF》一书第二章给给出的部分代码)——用来检测当前进程执行的用户。
点击查看代码
#!/usr/bin/python3 from bcc import BPF from ctypes import * bpf_text = ''' struct user_msg_t { char message[12]; }; BPF_HASH(config, u32, struct user_msg_t); BPF_PERF_OUTPUT(events); struct data_t { int pid; int uid; char command[16]; char message[12]; }; int check_user(void *ctx) { struct data_t data = {}; struct user_msg_t *p; char message[12] = "Hello World"; data.pid = bpf_get_current_pid_tgid() >> 32; data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF; bpf_get_current_comm(&data.command, sizeof(data.command)); p = config.lookup(&data.uid); if (p != 0) { bpf_probe_read_kernel(&data.message, sizeof(data.message), p->message); } else { bpf_probe_read_kernel(&data.message, sizeof(data.message), message); } events.perf_submit(ctx, &data, sizeof(data)); return 0; } ''' # initialize BPF b = BPF(text=bpf_text) execve_fnname = b.get_syscall_fnname("execve") b.attach_kprobe(event=execve_fnname, fn_name="check_user") # 用户态获取 HASH config = b.get_table("config") # 用户态修改 HASH config[c_int(0)] = create_string_buffer(b"Hello, Root!") config[c_int(1000)] = create_string_buffer(b"Hello, User 501!") print("%-10s %-10s %-16s %s" % ("PID", "UID", "COMM", "MSG")) def print_event(cpu, data, size): event = b["events"].event(data) print("%-10d %-10d %-16s %s" % (event.pid, event.uid, event.command.decode('utf-8'), event.message.decode('utf-8'))) b["events"].open_perf_buffer(print_event) while 1: try: b.perf_buffer_poll() except KeyboardInterrupt: exit() 这个例子给出了一个用户态主动修改 BPF_HASH 的情况。关键点:
config[c_int(0)] = create_string_buffer(b"Hello, Root!"):修改的方式与常规的 hash_map 类似,但是,key 和 val 的类型转换是必不可少的步骤。
python 到 C 的类型转换可以通过 ctypes 库来实现。可直接通过
pip3 install stypes安装。
注意:
用户态可以通过这种方式向内核态传入数据,但千万要慎之又慎用这种方式去控制内核 BPF 程序的执行流程。内核态无法阻塞等待用户态处理复杂逻辑后的响应(如创建另一个进程)。[引用-1]
举例来说,当这个程序不是在最初就设定了 BPF_HASH 的值,而是通过内核传出的用户 uid动态地去打开系统文件检索用户 username,那么这个工具将无法实现预期功能了。这是因为,在当前进程执行的 execve 挂载点,用户态并没有来得及执行下一个 open 进程,因此,其通过 lookup() 获得的 username 将始终为空。
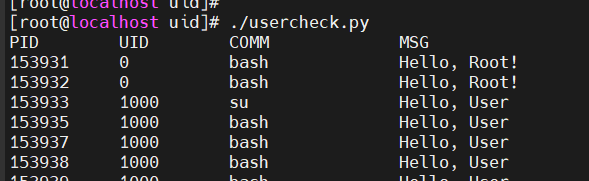
运行结果:
2 数组
工具4 pidpersec
(改编自 Brendan Gregg 给出的源码)—— 用于检测周期内通过 fork 创建的进程总数。
点击查看代码
#!/usr/bin/python3 from bcc import BPF from ctypes import c_int from time import sleep, strftime # load BPF program b = BPF(text=""" #include <uapi/linux/ptrace.h> enum stat_types { S_COUNT = 1, S_MAXSTAT }; BPF_ARRAY(stats, u64, S_MAXSTAT); // 创建 ARRAY,名称为 stats,val 的类型为 u64,val 的最大数量为 S_MAXSTAT = 2 static void stats_increment(int key) { stats.atomic_increment(key); // 索引为 key 的 val 原子自增操作 } void do_count(struct pt_regs *ctx) { stats_increment(S_COUNT); } """) b.attach_kprobe(event="sched_fork", fn_name="do_count") # stat indexes S_COUNT = c_int(1) interval = 1 # 打印周期 # header print("Tracing... Ctrl-C to end.") # output while (1): try: sleep(interval) except KeyboardInterrupt: exit() print("%s: PIDs/sec: %d" % (strftime("%H:%M:%S"), b["stats"][S_COUNT].value)) b["stats"].clear() 同为 BPF 映射类型,BPF_ARRAY 可以被看作为一类特殊的 BPF_HASH( ARRAY 的 key 从 0 开始,为非零整数),但有一下几点区别。
