- A+
前言
对`async/await`的支持已经存在了十多年。它的出现,改变了为 .NET 编写可伸缩代码的方式,你在不了解幕后的情况下也可以非常普遍地使用该功能。
从如下所示的同步方法开始(此方法是“同步的”,因为在整个操作完成并将控制权返回给调用方之前,调用方将无法执行任何其他操作):
// Synchronously copy all data from source to destination. public void CopyStreamToStream(Stream source, Stream destination) { var buffer = new byte[0x1000]; int numRead; while ((numRead = source.Read(buffer, 0, buffer.Length)) != 0) { destination.Write(buffer, 0, numRead); } }然后,你添加几个关键字,更改几个方法名称,最终得到以下异步方法(此方法是“异步的”,因为期望的控制权会非常快地返回给调用者,而且可能会在与整个操作相关的所有工作完成之前就返回。):
// Asynchronously copy all data from source to destination. public async Task CopyStreamToStreamAsync(Stream source, Stream destination) { var buffer = new byte[0x1000]; int numRead; while ((numRead = await source.ReadAsync(buffer, 0, buffer.Length)) != 0) { await destination.WriteAsync(buffer, 0, numRead); } }几乎在语法上相同,仍然能够利用所有相同的控制流构造,但现在是非阻塞的,具有显著不同的底层执行模型,并且由C#编译器和核心库在背后为你完成所有繁重的工作。
虽然在不知道底层发生了什么情况下使用类似这种的支持很常见,但我坚信了解它的实际工作原理有助于更好地使用它。特别是了解所涉及的机制很必要,比如在尝试调试出现错误或提高性能时特别有帮助。因此,在本文中,我们将深入探讨在语言、编译器和库级别上的确切工作原理,以便你能够充分利用这些有价值的功能。
要做到这一点,我们需要回到之前的时代,了解在没有它的情况下最先进的异步代码是什么样子的。警告,那不是很美观。
最初
在最初的.NET Framework 1.0中,就有了异步编程模型模式,也称为APM模式、模式或模式。在高层次上,该模式很简单。对于一个同步操作:
class Handler { public int DoStuff(string arg); }该模式将有两个相应的方法:方法和方法:
class Handler { public int DoStuff(string arg); public IAsyncResult BeginDoStuff(string arg, AsyncCallback? callback, object? state); public int EndDoStuff(IAsyncResult asyncResult); }方法会接受与相同的所有参数,但还会接受一个AsyncCallback委托和一个不透明对象,其中一个或两者都可以为。方法负责启动异步操作,并且如果提供了回调(通常称为初始操作的“继续”),则还要负责确保在异步操作完成时调用回调。
方法还将构造一个实现IAsyncResult的类型的实例,并使用可选来填充该的属性:
namespace System { public interface IAsyncResult { object? AsyncState { get; } WaitHandle AsyncWaitHandle { get; } bool IsCompleted { get; } bool CompletedSynchronously { get; } } public delegate void AsyncCallback(IAsyncResult ar); }然后,这个实例将从Begin方法返回,并在最终调用时传递给。当准备好使用操作结果时,调用者将该实例传递给End方法,该方法负责确保操作已完成(如果未完成,则通过阻塞同步等待它),然后返回操作的任何结果,包括传播可能发生的任何errors/exceptions。因此,无需编写如下代码来同步执行操作:
try { int i = handler.DoStuff(arg); Use(i); } catch (Exception e) { ... // handle exceptions from DoStuff and Use }可以按以下方式使用 Begin/End 方法,异步执行相同的操作:
try { handler.BeginDoStuff(arg, iar => { try { Handler handler = (Handler)iar.AsyncState!; int i = handler.EndDoStuff(iar); Use(i); } catch (Exception e2) { ... // handle exceptions from EndDoStuff and Use } }, handler); } catch (Exception e) { ... // handle exceptions thrown from the synchronous call to BeginDoStuff }对于使用任何语言的基于回调的API的人来说,这应该是熟悉的。
然而,事情只会因此变得更加复杂。例如,存在“堆栈潜水”的问题。当代码重复调用导致堆栈越来越来越深,可能出现堆栈溢出的风险。
如果操作同步完成,Begin方法可以同步调用回调函数,这意味着调用Begin的同时可能会直接调用回调函数。
而“异步”操作通常也会同步完成,这并不是因为它们保证异步完成,而是因为允许同步完成。
例如,考虑从某个网络操作(如从接收)中异步读取的情况。如果每个单独的操作只需要少量的数据(例如从响应中读取一些头数据),则可以设置缓冲区,以避免大量的系统调用开销。通过将数据读入缓冲区,然后从该缓冲区中消耗数据,直到该缓冲区耗尽,可以减少与socket实际交互所需的昂贵系统调用数量。这样的缓冲区可能存在于您正在使用的任何异步抽象后面,因此,您执行的第一个“异步”操作(填充缓冲区)是异步完成的,然后直到耗尽底层缓冲区之前的所有后续操作实际上都不需要执行任何I/O,而只是从缓冲区获取数据,因此所有操作都可以同步完成。当Begin方法执行其中一个这些操作并发现它同步完成时,它可以同步调用回调函数。这意味着你有一个调用Begin方法的堆栈帧,另一个堆栈帧用于Begin方法本身,以及用于回调函数的另一个堆栈帧。现在如果该回调函数再次调用Begin会发生什么?如果该操作同步完成且其回调同步调用,那么你现在又在堆栈上深入了几个帧。一直这样重复,直到最终堆栈溢出。
这是一个真正的可能性,很容易重现。在.NET Core上尝试运行这个程序:
using System.Net; using System.Net.Sockets; using Socket listener = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp); listener.Bind(new IPEndPoint(IPAddress.Loopback, 0)); listener.Listen(); using Socket client = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp); client.Connect(listener.LocalEndPoint!); using Socket server = listener.Accept(); _ = server.SendAsync(new byte[100_000]); var mres = new ManualResetEventSlim(); byte[] buffer = new byte[1]; var stream = new NetworkStream(client); void ReadAgain() { stream.BeginRead(buffer, 0, 1, iar => { if (stream.EndRead(iar) != 0) { ReadAgain(); // uh oh! } else { mres.Set(); } }, null); }; ReadAgain(); mres.Wait();这里我设置了一个简单的客户端socket和服务器socket相互连接。服务器向客户端发送100,000个字节,然后客户端继续使用以“异步”方式一次消耗它们(这是非常低效的,只是出于教学目的而这样做)。
传递给BeginRead的回调通过调用EndRead完成读取,然后如果成功读取所需的字节(在这种情况下它尚未到达流的末尾),则通过对ReadAgain本地函数的递归调用发出另一个BeginRead。
但是,在.NET Core中,socket操作比.NET Framework快得多,并且如果操作系统能够满足同步操作(注意内核本身具有用于满足socket接收操作的缓冲区),则会同步完成。因此,这个堆栈会溢出:

因此,建立了APM模型的补偿措施。有两种可能的补偿方法:
- 不允许同步调用。如果它始终异步调用回调,即使操作同步完成,也可以消除堆栈溢出的风险。但是这也会降低性能,因为同步完成(或太快以至于无法观察)的操作非常常见,强制每个操作将其回调排队会增加可测量的开销。
- 使用一种机制,如果操作同步完成,则允许调用者而不是回调执行后续工作。这样,你可以跳过(避免)额外的方法帧,并继续在堆栈上更深层次地进行后续工作。
APM模式采用选项(2)。为此,接口公开了两个相关但不同的成员:和。 告诉你操作是否已完成:你可以多次检查它,并最终将其从false转换为true,然后保持在那里。相比之下,从不改变(或者如果它改变了,那么它就是一个等待发生的严重bug);它用于在方法的调用者和之间通信,哪个负责执行任何继续工作。如果为false,则操作正在异步完成,并且对于操作完成后作出的任何继续工作应该留给回调来处理;毕竟,如果工作没有同步完成,则Begin的调用者无法真正处理它,因为操作尚未完成(如果调用者只是调用End,则会阻塞,直到操作完成)。然而,如果为true,则如果回调处理继续工作,则会冒着堆栈崩溃的风险,因为它将在比它开始的地方更深的堆栈上执行该继续工作。因此,任何实现都需要关注这种堆栈崩溃的情况,需要检查,并且如果它为true,则需要Begin方法的调用者执行继续工作,这意味着回调不需要执行继续工作。这也是为什么绝不能改变的原因:调用者和回调需要看到相同的值,以确保无论竞态条件如何,都只执行一次继续工作。
在我们之前的DoStuff示例中,这将导致以下代码:
try { IAsyncResult ar = handler.BeginDoStuff(arg, iar => { if (!iar.CompletedSynchronously) { try { Handler handler = (Handler)iar.AsyncState!; int i = handler.EndDoStuff(iar); Use(i); } catch (Exception e2) { ... // handle exceptions from EndDoStuff and Use } } }, handler); if (ar.CompletedSynchronously) { int i = handler.EndDoStuff(ar); Use(i); } } catch (Exception e) { ... // handle exceptions that emerge synchronously from BeginDoStuff and possibly EndDoStuff/Use }上面是一个冗长的表述。到目前为止,我们只看了如何使用该模式...我们还没有看如何实现该模式。虽然大多数开发人员不需要关心叶子操作(例如实现与操作系统实际交互方法),但大多数开发人员需要关注组合这些操作(执行多个异步操作,这些操作一起形成一个更大的操作),这意味着不仅要使用其他方法,还要自己实现它们,以便你的组合本身可以在其他地方使用。而且,你会注意到我的示例中没有控制流。如果将多个操作引入其中,特别是具有简单控制流(例如循环)的操作,那么瞬间这就成为专家的领域,他们享受痛苦,或者是博客文章作者试图表达一个观点。
因此,只是为了强调这一点,让我们实现一个完整的示例。在本文的开头,我展示了一个方法,该方法将所有数据从一个流复制到另一个流(类似于,但是为了说明而假设不存在它):
public void CopyStreamToStream(Stream source, Stream destination) { var buffer = new byte[0x1000]; int numRead; while ((numRead = source.Read(buffer, 0, buffer.Length)) != 0) { destination.Write(buffer, 0, numRead); } }直观来说,我们反复从一个流中读取数据,然后将结果数据写入另一个流,再从一个流中读取并写入另一个流,依此类推,直到没有更多数据可读取。那么,我们如何使用APM模式异步实现它呢?可以像这样实现:
public IAsyncResult BeginCopyStreamToStream( Stream source, Stream destination, AsyncCallback callback, object state) { var ar = new MyAsyncResult(state); var buffer = new byte[0x1000]; Action<IAsyncResult?> readWriteLoop = null!; readWriteLoop = iar => { try { for (bool isRead = iar == null; ; isRead = !isRead) { if (isRead) { iar = source.BeginRead(buffer, 0, buffer.Length, static readResult => { if (!readResult.CompletedSynchronously) { ((Action<IAsyncResult?>)readResult.AsyncState!)(readResult); } }, readWriteLoop); if (!iar.CompletedSynchronously) { return; } } else { int numRead = source.EndRead(iar!); if (numRead == 0) { ar.Complete(null); callback?.Invoke(ar); return; } iar = destination.BeginWrite(buffer, 0, numRead, writeResult => { if (!writeResult.CompletedSynchronously) { try { destination.EndWrite(writeResult); readWriteLoop(null); } catch (Exception e2) { ar.Complete(e); callback?.Invoke(ar); } } }, null); if (!iar.CompletedSynchronously) { return; } destination.EndWrite(iar); } } } catch (Exception e) { ar.Complete(e); callback?.Invoke(ar); } }; readWriteLoop(null); return ar; } public void EndCopyStreamToStream(IAsyncResult asyncResult) { if (asyncResult is not MyAsyncResult ar) { throw new ArgumentException(null, nameof(asyncResult)); } ar.Wait(); } private sealed class MyAsyncResult : IAsyncResult { private bool _completed; private int _completedSynchronously; private ManualResetEvent? _event; private Exception? _error; public MyAsyncResult(object? state) => AsyncState = state; public object? AsyncState { get; } public void Complete(Exception? error) { lock (this) { _completed = true; _error = error; _event?.Set(); } } public void Wait() { WaitHandle? h = null; lock (this) { if (_completed) { if (_error is not null) { throw _error; } return; } h = _event ??= new ManualResetEvent(false); } h.WaitOne(); if (_error is not null) { throw _error; } } public WaitHandle AsyncWaitHandle { get { lock (this) { return _event ??= new ManualResetEvent(_completed); } } } public bool CompletedSynchronously { get { lock (this) { if (_completedSynchronously == 0) { _completedSynchronously = _completed ? 1 : -1; } return _completedSynchronously == 1; } } } public bool IsCompleted { get { lock (this) { return _completed; } } } }哇哦,即使有了所有那些乱七八糟的东西,它仍然不是一个很好的实现。例如,实现对每个操作进行了锁定,而不是以更加无锁的方式进行,异常是原始存储的,而不是作为ExceptionDispatchInfo存储,这将使其在传播时增强其调用堆栈,每个单独操作都需要进行大量的分配(例如,为每个调用分配一个委托),等等。
现在,想象一下你必须为要编写的每个方法都做所有这些工作。每次你想编写一个可重用的方法来使用另一个异步操作时,你都需要做所有这些工作。如果你想编写可重用的组合器,可以有效地操作多个离散的 (类似于 Task.WhenAll),那就是另一层难度;每个操作实现和公开其自己的特定于该操作的 API 意味着没有共同语言可以以类似的方式谈论它们(尽管一些开发人员编写了试图通过另一层回调来减轻负担的库,这使得 API 可以向 Begin 方法提供适当的 )。
所有这些复杂性意味着很少有人尝试这样做,对于那些尝试的人来说,出现错误很常见。公平地说,这不是对APM模式的批评。相反,这是对基于回调的异步性的一种批评。
我们都习惯了现代语言中控制流构造提供给我们的强大和简单性,而基于回调的方法一旦引入任何合理的复杂性,通常会违反这种结构。其他主流语言也没有更好的替代方案。
我们需要一种更好的方式,一种从APM模式中学习、吸收其正确之处并避免其缺点的方式。有趣的是,APM模式只是一种模式;运行时、核心库和编译器没有提供任何帮助来使用或实现该模式。
基于事件的异步模式
.NET Framework 2.0 引入了一些 API,实现了用于处理异步操作的不同模式,其中一种主要用于在客户端应用程序的上下文中执行此操作。这种基于事件的异步模式(EAP)也作为一对成员(至少,可能更多)出现,这次是启动异步操作的方法和侦听其完成的事件。因此,我们前面的 示例可能会公开一组成员,如下所示:
class Handler { public int DoStuff(string arg); public void DoStuffAsync(string arg, object? userToken); public event DoStuffEventHandler? DoStuffCompleted; } public delegate void DoStuffEventHandler(object sender, DoStuffEventArgs e); public class DoStuffEventArgs : AsyncCompletedEventArgs { public DoStuffEventArgs(int result, Exception? error, bool canceled, object? userToken) : base(error, canceled, usertoken) => Result = result; public int Result { get; } }你可以使用 事件注册你的continuation工作,然后调用 方法; 它会启动操作,并且在该操作完成后,将从调用方异步触发 事件。然后,处理程序可以运行其continuation工作,可能验证提供的 是否与它预期的匹配,从而使多个处理程序能够同时挂接到事件。
这种模式使一些用例变得更容易一些,同时使其他用例变得更加困难(鉴于前面的APM 示例,这说明了一些事情)。它并没有被广泛地推广,它在.NET Framework的一个版本中有效地出现又消失,尽管在其任期内添加的API,如:
public class Ping : Component { public void SendAsync(string hostNameOrAddress, object? userToken); public event PingCompletedEventHandler? PingCompleted; ... }然而,它确实增加了一个值得注意的进步,APM模式根本没有考虑到这一点,并且这一进步一直延续到我们今天所采用的模型中:SynchronizationContext。
也是在.NET Framework 2.0中引入的,作为一个通用调度器的抽象。特别是,最常用的方法是,它将工作项排队到由该上下文表示的任何调度器。例如,的基本实现只表示ThreadPool,因此的基本实现只是委托给,该方法用于要求ThreadPool使用其中一个线程调用提供的回调,该回调具有池的一个线程上的关联状态。然而,的核心不仅仅是支持任意调度器,而是支持按照各种应用程序模型的需求进行调度的方式。
以Windows Forms这样的UI框架。与Windows上的大多数UI框架一样,控件与特定的线程相关联,并且该线程运行一个消息泵,该消息泵运行能够与这些控件交互的工作:只有该线程应该尝试操作这些控件,任何其他想要与控件交互的线程都应该通过发送消息来与UI线程的消息泵进行交互。Windows Forms通过等方法使这变得容易,该方法将提供的委托和参数排队,以由与该Control相关联的任何线程运行。因此,您可以编写以下代码:
private void button1_Click(object sender, EventArgs e) { ThreadPool.QueueUserWorkItem(_ => { string message = ComputeMessage(); button1.BeginInvoke(() => { button1.Text = message; }); }); }这将把的工作卸载到一个线程池线程上(以便在处理时保持UI的响应性),然后当这项工作完成时,将一个委托排队回到与button1关联的线程以更新button1的标签。这很容易。WPF也有类似的功能,只是使用了其类型:
private void button1_Click(object sender, RoutedEventArgs e) { ThreadPool.QueueUserWorkItem(_ => { string message = ComputeMessage(); button1.Dispatcher.InvokeAsync(() => { button1.Content = message; }); }); }.NET MAUI 也有类似的东西。但是,如果我想将此逻辑放入辅助方法中怎么办?例如
// Call ComputeMessage and then invoke the update action to update controls. internal static void ComputeMessageAndInvokeUpdate(Action<string> update) { ... }然后我可以像这样使用它:
private void button1_Click(object sender, EventArgs e) { ComputeMessageAndInvokeUpdate(message => button1.Text = message); }但是,如何实现,使其能够在任何这些应用程序中工作呢?它是否需要硬编码以了解每个可能的UI框架?这就是的优势所在。我们可以像这样实现该方法:
internal static void ComputeMessageAndInvokeUpdate(Action<string> update) { SynchronizationContext? sc = SynchronizationContext.Current; ThreadPool.QueueUserWorkItem(_ => { string message = ComputeMessage(); if (sc is not null) { sc.Post(_ => update(message), null); } else { update(message); } }); }它使用 作为抽象来定位任何应该使用的“调度程序”,以返回到与 UI 交互的必要环境。然后,每个应用程序模型都确保将其发布为 一个执行“正确操作”的 派生类型。比如, Windows Forms 中有WindowsFormsSynchronizationContext:
public sealed class WindowsFormsSynchronizationContext : SynchronizationContext, IDisposable { public override void Post(SendOrPostCallback d, object? state) => _controlToSendTo?.BeginInvoke(d, new object?[] { state }); ... }同理,WPF 中有DispatcherSynchronizationContext:
public sealed class DispatcherSynchronizationContext : SynchronizationContext { public override void Post(SendOrPostCallback d, Object state) => _dispatcher.BeginInvoke(_priority, d, state); ... }ASP.NET 曾经有一个AspNetSynchronizationContext,它实际上并不关心运行的线程是什么,而是将与给定请求关联的工作序列化,这样多个线程就不会同时访问给定的 :
internal sealed class AspNetSynchronizationContext : AspNetSynchronizationContextBase { public override void Post(SendOrPostCallback callback, Object state) => _state.Helper.QueueAsynchronous(() => callback(state)); ... }这也不限于此类主要应用程序模型。例如,xunit 是一种流行的单元测试框架,.NET 的核心存储库使用它进行单元测试,它还采用了多个自定义 。例如,您可以允许测试并行运行,但限制允许同时运行的测试数量。这是如何启用的?通过 :
public class MaxConcurrencySyncContext : SynchronizationContext, IDisposable { public override void Post(SendOrPostCallback d, object? state) { var context = ExecutionContext.Capture(); workQueue.Enqueue((d, state, context)); workReady.Set(); } }MaxConcurrencySyncContext 的“Post”方法只是将工作排队到它自己的内部工作队列中,然后在它自己的工作线程中处理它,其中根据所需的最大并发性控制线程数量。你懂的。
这与基于事件的异步模式有什么关联?