BPF_ARRAY在初始化时会预先分配空间,并设置为零。BPF_ARRAY的大小是固定的,其元素不能被删除。BPF_ARRAY通常用于保存 val 可能会更新的信息,由于 key 默认为非负整数索引,因此,其固定索引的 val 通常代表一个意义。BPF_ARRAY和BPF_HASH一样,在执行更新操作时,不能保证原子性。需要进行额外的手段来保证原子操作。
实际上, HASH 和 ARRAY 在初始化时,都有一个默认的最大
size(10240)。只不过在使用 ARRAY 时,通常会指定其最大size,以免预分配资源空间的浪费。
在此代码中,给出了一个 BPF_ARRAY 的常见用法,即,作为一个全局的计数器(跨用户态和内核态)。当然,若你问用 BPF_HASH 可不可以实现呢?答案自然是可以。数据结构并没有好坏之分,只有适合不适合之别。在此代码中:
-
BPF_ARRAY(stats, u64, S_MAXSTAT):定义一个数组,接受三个参数,分别为数组名,数组元素类型,数组大小。 -
stats.atomic_increment(key):由于修改数组元素时,不能保证原子性,因此这里需要手动调用辅助函数atomic_increment()为指定 key 的 val 做原子自增。
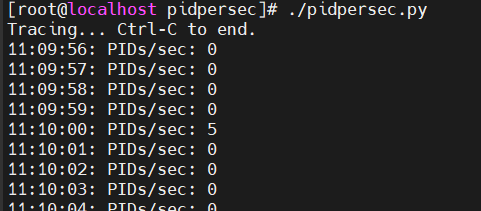
此工具运行截图。周期性打印 fork 出来的进程数量。
3 直方图
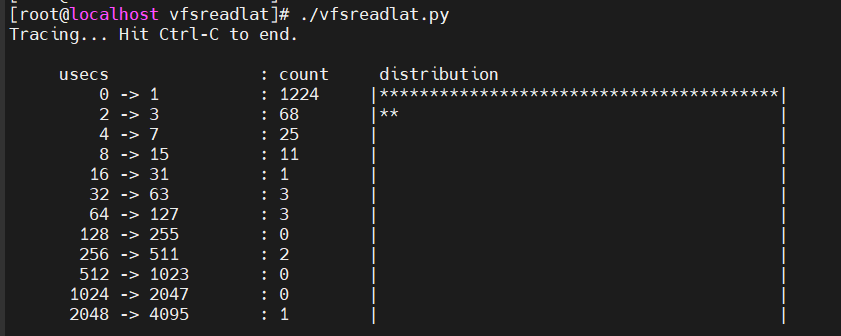
工具5 vfsreadlat
(改编自 Brendan Gregg 给出的源码)—— 用于周期性打印 vfs 文件读取操作耗时分布情况。
点击查看代码
from bcc import BPF from time import sleep bpf_src = ''' #include <uapi/linux/ptrace.h> BPF_HASH(start, u32); BPF_HISTOGRAM(dist); // 创建一个直方图映射,名称为 dist int do_entry(struct pt_regs *ctx) { u32 pid; u64 ts; pid = bpf_get_current_pid_tgid(); ts = bpf_ktime_get_ns(); start.update(&pid, &ts); return 0; } int do_return(struct pt_regs *ctx) { u32 pid; u64 *tsp, delta; pid = bpf_get_current_pid_tgid(); tsp = start.lookup(&pid); if (tsp != 0) { delta = bpf_ktime_get_ns() - *tsp; dist.increment(bpf_log2l(delta / 1000)); // 修改直方图数据,key 为 bpf_log2l(delta / 1000),即 千分之差值的 2 的对数 start.delete(&pid); } return 0; } ''' # load BPF program b = BPF(text = bpf_src) b.attach_kprobe(event="vfs_read", fn_name="do_entry") b.attach_kretprobe(event="vfs_read", fn_name="do_return") # header print("Tracing... Hit Ctrl-C to end.") interval = 5 count = -1 loop = 0 while (1): if count > 0: loop += 1 if loop > count: exit() try: sleep(interval) except KeyboardInterrupt: pass; exit() print() b["dist"].print_log2_hist("usecs") # 打印直方图 b["dist"].clear() 这个例子给出了一个新的 BPF_MAP 类型:直方图 BPF_HISTOGRAM。有以下几个关键:
-
BPF_HISTOGRAM(dist):创建了一个名为 dist 的直方图,默认值BPF_HISTOGRAM(name, key_type=int, size=64)。 -
dist.increment():直方图调用increment()将值自增,来进行统计。 -
bpf_log2l(delta / 1000):该函数返回log_2(delta/1000)的值。这样做是为了压缩直方图统计范围。 -
b["dist"].print_log2_hist("usecs"):指定统计列名称为usecs,打印直方图。
输出结果:
4 跟踪栈
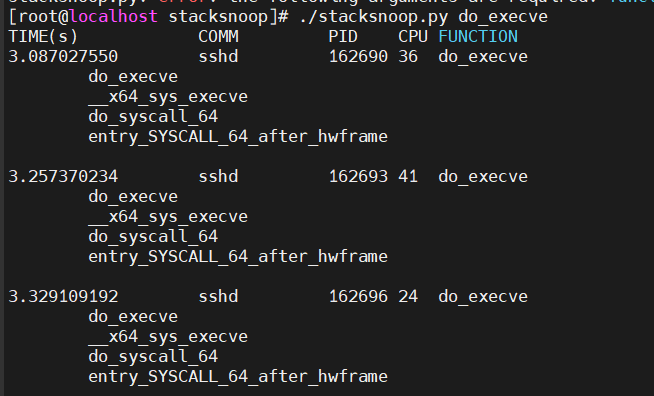
工具6 stacksnoop
(改编自 Brendan Gregg 给出的源码)—— 用于打印内核某个函数执行时的调用栈信息。
点击查看代码