和同时引入,EAP规定完成事件应该排队到启动异步操作时为当前的任何位置。为了稍微简化它(可能不足以保证额外的复杂性),中还引入了一些帮助器类型,特别是和。前者只是一个元组,包装了用户提供的状态对象和捕获的,后者只是一个简单的工厂,用于捕获和创建实例。然后,EAP实现将使用它们,例如调用来捕获,然后当操作完成时,的方法将被调用以调用存储的的方法。
提供了一些值得一提的小玩意儿,因为它们稍后会再次出现。特别地,它公开了和方法。这些virtuals方法的基本实现为空,什么都不做,但派生的实现可能会覆盖这些方法以了解正在进行的操作。这意味着EAP实现也会在每个操作的开始和结束时调用这些方法,以通知任何当前的并允许它跟踪工作。这对EAP模式尤其重要,因为启动异步操作的方法都是void的无返回值:你没有任何返回值可以让你单独跟踪工作。我们会回到这个问题的。
所以,我们需要比APM模式更好的东西,随后出现的EAP引入了一些新东西,但并没有真正解决我们面临的核心问题。我们仍然需要更好的东西。
引入Task
.NET Framework 4.0引入了System.Threading.Tasks.Task类型。从本质上讲,Task只是代表某些异步操作最终完成的数据结构(其他框架称类似类型为“promise”或“future”)。创建Task来表示某个操作,当它所代表的操作逻辑上完成时,结果将存储在该Task中。这很简单。但是,Task提供的关键功能使它比IAsyncResult更加有用,它将连续性的概念内置到自身中。这个功能意味着您可以走到任何Task并要求在其完成时异步通知,而任务本身处理同步以确保无论任务是否已经完成,仍会调用连续性。完成,尚未完成或正在与通知请求并发完成。为什么这样具有影响力?好吧,如果您回想一下我们对旧APM模式的讨论,那么有两个主要问题。
- 您必须为每个操作实现自定义IAsyncResult实现:没有内置的IAsyncResult实现可以供任何人仅用于其需求。
- 在调用Begin方法之前,您必须知道完成时要做什么。这使得实现组合器和其他通用程序例程以消耗和组成任意异步实现成为一个重大挑战。
相比之下,使用Task,该共享表示允许您在已经启动操作之后走到异步操作并在已经启动操作之后提供连续性…您不需要将该连续性提供给启动操作的方法。每个具有异步操作的人都可以生成一个Task,每个消耗异步操作的人都可以消耗一个Task,并且不需要进行任何自定义操作即可将两者连接起来:Task成为促进异步操作的生产者和消费者交流的通用语言。这已经改变了.NET的面貌。稍后再说…
现在,让我们更好地了解这实际上意味着什么。我们不会深入研究Task的复杂代码,而是采用教学方法来实现一个简单版本。这不是要实现一个很好的实现,而只是足够完整的功能,以帮助理解Task的实质,最后,Task实际上只是处理协调完成信号的数据结构。我们将从只有几个字段开始:
class MyTask { private bool _completed; private Exception? _error; private Action<MyTask>? _continuation; private ExecutionContext? _ec; ... }我们需要一个字段来知道任务是否已完成(completed),我们需要一个字段来存储导致任务失败的任何错误(error);如果我们还实现了一个通用的MyTask<TResult>,则还会有一个用于存储操作成功结果的私有TResult result字段。到目前为止,这看起来很像我们之前自定义的IAsyncResult实现(当然不是巧合)。但现在是绝妙之作,continuation字段。在这个简单的实现中,我们仅支持单个连续性,但这足以解释目的(真正的Task采用一个对象字段,该对象字段可以是单个连续性对象或连续性对象列表)。这是将在任务完成时调用的委托。
现在,一些表面积。如上所述,Task相对于先前的模型的一个基本进步是能够在启动操作之后提供连续性工作(回调)。我们需要一个方法来允许我们这样做,因此让我们添加ContinueWith:
public void ContinueWith(Action<MyTask> action) { lock (this) { if (_completed) { ThreadPool.QueueUserWorkItem(_ => action(this)); } else if (_continuation is not null) { throw new InvalidOperationException("Unlike Task, this implementation only supports a single continuation."); } else { _continuation = action; _ec = ExecutionContext.Capture(); } } }如果任务在调用ContinueWith时已经被标记为已完成,则ContinueWith仅排队执行委托。否则,该方法将存储委托,以便在任务完成时可以排队执行延续(它还存储了称为ExecutionContext的东西,然后在稍后调用委托时使用它,但现在不用担心这部分…我们会讲到的)。足够简单。
然后,我们需要能够标记MyTask已完成,这意味着它表示的任何异步操作已经完成。为此,我们将公开两种方法,一种用于成功标记完成(“SetResult”),一种用于使用错误标记完成(“SetException”):
public void SetResult() => Complete(null); public void SetException(Exception error) => Complete(error); private void Complete(Exception? error) { lock (this) { if (_completed) { throw new InvalidOperationException("Already completed"); } _error = error; _completed = true; if (_continuation is not null) { ThreadPool.QueueUserWorkItem(_ => { if (_ec is not null) { ExecutionContext.Run(_ec, _ => _continuation(this), null); } else { _continuation(this); } }); } } }我们存储任何错误,标记任务已完成,然后如果先前已注册延续,我们将排队执行它。
最后,我们需要一种方法来传播可能在任务中发生的任何异常(如果这是一个通用的MyTask<T>,则返回它的_result);为了促进某些情况,我们还允许此方法阻塞等待任务完成,我们可以使用ContinueWith来实现(延续只是信号ManualResetEventSlim,然后调用者阻塞等待完成)。
public void Wait() { ManualResetEventSlim? mres = null; lock (this) { if (!_completed) { mres = new ManualResetEventSlim(); ContinueWith(_ => mres.Set()); } } mres?.Wait(); if (_error is not null) { ExceptionDispatchInfo.Throw(_error); } }基本上就是这样了。当然,真正的任务要复杂得多,需要更高效的实现,支持任意数量的连续操作,有许多关于它应该如何行为的开关(例如,连续操作是否应该按照当前所做的方式进行排队,还是作为任务完成的一部分同步调用),可以存储多个异常而不仅仅是一个,具有特殊的取消知识,有大量的帮助方法来执行常见操作(例如,Task.Run 可以创建一个代表排队在线程池上调用的委托的任务),等等。但是,这其中并没有什么神奇的东西;从本质上讲,它就是我们在这里看到的。
您可能还注意到,我的简单 MyTask 直接在其上公开了 SetResult/SetException 方法,而 Task 没有。实际上,Task 确实有这样的方法,只不过它们是内部方法,一个名为 System.Threading.Tasks.TaskCompletionSource 的类型作为任务及其完成的单独“生产者”,这样做不是出于技术必要性,而是为了将完成方法保留在仅用于消费的地方之外。然后,您可以分发一个任务而不必担心它在您之下被完成;完成信号是创建任务的任何内容的实现细节,并且通过保留 TaskCompletionSource 可以保留自己完成它的权利。(CancellationToken 和 CancellationTokenSource 遵循类似的模式:CancellationToken 只是一个结构体包装器,用于 CancellationTokenSource,提供与消费取消信号相关的公共表面区域,但没有生成信号的能力,这是一个仅限于拥有 CancellationTokenSource 访问权限的能力。)
当然,我们可以为这个 MyTask 实现类似于 Task 提供的组合器和帮助程序。想要一个简单的 MyTask.WhenAll 吗?请看:
public static MyTask WhenAll(MyTask t1, MyTask t2) { var t = new MyTask(); int remaining = 2; Exception? e = null; Action<MyTask> continuation = completed => { e ??= completed._error; // just store a single exception for simplicity if (Interlocked.Decrement(ref remaining) == 0) { if (e is not null) t.SetException(e); else t.SetResult(); } }; t1.ContinueWith(continuation); t2.ContinueWith(continuation); return t; }想要使用 MyTask.Run ?没问题:
public static MyTask Run(Action action) { var t = new MyTask(); ThreadPool.QueueUserWorkItem(_ => { try { action(); t.SetResult(); } catch (Exception e) { t.SetException(e); } }); return t; }那么MyTask.Delay 呢?当然:
public static MyTask Delay(TimeSpan delay) { var t = new MyTask(); var timer = new Timer(_ => t.SetResult()); timer.Change(delay, Timeout.InfiniteTimeSpan); return t; }你懂的。
有了Task,以前在.NET中使用的所有异步模式都成为了过去式。任何先前使用APM模式或EAP模式实现异步的地方,都会有新的返回Task的方法。
ValueTask
Task仍然是.NET异步操作的主力,每个版本都会公开新的方法,而且在生态系统中通常会返回Task和Task<TResult>。然而,Task是一个类,这意味着创建它会产生分配。就大多数情况而言,为长期异步操作多分配一个对象是微不足道的,对于除了最注重性能的操作之外的其他操作,这不会对性能产生实质性的影响。然而,正如之前所述,同步完成异步操作是相当常见的。Stream.ReadAsync被引入以返回Task<int>,但是如果你从BufferedStream中读取,由于只需要从内存缓冲区中提取数据而不是执行系统调用和真正的I/O,有很大可能许多读取将会同步完成。需要额外分配一个对象来返回这样的数据是不幸的(请注意,这在APM中也是如此)。对于返回非泛型Task的方法,该方法可以返回一个已完成的单例任务,实际上Task已经提供了一个这样的单例,即Task.CompletedTask。但是对于Task<TResult>,不可能为每个可能的TResult缓存一个Task。我们能做些什么来使这样的同步完成更快呢?
有可能缓存一些Task<TResult>。例如,Task<bool>非常常见,而且只有两个有意义的缓存:当结果为true时缓存一个Task<bool>,当结果为false时缓存一个Task<bool>。或者,虽然我们不希望尝试缓存40亿个Task<int>以适应每个可能的Int32结果,但是小的Int32值非常常见,因此我们可以为-1到8之间的几个值缓存一些。对于任意类型,缺省值是一个相当常见的值,因此我们可以为每个相关类型的Result为default(TResult)的Task<TResult>缓存一个。事实上,Task.FromResult在今天(截至最近的.NET版本)就是这样做的,使用这样一些可重复使用的Task<TResult>单例的小缓存,并在适当时返回其中之一,否则为提供的确切结果值分配一个新的Task<TResult>。还可以创建其他方案来处理其他相当常见的情况。例如,在使用Stream.ReadAsync时,通常会多次调用它来读取相同数量的字节。而且通常情况下,实现可以完全满足该计数请求。这意味着Stream.ReadAsync反复返回相同的int结果值是很常见的。为了避免在这种情况下进行多次分配,多个Stream类型(如MemoryStream)将缓存它们成功返回的最后一个Task<int>,如果下一次读取也以相同的结果成功地完成,则可以再次返回相同的Task<int>,而不是创建一个新的。但是其他情况呢?在性能开销真正重要的情况下,如何更普遍地避免同步完成的分配?
这就是ValueTask<TResult>的作用(ValueTask<TResult>的详细说明也可用)。ValueTask<TResult>最初是一个TResult和Task<TResult>的联合体。最终,忽略所有的花哨功能,这就是它的全部(或者更确切地说,曾经是的),即立即结果或将来某个时刻的结果承诺:
public readonly struct ValueTask<TResult> { private readonly Task<TResult>? _task; private readonly TResult _result; ... }一种方法可以返回ValueTask<TResult>而不是Task<TResult>,通过较大的返回类型和更多的间接性,避免了TResult在需要返回时已经被知道的Task<TResult>分配。
然而,在某些超级极端的高性能场景中,您希望即使在异步完成情况下也能避免Task<TResult>的分配。例如,Socket位于网络堆栈的底部,而socket上的SendAsync和ReceiveAsync是许多服务的超级热点,同步和异步完成都非常常见(大多数发送同步完成,由于数据已经被缓冲在内核中,因此许多接收同步完成)。如果在给定的Socket上,我们可以使这样的发送和接收免费分配,无论操作是同步完成还是异步完成,那将是多么美好啊!
这就是System.Threading.Tasks.Sources.IValueTaskSource<TResult>进入图片的地方:
public interface IValueTaskSource<out TResult> { ValueTaskSourceStatus GetStatus(short token); void OnCompleted(Action<object?> continuation, object? state, short token, ValueTaskSourceOnCompletedFlags flags); TResult GetResult(short token); }IValueTaskSource<TResult>接口允许实现为ValueTask<TResult>提供自己的后备对象,使对象能够实现诸如GetResult之类的方法以检索操作的结果,以及OnCompleted以连接操作的延续。因此,ValueTask<TResult>对其定义进行了小型更改,其Task<TResult>? _task字段被对象? _obj字段替换:
public readonly struct ValueTask<TResult> { private readonly object? _obj; private readonly TResult _result; ... }而 task 字段原来是 Task<TResult> 或 null,obj 字段现在也可以是 IValueTaskSource<TResult>。一旦 Task<TResult> 被标记为已完成,它将一直保持已完成状态,并且永远不会转换回未完成状态。相比之下,实现 IValueTaskSource<TResult> 接口的对象具有完全控制实现的能力,并且可以自由地在完成和未完成状态之间双向转换,因为 ValueTask<TResult> 的约定是给定实例只能被使用一次,因此按构造方式来看,在底层实例被消费后不应该观察到后续更改(这就是为什么存在 CA2012 等分析规则)。这使得像 Socket 这样的类型可以池化 IValueTaskSource<TResult> 实例以用于重复调用。Socket 最多缓存两个这样的实例,一个用于读取,一个用于写入,因为 99.999% 的情况下,同时最多只有一个接收和一个发送处于进行中。
我提到了 ValueTask<TResult>,但没有提到 ValueTask。仅在避免同步完成的情况下避免分配时,非泛型 ValueTask(表示无结果、void 操作)几乎没有性能好处,因为相同的条件可以用 Task.CompletedTask 表示。但是,一旦我们关心使用可池化的底层对象来避免在异步完成情况下分配,那对于非泛型也很重要。因此,当引入 IValueTaskSource<TResult> 时,也引入了 IValueTaskSource 和 ValueTask。
因此,我们拥有 Task、Task<TResult>、ValueTask 和 ValueTask<TResult>。我们能够以各种方式与它们交互,表示任意异步操作,并连接连续项以处理这些异步操作的完成。是的,我们可以在操作完成之前或之后这样做。
但是……这些连续项仍然是回调!
我们仍然被迫采用连续传递样式来编码我们的异步控制流!!
仍然很难搞定!!!
我们该如何解决这个问题?
C# 迭代器来解救
实际上,解决方案的曙光出现在 Task 之前的几年,也就是 C# 2.0 加入迭代器支持时。
“迭代器?”你问道:“你是说 IEnumerable<T> 的迭代器吗?”没错。迭代器允许您编写一个单一的方法,然后由编译器使用该方法实现 IEnumerable<T> 和/或 IEnumerator<T>。例如,如果我想创建一个可枚举的序列,该序列产生斐波那契数列,我可能会编写类似于这样的代码:
public static IEnumerable<int> Fib() { int prev = 0, next = 1; yield return prev; yield return next; while (true) { int sum = prev + next; yield return sum; prev = next; next = sum; } }然后我可以用 foreach 枚举它:
foreach (int i in Fib()) { if (i > 100) break; Console.Write($"{i} "); }我可以通过 System.Linq.Enumerable 上的组合器将它与其他 IEnumerable<T> 组合起来:
foreach (int i in Fib().Take(12)) { Console.Write($"{i} "); }或者我可以直接通过 IEnumerator<T> 手动枚举它:
using IEnumerator<int> e = Fib().GetEnumerator(); while (e.MoveNext()) { int i = e.Current; if (i > 100) break; Console.Write($"{i} "); }以上所有结果都会产生此输出:
0 1 1 2 3 5 8 13 21 34 55 89
有趣的是,为了实现上述目的,我们需要能够多次进入和退出Fib方法。我们调用MoveNext方法,它进入方法,然后方法执行直到遇到yield return。此时,对MoveNext的调用需要返回true和返回yield值。然后我们再次调用MoveNext,我们需要能够在上一次离开的位置之后立即在Fib中恢复,并使用上一次调用的所有状态。迭代器实际上是由C#语言/编译器提供的协同程序,编译器将我的Fib迭代器扩展为完整的状态机:
public static IEnumerable<int> Fib() => new <Fib>d__0(-2); [CompilerGenerated] private sealed class <Fib>d__0 : IEnumerable<int>, IEnumerable, IEnumerator<int>, IEnumerator, IDisposable { private int <>1__state; private int <>2__current; private int <>l__initialThreadId; private int <prev>5__2; private int <next>5__3; private int <sum>5__4; int IEnumerator<int>.Current => <>2__current; object IEnumerator.Current => <>2__current; public <Fib>d__0(int <>1__state) { this.<>1__state = <>1__state; <>l__initialThreadId = Environment.CurrentManagedThreadId; } private bool MoveNext() { switch (<>1__state) { default: return false; case 0: <>1__state = -1; <prev>5__2 = 0; <next>5__3 = 1; <>2__current = <prev>5__2; <>1__state = 1; return true; case 1: <>1__state = -1; <>2__current = <next>5__3; <>1__state = 2; return true; case 2: <>1__state = -1; break; case 3: <>1__state = -1; <prev>5__2 = <next>5__3; <next>5__3 = <sum>5__4; break; } <sum>5__4 = <prev>5__2 + <next>5__3; <>2__current = <sum>5__4; <>1__state = 3; return true; } IEnumerator<int> IEnumerable<int>.GetEnumerator() { if (<>1__state == -2 && <>l__initialThreadId == Environment.CurrentManagedThreadId) { <>1__state = 0; return this; } return new <Fib>d__0(0); } IEnumerator IEnumerable.GetEnumerator() => ((IEnumerable<int>)this).GetEnumerator(); void IEnumerator.Reset() => throw new NotSupportedException(); void IDisposable.Dispose() { } }现在,Fib的所有逻辑都在MoveNext方法中,但作为跳转表的一部分,它可以使实现分支到它上次停止的位置,该位置在枚举器类型的生成状态字段中跟踪。我编写的本地变量,例如prev、next和sum,已经被“提升”为枚举器上的字段,以便它们可以在MoveNext的调用之间持久存在。
(请注意,之前显示C#编译器如何发出实现的代码片段不会直接编译。C#编译器合成“不可言喻”的名称,这意味着它在创建类型和成员时使用一种有效的IL但无效的C#方式命名,以免冲突任何用户命名的类型和成员。我将所有名称都保留为编译器的名称,但如果您想尝试编译它,可以将名称重命名为使用有效的C#名称。)
在我的上一个示例中,我展示了最后一种枚举的形式涉及手动使用IEnumerator<T>。在这个级别上,我们手动调用MoveNext(),决定何时重新进入协程。但是...如果我可以让下一个MoveNext的调用实际上是异步操作完成时执行的续体工作的一部分呢?如果我可以yield return某些表示异步操作的内容,并且让消费代码将续体连接到该yielded对象上,然后该续体执行MoveNext呢?通过这种方法,我可以编写一个助手方法,例如:
static Task IterateAsync(IEnumerable<Task> tasks) { var tcs = new TaskCompletionSource(); IEnumerator<Task> e = tasks.GetEnumerator(); void Process() { try { if (e.MoveNext()) { e.Current.ContinueWith(t => Process()); return; } } catch (Exception e) { tcs.SetException(e); return; } tcs.SetResult(); }; Process(); return tcs.Task; }现在这变得更有趣了。我们被赋予了一组任务,我们可以遍历这些任务。每次我们将MoveNext移到下一个任务并获取一个任务时,我们就会为该任务连接一个继续操作;当该任务完成时,它将返回到执行MoveNext的相同逻辑,获取下一个任务,以此类推。这是建立在任务作为任何异步操作的单个表示的思想基础上的,因此我们接收到的可枚举对象可以是任何异步操作的序列。这样的序列可能来自于迭代器。还记得之前我们的CopyStreamToStream示例吗?那个基于APM的实现非常糟糕。相比之下,可以考虑下面的实现:
static Task CopyStreamToStreamAsync(Stream source, Stream destination) { return IterateAsync(Impl(source, destination)); static IEnumerable<Task> Impl(Stream source, Stream destination) { var buffer = new byte[0x1000]; while (true) { Task<int> read = source.ReadAsync(buffer, 0, buffer.Length); yield return read; int numRead = read.Result; if (numRead <= 0) { break; } Task write = destination.WriteAsync(buffer, 0, numRead); yield return write; write.Wait(); } } }哇,这几乎是可读的。我们正在调用IterateAsync助手,我们正在向其提供的可枚举对象是由一个迭代器产生的,该迭代器处理了整个复制的控制流。它调用Stream.ReadAsync,然后yield返回那个任务;当IterateAsync调用MoveNext并交出这个任务时,那个任务就会被挂起,当它完成时,将会调用回MoveNext,并回到yield后面的迭代器。此时,Impl逻辑会获取方法的结果,调用WriteAsync,并再次yield它生成的任务。以此类推。