from __future__ import print_function from bcc import BPF import argparse import time parser = argparse.ArgumentParser( description="Trace and print kernel stack traces for a kernel function", formatter_class=argparse.RawDescriptionHelpFormatter) parser.add_argument("function", help="kernel function name") function = parser.parse_args().function offset = False # define BPF program bpf_text = """ #include <uapi/linux/ptrace.h> #include <linux/sched.h> struct data_t { u64 stack_id; u32 pid; char comm[TASK_COMM_LEN]; }; BPF_STACK_TRACE(stack_traces, 128); // 定义跟踪栈 BPF_PERF_OUTPUT(events); void trace_stack(struct pt_regs *ctx) { u32 pid = bpf_get_current_pid_tgid() >> 32; struct data_t data = {}; data.stack_id = stack_traces.get_stackid(ctx, 0); 遍历通过 ctx 找到的堆栈,返回它的唯一 ID data.pid = pid; bpf_get_current_comm(&data.comm, sizeof(data.comm)); events.perf_submit(ctx, &data, sizeof(data)); } """ # initialize BPF b = BPF(text=bpf_text) b.attach_kprobe(event=function, fn_name="trace_stack") TASK_COMM_LEN = 16 # linux/sched.h matched = b.num_open_kprobes() # 判断输入的 function 是否合法 if matched == 0: print("Function "%s" not found. Exiting." % function) exit() stack_traces = b.get_table("stack_traces") # 获取跟踪栈 start_ts = time.time() # header print("%-18s %-12s %-6s %-3s %s" % ("TIME(s)", "COMM", "PID", "CPU", "FUNCTION")) def print_event(cpu, data, size): event = b["events"].event(data) ts = time.time() - start_ts print("%-18.9f %-12.12s %-6d %-3d %s" % (ts, event.comm.decode('utf-8', 'replace'), event.pid, cpu, function)) for addr in stack_traces.walk(event.stack_id): # 根据 stack.id 遍历堆栈 sym = b.ksym(addr, show_offset=offset).decode('utf-8', 'replace') # 将一个内核地址翻译成内核函数名 print("t%s" % sym) print() b["events"].open_perf_buffer(print_event) while 1: try: b.perf_buffer_poll() except KeyboardInterrupt: exit() 这个例子给出了 BPF_STACK_TRACE 跟踪栈的用法。关键在于:
-
BPF_STACK_TRACE(stack_traces, 128):定义一个跟踪栈,深度为 128。 -
stack_traces.get_stackid(ctx, 0):遍历通过 ctx 找到的堆栈,返回它的唯一 ID。 -
stack_traces = b.get_table("stack_traces"):用户态获取跟踪栈。 -
for addr in stack_traces.walk(event.stack_id):根据跟踪栈的唯一 id 遍历栈内元素,函数调用地址信息。拿到地址信息后,通过b.ksym()函数将其翻译为内核函数名。注意,b.ksym()函数 接收一个show_offset参数,用于控制是否显示偏移地址。 -
matched = b.num_open_kprobes():另外,这段程序最终接收一个参数,作为跟踪的内核函数名。因此需要判断其是否合法。num_open_kprobes()将返回能够匹配上的内核探针数量,这里被应用于检测输入的内核函数是否合法。
跟踪一个函数 do_execve,stacksnoop 运行效果如下:
总结
篇幅有限,本文先介绍这六个工具,主要涵盖了 BPF_HASH / BPF_ARRAY / BPF_HISTOGRAM / BPF_STACK_TRACE 这四种最常见的 BPF 映射 的使用方法。后面有精力的话,再补充 BPF 映射 的其他类型在 BCC 框架中的用法。
BCC 框架相关的中文材料目前不是很多,参考书也比较有限,本文涉及的源码大多改编自 Brendan Gregg 大神的开源项目,项目地址( https://github.com/iovisor/bcc )。感兴趣的朋友可以一起交流学习!