这,朋友们,就是C#和.NET中异步/等待的开始。在C#编译器中,支持迭代器和异步/等待的逻辑约95%是共享的。不同的语法,涉及不同的类型,但基本上是相同的转换。看一下yield返回,你几乎可以看到它们的代替物await。
事实上,在异步/等待出现之前,一些有远见的开发人员就已经将迭代器用于此类异步编程。类似的转换在实验性的Axum编程语言中进行了原型设计,成为C#异步支持的关键灵感。Axum提供了一个可以放在方法上的async关键字,就像现在C#中的async一样。Task还不是普遍存在的,因此在异步方法中,Axum编译器启发式地将同步方法调用匹配到它们的APM对应方法,例如,如果它发现您调用stream.Read,则会查找并使用相应的stream.BeginRead和stream.EndRead方法,合成适当的委托传递给开始方法,同时还为正在定义的异步方法生成完整的APM实现,使其具有组合性。它甚至与SynchronizationContext集成!虽然Axum最终被搁置了,但它作为C#中异步/等待的原型提供了一个令人敬畏和激励的样例。
await的背后
现在我们知道我们是如何到达这里的,让我们深入了解它的实际工作原理。为了参考,这里再次放出我们的同步方法示例:
public void CopyStreamToStream(Stream source, Stream destination) { var buffer = new byte[0x1000]; int numRead; while ((numRead = source.Read(buffer, 0, buffer.Length)) != 0) { destination.Write(buffer, 0, numRead); } }下面是使用 async/await 的相应方法的样子:
public async Task CopyStreamToStreamAsync(Stream source, Stream destination) { var buffer = new byte[0x1000]; int numRead; while ((numRead = await source.ReadAsync(buffer, 0, buffer.Length)) != 0) { await destination.WriteAsync(buffer, 0, numRead); } }相比我们迄今为止看到的所有内容,这是一股新鲜的空气。签名从void更改为async Task,我们分别调用ReadAsync和WriteAsync而不是Read和Write,并且这两个操作都带有await前缀。就是这样。编译器和核心库接管了其余部分,从根本上改变了代码实际执行的方式。让我们深入了解一下。
编译器转换
正如我们已经看到的,与迭代器一样,编译器将异步方法重写为基于状态机的方法。我们仍然有一个与开发人员编写的相同签名的方法(public Task CopyStreamToStreamAsync(Stream source,Stream destination)),但该方法的主体完全不同:
[AsyncStateMachine(typeof(<CopyStreamToStreamAsync>d__0))] public Task CopyStreamToStreamAsync(Stream source, Stream destination) { <CopyStreamToStreamAsync>d__0 stateMachine = default; stateMachine.<>t__builder = AsyncTaskMethodBuilder.Create(); stateMachine.source = source; stateMachine.destination = destination; stateMachine.<>1__state = -1; stateMachine.<>t__builder.Start(ref stateMachine); return stateMachine.<>t__builder.Task; } private struct <CopyStreamToStreamAsync>d__0 : IAsyncStateMachine { public int <>1__state; public AsyncTaskMethodBuilder <>t__builder; public Stream source; public Stream destination; private byte[] <buffer>5__2; private TaskAwaiter <>u__1; private TaskAwaiter<int> <>u__2; ... }请注意,与dev编写的唯一签名差异是缺少async关键字本身。async实际上不是方法签名的一部分;与unsafe一样,当您将其放在方法签名中时,您正在表示方法的实现细节,而不是作为合同的一部分实际公开的内容。使用async / await实现返回任务的方法是实现细节。
编译器已生成名为<CopyStreamToStreamAsync> d__0的结构体,并在堆栈上将该结构体的实例初始化为零。重要的是,如果异步方法同步完成,则该状态机将从未离开过堆栈。这意味着除非该方法需要异步完成(即等待某些在该点之前尚未完成的内容),否则与状态机相关的任何分配都不存在。稍后再详细介绍这一点。
该结构是该方法的状态机,不仅包含开发人员编写的所有变换逻辑,还包括用于跟踪该方法中当前位置的字段以及编译器提取出的需要在MoveNext调用之间存活的所有“本地”状态。它是我们在迭代器中看到的IEnumerable<T> / IEnumerator<T>实现的逻辑等效物。(请注意,我展示的代码来自发行版本;在调试版本中,C#编译器实际上会将这些状态机类型生成为类,因为这样做可以在某些调试练习中有所帮助)。
在初始化状态机之后,我们看到一个调用AsyncTaskMethodBuilder.Create()的调用。虽然我们目前专注于任务,但C#语言和编译器允许从异步方法返回任意类型(“类似任务”的类型),例如我可以编写一个public async MyTask CopyStreamToStreamAsync的方法,只要我们以适当的方式增强我们之前定义的MyTask即可。这种适当性包括声明相关的“builder”类型并通过AsyncMethodBuilder属性将其与类型相关联:
[AsyncMethodBuilder(typeof(MyTaskMethodBuilder))] public class MyTask { ... } public struct MyTaskMethodBuilder { public static MyTaskMethodBuilder Create() { ... } public void Start<TStateMachine>(ref TStateMachine stateMachine) where TStateMachine : IAsyncStateMachine { ... } public void SetStateMachine(IAsyncStateMachine stateMachine) { ... } public void SetResult() { ... } public void SetException(Exception exception) { ... } public void AwaitOnCompleted<TAwaiter, TStateMachine>( ref TAwaiter awaiter, ref TStateMachine stateMachine) where TAwaiter : INotifyCompletion where TStateMachine : IAsyncStateMachine { ... } public void AwaitUnsafeOnCompleted<TAwaiter, TStateMachine>( ref TAwaiter awaiter, ref TStateMachine stateMachine) where TAwaiter : ICriticalNotifyCompletion where TStateMachine : IAsyncStateMachine { ... } public MyTask Task { get { ... } } }在这个上下文中,“builder”是指知道如何创建该类型的实例(Task属性),在适当的情况下完成它(SetResult)并返回结果或抛出异常(SetException),并处理将继续连接到尚未完成的awaited事物的钩子(AwaitOnCompleted/AwaitUnsafeOnCompleted)。在System.Threading.Tasks.Task的情况下,默认情况下与AsyncTaskMethodBuilder相关联。通常情况下,这种关联是通过应用于类型的[AsyncMethodBuilder(...)]属性提供的,但是Task被C#特别知道,因此实际上没有使用该属性进行修饰。因此,编译器已经获取了用于此异步方法的构建器,并使用Create方法构造了它的一个实例,该方法是该模式的一部分。请注意,与状态机一样,AsyncTaskMethodBuilder也是一个结构体,因此这里也没有分配。
然后,状态机将填充此入口点方法的参数。这些参数需要在已移入MoveNext的方法体中可用,并且因此这些参数需要存储在状态机中,以便它们可以在后续调用MoveNext时被引用。状态机也被初始化为处于初始状态-1。如果调用MoveNext并且状态为-1,我们将从逻辑上开始方法的开头。
现在是最不起眼但最重要的一行:调用生成器的Start方法。这是模式的另一部分,必须在异步方法的返回位置上使用的类型上公开,用于在状态机上执行初始MoveNext。生成器的Start方法实际上只是这样的:
public void Start<TStateMachine>(ref TStateMachine stateMachine) where TStateMachine : IAsyncStateMachine { stateMachine.MoveNext(); }这样,调用stateMachine.<>t__builder.Start(ref stateMachine)实际上只是调用stateMachine.MoveNext()。那么为什么编译器不直接发出它呢?为什么还需要Start?答案是Start有一点更多的内容,但是为了了解ExecutionContext,我们需要简要了解一下。
ExecutionContext 执行上下文
我们都很熟悉从方法到方法传递状态的过程。你调用一个方法,如果该方法指定了参数,你就调用带有参数的方法,以便将数据输入到被调用者中。这是显式地传递数据。但是还有其他更隐含的方式。例如,一个方法可以是无参的,但可以指示在进行方法调用之前填充某些特定的静态字段,方法将从那里提取状态。方法的签名没有指示它需要参数,因为它没有:调用者和被调用者之间存在一个隐含的协定,即调用者可能会填充某些内存位置,而被调用者可能会读取这些内存位置。如果它们是中介者,即使调用者和被调用者可能并不知道正在发生什么,例如,方法A可能填充静态字段,然后调用B,B调用C,C调用D,最终调用E读取这些静态字段的值。这通常被称为“环境”数据:它不是通过参数传递给你的,而是只是在那里,并且如果需要,可以使用它。
我们可以更进一步,使用线程本地状态。线程本地状态在.NET中通过被标记为[ThreadStatic]的静态字段或ThreadLocal<T>类型实现,可以以相同的方式使用,但是数据仅限于当前执行线程,每个线程都可以拥有其自己隔离的字段副本。有了这个,你可以填充线程静态字段,进行方法调用,然后在方法完成时还原对线程静态字段的更改,从而实现这种隐式传递数据的完全隔离形式。
但是,异步操作如何处理?如果我们进行异步方法调用,并且该异步方法内部的逻辑想要访问该环境数据,该怎么办?如果数据存储在普通静态字段中,异步方法将能够访问它,但是你每次只能有一个这样的方法正在运行,因为多个调用者可能会在写入这些共享静态字段时覆盖彼此的状态。如果数据存储在线程静态字段中,异步方法将能够访问它,但是仅在它在调用线程上同步运行的点之前;如果它将一个continuation连接到某个它启动的操作,而该continuation最终在某个其他线程上运行,它将不再具有访问线程静态信息的能力。即使它碰巧在同一个线程上运行,或者因为调度程序强制它这样做,到它运行时,数据可能已被该线程启动的某些其他操作删除和/或覆盖。对于异步操作,我们需要一种机制,该机制允许任意环境数据在这些异步点之间流动,以便在异步方法的逻辑中,无论逻辑何时何地运行,它都可以访问相同的数据。
进入ExecutionContext。ExecutionContext类型是异步操作之间环境数据流动的工具。它存在于[ThreadStatic]中,但当某些异步操作被启动时,它就会被“捕获”(一种说法是“从线程静态变量中读取副本”),存储起来,然后在异步操作的继续运行时,ExecutionContext首先被恢复到在即将运行操作的线程的[ThreadStatic]中。ExecutionContext是AsyncLocal<T>实现的机制(事实上,在.NET Core中,ExecutionContext完全是关于AsyncLocal<T>的,没有其他作用),因此,如果将值存储到AsyncLocal<T>中,然后例如将工作项排队到线程池上运行,那么该值将在运行池中的工作项内部的AsyncLocal<T>中可见:
var number = new AsyncLocal<int>(); number.Value = 42; ThreadPool.QueueUserWorkItem(_ => Console.WriteLine(number.Value)); number.Value = 0; Console.ReadLine();这将每次运行时打印42。即使我们在队列委托后立即将AsyncLocal<int>的值重置为0,也没有关系,因为ExecutionContext是作为QueueUserWorkItem调用的一部分而被捕获的,该捕获包括AsyncLocal<int>在那个确切时刻的状态。我们可以通过实现自己的简单线程池来更详细地了解这一点:
using System.Collections.Concurrent; var number = new AsyncLocal<int>(); number.Value = 42; MyThreadPool.QueueUserWorkItem(() => Console.WriteLine(number.Value)); number.Value = 0; Console.ReadLine(); class MyThreadPool { private static readonly BlockingCollection<(Action, ExecutionContext?)> s_workItems = new(); public static void QueueUserWorkItem(Action workItem) { s_workItems.Add((workItem, ExecutionContext.Capture())); } static MyThreadPool() { for (int i = 0; i < Environment.ProcessorCount; i++) { new Thread(() => { while (true) { (Action action, ExecutionContext? ec) = s_workItems.Take(); if (ec is null) { action(); } else { ExecutionContext.Run(ec, s => ((Action)s!)(), action); } } }) { IsBackground = true }.UnsafeStart(); } } }这里的MyThreadPool具有一个BlockingCollection<(Action, ExecutionContext?)>,表示它的工作项队列,每个工作项都是要调用的工作委托以及与该工作相关联的ExecutionContext。该池的静态构造函数会启动一堆线程,每个线程只是在一个无限循环中取出下一个工作项并运行它。如果没有为给定的委托捕获ExecutionContext,则直接调用该委托。但是,如果捕获了一个ExecutionContext,则不是直接调用该委托,而是调用ExecutionContext.Run方法,该方法将在运行委托之前将提供的ExecutionContext恢复为当前上下文,然后在运行委托后重置上下文。此示例包括先前显示的AsyncLocal<int>完全相同的代码,只是这次使用的是MyThreadPool而不是ThreadPool,但每次仍将输出42,因为池正在正确地流动ExecutionContext。
顺便说一句,你会注意到我在MyThreadPool的静态构造函数中调用了UnsafeStart。启动新线程正是应该流动ExecutionContext的异步点,事实上,Thread的Start方法使用ExecutionContext.Capture来捕获当前上下文,将其存储在线程上,然后在最终调用Thread的ThreadStart委托时使用该捕获的上下文。但是,我在这个示例中不想这样做,因为我不想让线程在静态构造函数运行时捕获任何ExecutionContext(这样做可能会使关于ExecutionContext的演示更加复杂),因此我使用了UnsafeStart方法。以Unsafe开头的与线程相关的方法与不带Unsafe前缀的相应方法完全相同,只是它们不会捕获ExecutionContext,例如Thread.Start和Thread.UnsafeStart执行相同的工作,但是Start会捕获ExecutionContext,而UnsafeStart则不会。
回到开始
当我写AsyncTaskMethodBuilder.Start的实现时,我们在讨论ExecutionContext时走了弯路。我曾经这样说过Start的实现方式是这样的:
public void Start<TStateMachine>(ref TStateMachine stateMachine) where TStateMachine : IAsyncStateMachine { stateMachine.MoveNext(); }然后我建议简化一下。但是这种简化忽略了一个事实,即该方法实际上需要将ExecutionContext纳入考虑,并且更像这样:
public void Start<TStateMachine>(ref TStateMachine stateMachine) where TStateMachine : IAsyncStateMachine { ExecutionContext previous = Thread.CurrentThread._executionContext; // [ThreadStatic] field try { stateMachine.MoveNext(); } finally { ExecutionContext.Restore(previous); // internal helper } }我们不再像之前建议的那样仅仅调用stateMachine.MoveNext(),而是进行了一些操作:获取当前的ExecutionContext,然后调用MoveNext方法,在其完成后将当前上下文重置为MoveNext调用之前的上下文。
这样做的原因是为了防止异步方法中的环境数据泄漏到调用方。下面的示例方法说明了这一点:
async Task ElevateAsAdminAndRunAsync() { using (WindowsIdentity identity = LoginAdmin()) { using (WindowsImpersonationContext impersonatedUser = identity.Impersonate()) { await DoSensitiveWorkAsync(); } } }“Impersonation”是指更改有关当前用户的环境信息,使其成为其他人的信息;这使得代码可以代表其他人使用其权限和访问。在.NET中,这样的模拟流经异步操作,因此它是ExecutionContext的一部分。现在想象一下如果Start没有恢复先前的上下文,并考虑以下代码:
Task t = ElevateAsAdminAndRunAsync(); PrintUser(); await t;当调用Impersonate之后,此代码可能发现在ElevateAsAdminAndRunAsync内部修改的ExecutionContext在ElevateAsAdminAndRunAsync返回到其同步调用方时仍然存在(这发生在方法等待某些尚未完成的任务的第一次await时)。假设该任务尚未完成,它将导致ElevateAsAdminAndRunAsync调用暂停并返回到调用者,当前线程上的模拟仍然有效。这不是我们想要的。因此,Start设置了这个保护措施,确保对ExecutionContext的任何修改不会流出同步方法调用,而只会随着方法执行的任何后续工作一起流动。
MoveNext
因此,调用了入口点方法,初始化状态机结构,调用了Start方法,这又调用了MoveNext方法。MoveNext是什么?它包含了开发人员方法的所有原始逻辑,但是有很多改变。让我们先看看方法的框架。这是编译器为我们的方法发出的反编译版本,但是将生成的try块中的所有内容移除:
private void MoveNext() { try { ... // all of the code from the CopyStreamToStreamAsync method body, but not exactly as it was written } catch (Exception exception) { <>1__state = -2; <buffer>5__2 = null; <>t__builder.SetException(exception); return; } <>1__state = -2; <buffer>5__2 = null; <>t__builder.SetResult(); }MoveNext方法完成了异步任务方法返回的任务(Task)时,还要处理其他工作。如果try块的主体引发未处理的异常,则任务将带有该异常被故障。如果异步方法成功到达其结束点(相当于同步方法返回),则将成功完成返回的任务。在这两种情况下,它都设置状态机的状态以指示完成。(有时我听到开发人员理论化,认为在第一次等待之前和之后引发的异常之间存在差异……基于上述原因,应该清楚这不是这种情况。任何未处理的异步方法内的异常,无论在方法的哪个位置,无论该方法是否已经被挂起,都将在上述catch块中结束,然后将被存储到从异步方法返回的任务中。)
还要注意的是,此完成通过生成器进行,使用其SetException和SetResult方法,这些方法是编译器预期生成器模式的一部分。如果异步方法以前已经被挂起,生成器将已经必须制造一个任务作为该挂起处理的一部分(我们很快将看到如何以及在哪里处理),在这种情况下,调用SetException/SetResult将完成该任务。然而,如果异步方法以前没有挂起,则我们还没有创建任务或向调用者返回任何内容,因此生成器在如何生成任务方面具有更大的灵活性。如果您还记得先前的入口点方法,它做的最后一件事是将任务返回给调用方,它通过返回访问生成器的Task属性(许多称为“Task”的东西,我知道)来完成。
public Task CopyStreamToStreamAsync(Stream source, Stream destination) { ... return stateMachine.<>t__builder.Task; }这位生成器知道如果方法曾经被暂停,在这种情况下它有一个已经创建的Task,并且只返回那个Task。如果方法从未暂停,而且生成器还没有Task,那么它可以在这里创建一个已完成的Task。在这种情况下,如果成功完成,它可以使用Task.CompletedTask而不是分配一个新的Task,避免任何分配。对于泛型Task<TResult>,生成器可以使用Task.FromResult<TResult>(TResult result)。
生成器还可以根据其要创建的对象进行任何它认为适当的转换。例如,Task实际上有三种可能的最终状态:成功、失败和取消。AsyncTaskMethodBuilder的SetException方法特殊处理OperationCanceledException,如果提供的异常是OperationCanceledException或派生自OperationCanceledException,则将Task转换为TaskStatus.Canceled最终状态;否则,任务以TaskStatus.Faulted结束。这种区别通常在消费代码中不明显;由于异常被存储到Task中,无论它被标记为已取消或失败,等待该Task的代码都无法观察到状态之间的区别(原始异常将在任何情况下都被传播)...它只影响直接与Task交互的代码,例如通过ContinueWith,它具有使继续仅针对子集完成状态被调用的重载。
现在我们了解了生命周期方面的内容,这里是MoveNext中try块中填写的所有内容:
private void MoveNext() { try { int num = <>1__state; TaskAwaiter<int> awaiter; if (num != 0) { if (num != 1) { <buffer>5__2 = new byte[4096]; goto IL_008b; } awaiter = <>u__2; <>u__2 = default(TaskAwaiter<int>); num = (<>1__state = -1); goto IL_00f0; } TaskAwaiter awaiter2 = <>u__1; <>u__1 = default(TaskAwaiter); num = (<>1__state = -1); IL_0084: awaiter2.GetResult(); IL_008b: awaiter = source.ReadAsync(<buffer>5__2, 0, <buffer>5__2.Length).GetAwaiter(); if (!awaiter.IsCompleted) { num = (<>1__state = 1); <>u__2 = awaiter; <>t__builder.AwaitUnsafeOnCompleted(ref awaiter, ref this); return; } IL_00f0: int result; if ((result = awaiter.GetResult()) != 0) { awaiter2 = destination.WriteAsync(<buffer>5__2, 0, result).GetAwaiter(); if (!awaiter2.IsCompleted) { num = (<>1__state = 0); <>u__1 = awaiter2; <>t__builder.AwaitUnsafeOnCompleted(ref awaiter2, ref this); return; } goto IL_0084; } } catch (Exception exception) { <>1__state = -2; <buffer>5__2 = null; <>t__builder.SetException(exception); return; } <>1__state = -2; <buffer>5__2 = null; <>t__builder.SetResult(); }这种复杂性可能会让人有些熟悉。还记得我们手动实现的基于APM的BeginCopyStreamToStream有多复杂吗?这个方法并不是那么复杂,但它更好的地方在于编译器为我们做了这些工作,将该方法重写为一种继续传递的形式,同时确保所有必要的状态都被保存以供这些继续使用。即使如此,我们也可以仔细阅读并理解。记得状态在入口点被初始化为-1。然后我们进入MoveNext,发现此状态(现在存储在num本地变量中)既不是0也不是1,因此我们执行创建临时缓冲区的代码,然后分支到标签IL_008b,从那里调用stream.ReadAsync。请注意,在这一点上,我们仍然是从MoveNext同步运行的,因此也是从Start同步运行的,从入口点同步运行,这意味着开发人员的代码调用了CopyStreamToStreamAsync,它仍然在同步执行,尚未返回一个表示该方法最终完成的Task。这可能即将发生改变...
我们调用Stream.ReadAsync,从中得到一个Task<int>。读取可能已经同步完成,也可能异步完成,但速度非常快,已经完成,或者可能尚未完成。无论如何,我们都有了一个表示其最终完成的Task<int>,编译器生成的代码检查这个Task<int>以确定如何继续:如果Task<int>实际上已经完成了(无论它是同步完成还是仅在我们检查时完成),那么该方法的代码可以继续同步运行...没有必要花费不必要的开销来排队处理该方法执行的其余部分,我们反而可以继续在此处运行。但是为了处理Task<int>尚未完成的情况,编译器需要发出将继续连接到Task的代码。因此,它需要发出询问Task“你做完了吗?”的代码。它直接与Task交谈吗?
如果在C#中您只能等待System.Threading.Tasks.Task,那将是有限制的。同样,在C#编译器必须知道每个可能被等待的类型的情况下,也会有限制。相反,C#通常在这种情况下采用API的模式。代码可以等待任何公开适当模式的内容,即“等待器”模式(就像您可以对提供适当“可枚举”模式的任何内容进行foreach一样)。例如,我们可以增强我们之前编写的MyTask类型以实现等待器模式:
class MyTask { ... public MyTaskAwaiter GetAwaiter() => new MyTaskAwaiter { _task = this }; public struct MyTaskAwaiter : ICriticalNotifyCompletion { internal MyTask _task; public bool IsCompleted => _task._completed; public void OnCompleted(Action continuation) => _task.ContinueWith(_ => continuation()); public void UnsafeOnCompleted(Action continuation) => _task.ContinueWith(_ => continuation()); public void GetResult() => _task.Wait(); } }如果一个类型公开了GetAwaiter()方法,就可以使用await等待它,而Task就是这样的类型。GetAwaiter()方法需要返回一个对象,该对象包含多个成员,其中包括一个IsCompleted属性,该属性用于在调用IsCompleted时检查操作是否已完成。您可以在此处看到它的发生:在IL_008b处,从ReadAsync返回的Task上调用GetAwaiter()方法,然后在那个结构体awaiter实例上访问IsCompleted。如果IsCompleted返回true,则我们将跳转到IL_00f0,其中代码调用awaiter的另一个成员:GetResult()。如果操作失败,则GetResult()负责抛出异常以将其传播到异步方法中的await之外;否则,GetResult()负责返回操作的结果(如果有)。在此处的ReadAsync中,如果结果为0,则我们跳出了读/写循环,进入方法的末尾,调用SetResult,完成任务。
然而,回到刚才的话题,如果IsCompleted检查返回false,那么最有趣的部分就是会发生什么。如果返回true,我们将继续处理循环,类似于在APM模式中CompletedSynchronously返回true时,调用Begin方法的调用者(而不是回调)负责继续执行。但是,如果IsCompleted返回false,则需要暂停异步方法的执行,直到await的操作完成。这意味着从MoveNext返回,并且由于这是Start的一部分,而我们仍然在入口点方法中,因此需要将Task返回给调用方。但在所有这些之前,我们需要将一个继续项挂接到正在等待的Task上(请注意,为了避免像APM案例中的堆栈潜入一样,如果异步操作在IsCompleted返回false之后完成,但在我们到达时尚未挂接继续项,则继续项仍然需要从调用线程异步调用,因此它将被排队)。由于我们可以await任何东西,因此不能直接对Task实例进行操作;相反,我们需要通过一些基于模式的方法来执行此操作。
这是否意味着awaiter上存在一个方法来连接continuation?这是有意义的;毕竟,Task本身支持continuation,有ContinueWith方法等等......难道不应该是从GetAwaiter返回的TaskAwaiter公开了允许我们设置continuation的方法吗?实际上是这样的。awaiter模式要求awaiter实现INotifyCompletion接口,其中包含一个单一方法void OnCompleted(Action continuation)。awaiter还可以选择实现ICriticalNotifyCompletion接口,它继承了INotifyCompletion并添加了一个void UnsafeOnCompleted(Action continuation)方法。根据我们之前对ExecutionContext的讨论,您可以猜到这两种方法之间的区别:两种方法都连接continuation,但是OnCompleted应该流传ExecutionContext,而UnsafeOnCompleted则不需要。这里需要两种不同方法的原因,INotifyCompletion.OnCompleted和ICriticalNotifyCompletion.UnsafeOnCompleted,主要是历史原因,与代码访问安全性(Code Access Security,CAS)有关。在.NET Core中,CAS已经不存在,并且在.NET Framework中默认关闭,只有在选择遗留的部分信任功能时才有作用。当使用部分信任时,CAS信息作为ExecutionContext的一部分流动,因此不流动是“不安全”的,因此未流动ExecutionContext的方法被标记为“Unsafe”。此类方法也被标记为[SecurityCritical],部分可信代码无法调用[SecurityCritical]方法。因此,创建了两个OnCompleted的变体,编译器优先使用UnsafeOnCompleted(如果提供),但在必要时始终提供OnCompleted变体,以防awaiter需要支持部分信任。然而,从异步方法的角度来看,构建器始终在await点之间传递ExecutionContext,因此awaiter也这样做是不必要和重复的工作。
好的,当需要暂停时,awaiter暴露了一种方法来连接继续执行的方法。编译器可以直接使用它,但有一个非常关键的问题:继续执行的方法应该是什么?更重要的是,应该与什么对象相关联?请记住,状态机结构体在堆栈上,而我们目前正在运行的MoveNext调用是该实例上的方法调用。我们需要保留状态机,以便在恢复时拥有所有正确的状态,这意味着状态机不能仅仅继续留在堆栈上;它需要被复制到堆上的某个地方,因为堆栈最终将用于此线程执行的其他后续、无关的工作。然后,继续执行需要在堆上的状态机副本上调用MoveNext方法。
此外,ExecutionContext在这里也是相关的。状态机需要确保在暂停点捕获ExecutionContext中存储的任何环境数据,然后在恢复点应用该数据,这意味着继续执行还需要合并该ExecutionContext。因此,仅创建指向状态机上MoveNext的委托是不够的。这也是不必要的开销。如果在我们暂停时创建一个指向状态机上MoveNext的委托,每次这样做时,我们都将装箱状态机结构体(即使它已经作为其他对象的一部分在堆上),并分配一个额外的委托(委托的this对象引用将指向新装箱的结构体的副本)。因此,我们需要做一个复杂的舞蹈,确保我们只在方法第一次暂停执行时将结构体从堆栈提升到堆上,但在所有其他时间使用相同的堆对象作为MoveNext的目标,并在此过程中确保我们已经捕获了正确的上下文,并在恢复时确保我们正在使用捕获的上下文来调用操作。
这比我们希望编译器发出的逻辑要多得多……相反,我们希望它封装在一个帮助程序中,原因有几个。首先,这是将复杂代码发出到每个用户的程序集中的大量复杂代码。其次,我们希望允许在实现构建器模式的过程中定制该逻辑(我们稍后将看到为什么要这样做的示例,当我们谈论池化时)。第三,我们希望能够发展和改进该逻辑,并让现有的先前编译的二进制文件变得更好。这并不是一个假设性的问题;在.NET Core 2.1中,此支持的库代码已完全改写,因此操作比.NET Framework上的操作要高效得多。我们首先将探讨在.NET Framework上如何工作,然后再看看在.NET Core中发生了什么。
您可以看到由C#编译器生成的代码在暂停时发生了什么:
if (!awaiter.IsCompleted) // we need to suspend when IsCompleted is false { <>1__state = 1; <>u__2 = awaiter; <>t__builder.AwaitUnsafeOnCompleted(ref awaiter, ref this); return; }这个AwaitUnsafeOnCompleted方法的实现太复杂了,无法在这里复制,所以我将总结一下在.NET Framework上它的作用:
- 它使用ExecutionContext.Capture()来获取当前上下文。
- 然后它分配一个MoveNextRunner对象来包装捕获的上下文以及装箱的状态机(如果这是方法第一次暂停,我们还没有它,所以我们只使用null作为占位符)。
- 然后它创建一个指向MoveNextRunner上的Run方法的Action委托;这就是它如何能够获取一个委托,在捕获的ExecutionContext上下文中调用状态机的MoveNext。
- 如果这是方法第一次暂停,我们还没有装箱的状态机,所以此时它将其装箱,通过将实例存储到一个作为IAsyncStateMachine接口类型的本地变量中,在堆上创建一个副本。然后将该箱存储到已分配的MoveNextRunner中。
- 现在是一个有点令人费解的步骤。如果回顾一下状态机结构的定义,它包含构建器,即public AsyncTaskMethodBuilder<>t__builder;,如果回顾一下构建器的定义,则包含internal IAsyncStateMachine m_stateMachine;。构建器需要引用装箱的状态机,以便在后续暂停时它可以看到已经装箱了状态机,不需要再次装箱。但是我们刚刚装箱了状态机,而该状态机包含了一个构建器,该构建器的m_stateMachine字段为空。我们需要改变该装箱状态机的构建器的m_stateMachine,使其指向其父级盒子。为了实现这一点,编译器生成的状态机结构实现了IAsyncStateMachine接口,其中包括一个void SetStateMachine(IAsyncStateMachine stateMachine)方法,该状态机结构包括该接口方法的实现:
private void SetStateMachine(IAsyncStateMachine stateMachine) => <>t__builder.SetStateMachine(stateMachine);因此,构建器装箱状态机,然后将该箱传递给该箱的SetStateMachine方法,该方法调用构建器的SetStateMachine方法,将该箱存储到该字段中。
- 最后,我们有一个表示继续的Action,并将其传递给awaiter的UnsafeOnCompleted方法。在TaskAwaiter的情况下,任务将该操作存储到任务的继续列表中,以便在任务完成时,它将调用该操作,通过MoveNextRunner.Run回调,通过ExecutionContext.Run回调,最终调用状态机的MoveNext方法以重新进入状态机并继续从上次离开的地方运行。
这就是在.NET Framework上发生的情况,您可以通过分配分析器等分析工具来查看其结果,例如运行分配分析器以查看每个await分配了什么。让我们看看这个愚蠢的程序,我只是为了突出显示涉及的分配成本而编写的:
using System.Threading; using System.Threading.Tasks; class Program { static async Task Main() { var al = new AsyncLocal<int>() { Value = 42 }; for (int i = 0; i < 1000; i++) { await SomeMethodAsync(); } } static async Task SomeMethodAsync() { for (int i = 0; i < 1000; i++) { await Task.Yield(); } } }该程序创建了一个AsyncLocal<int>对象,以流动值42通过所有后续的异步操作。然后调用SomeMethodAsync 1000次,每个方法都暂停/恢复1000次。在Visual Studio中,使用.NET对象分配跟踪分析器运行此程序,得出以下结果:
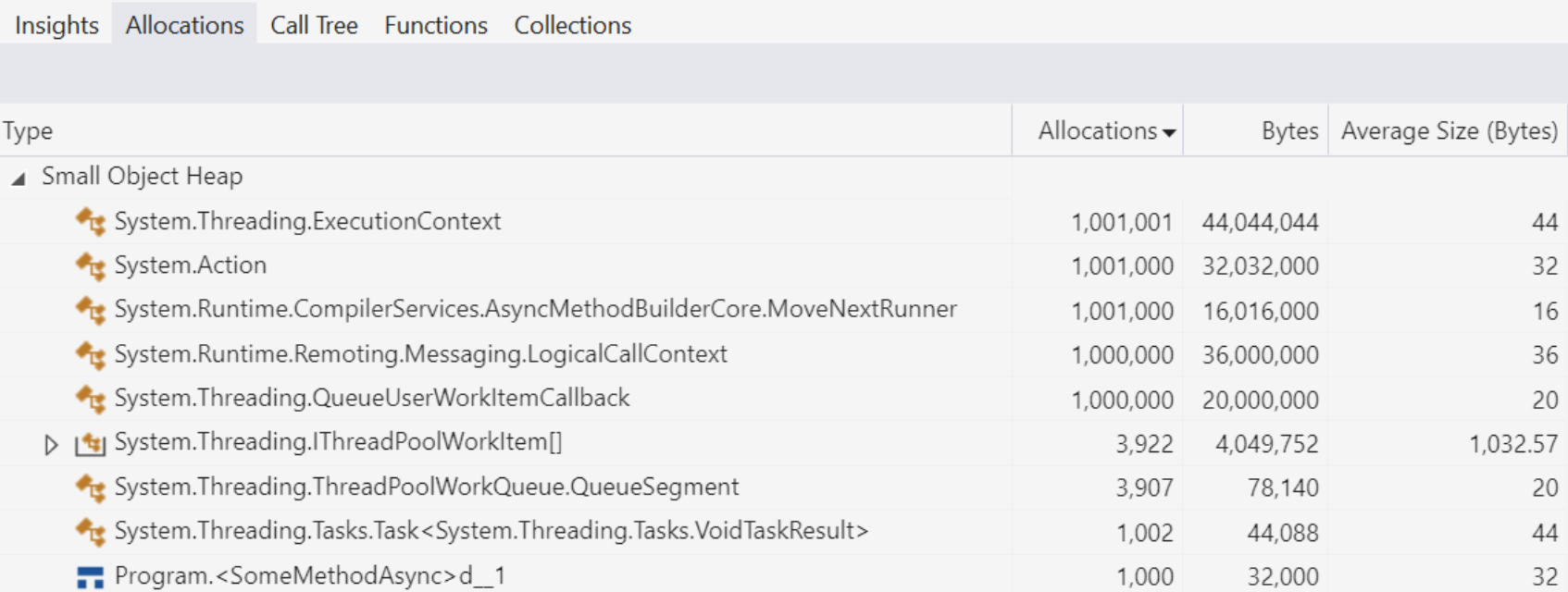
这是很多分配!让我们逐个检查以了解它们的来源。
- ExecutionContext。有超过一百万个被分配了。为什么?因为在.NET Framework中,ExecutionContext是一个可变数据结构。因为我们想要流动在异步操作分叉时存在的数据,而且我们不希望它看到之后执行的变更,所以我们需要复制ExecutionContext。每个分叉操作都需要进行这样的复制,因此每次调用SomeMethodAsync,每个方法都暂停/恢复1000次,就会有一百万个ExecutionContext实例。痛哉!
- Action。同样,每当我们等待还没有完成的操作(这是我们的一百万个await Task.Yield()的情况),我们就会分配一个新的Action委托,以传递给该awaiter的UnsafeOnCompleted方法。
- MoveNextRunner。同样的问题;有一百万个这样的实例,因为在先前的步骤概述中,每当我们暂停时,我们就会分配一个新的MoveNextRunner来存储Action和ExecutionContext,以便使用后者来执行前者。
- LogicalCallContext。另一百万个。这些是.NET Framework上AsyncLocal<T>的实现细节;AsyncLocal<T>将其数据存储到ExecutionContext的“逻辑调用上下文”中,这是一种流动ExecutionContext的一般状态的高级方式。因此,如果我们制作了ExecutionContext的一百万份副本,我们也会制作一百万份LogicalCallContext的副本。
- QueueUserWorkItemCallback。每个Task.Yield()都将一个工作项排队到线程池中,导致分配用于表示这些操作的工作项对象的一百万次分配。
- 6. Task<VoidResult>。有一千个,所以我们至少不在“一百万”俱乐部中。每个异步Task调用在异步完成时都需要分配一个新的Task实例来表示该调用的最终完成。
- <SomeMethodAsync>d__1。这是编译器生成的状态机结构的盒子。一千个方法暂停,就会发生一千个盒子。
- QueueSegment/IThreadPoolWorkItem[]。有几千个,它们与特定的异步方法没有技术上的关联,而是与一般情况下将工作项排队到线程池有关。在.NET Framework中,线程池的队列是非循环段的链接列表。这些段不会被重复使用;对于长度为N的段,一旦N个工作项已经被排队到该段中并从该段中出队,该段就被丢弃,并留待垃圾回收。
那就是 .NET Framework。这是 .NET Core:

太漂亮了!对于.NET Framework的这个示例,有超过500万次的分配,总共分配了约145MB的内存。然而,在.NET Core上运行相同的示例时,只有大约1000次分配,总共分配了约109KB的内存。为什么会少这么多呢?
- ExecutionContext。在.NET Core中,ExecutionContext现在是不可变的。缺点是对于上下文的每一次更改,例如将值设置到AsyncLocal<T>中,都需要分配一个新的ExecutionContext。然而,好处是流动上下文比更改上下文要常见得多,由于ExecutionContext现在是不可变的,我们不再需要在流动过程中进行克隆。"捕获"上下文现在只需要从字段中读取它,而不是读取它并克隆其内容。因此,流动比更改更常见,而且更便宜。
- LogicalCallContext。在.NET Core中,LogicalCallContext已不再存在。在.NET Core中,ExecutionContext只用于AsyncLocal<T>的存储。其他在ExecutionContext中有自己专门位置的东西都是基于AsyncLocal<T>建模的。例如,在.NET Framework中,模拟身份验证会作为ExecutionContext的SecurityContext的一部分流动;在.NET Core中,模拟身份验证通过使用一个AsyncLocal<SafeAccessTokenHandle>流动,该AsyncLocal使用valueChangedHandler对当前线程进行适当的更改。
- QueueSegment/IThreadPoolWorkItem[]。在.NET Core中,ThreadPool的全局队列现在实现为ConcurrentQueue<T>,并且ConcurrentQueue<T>已被重写为非固定大小的循环段的链表。一旦段的大小足够大,以至于段永远不会填满,因为稳态出队能够跟上稳态入队,就不需要分配任何其他的段,并且同样足够大的段将无限地使用。
那么其他的分配,例如Action、MoveNextRunner和<SomeMethodAsync>d__1呢?理解如何消除剩余的分配需要深入研究在.NET Core上的工作原理。
让我们将我们的讨论倒回到我们讨论悬停时间的时候:
if (!awaiter.IsCompleted) // we need to suspend when IsCompleted is false { <>1__state = 1; <>u__2 = awaiter; <>t__builder.AwaitUnsafeOnCompleted(ref awaiter, ref this); return; }这里生成的代码无论是针对哪个平台,都是相同的,所以无论是.NET Framework还是.NET Core,此处的悬挂操作生成的IL代码都是相同的。然而,不同的是AwaitUnsafeOnCompleted方法的实现,在.NET Core中这个方法的实现要复杂得多:
- 首先,它会调用ExecutionContext.Capture()方法来获取当前的执行上下文。
- 然后,它就会与.NET Framework分道扬镳。在.NET Core中,builder只有一个字段:
public struct AsyncTaskMethodBuilder { private Task<VoidTaskResult>? m_task; ... }在捕获了ExecutionContext之后,它会检查m_task字段是否包含AsyncStateMachineBox<TStateMachine>的实例,其中TStateMachine是编译器生成的状态机结构体的类型。这个AsyncStateMachineBox<TStateMachine>类型就是“魔法”。它的定义如下:
private class AsyncStateMachineBox<TStateMachine> : Task<TResult>, IAsyncStateMachineBox where TStateMachine : IAsyncStateMachine { private Action? _moveNextAction; public TStateMachine? StateMachine; public ExecutionContext? Context; ... }与其拥有独立的Task不同,这是一个Task(请注意它的基类型)。与其将状态机装箱不同,该结构体只是作为一个强类型字段存在于这个Task上。而且,与其拥有独立的MoveNextRunner来存储Action和ExecutionContext,它们只是这个类型的字段。由于这是存储在builder的m_task字段中的实例,我们可以直接访问它,而不需要在每次挂起时重新分配东西。如果ExecutionContext发生变化,我们只需将该字段覆盖为新的上下文,而不需要分配任何其他东西;我们仍然可以通过任何Action指向正确的位置。因此,在捕获了ExecutionContext之后,如果我们已经有了这个AsyncStateMachineBox<TStateMachine>的实例,那么这不是第一次挂起该方法,我们可以将新捕获的ExecutionContext直接存储到它中。如果我们没有AsyncStateMachineBox<TStateMachine>的实例,那么我们就需要分配它:
var box = new AsyncStateMachineBox<TStateMachine>(); taskField = box; // important: this must be done before storing stateMachine into box.StateMachine! box.StateMachine = stateMachine; box.Context = currentContext;请注意,源代码中的该行注释为“重要”。这取代了.NET Framework中那个复杂的SetStateMachine操作,因此在.NET Core中根本不使用SetStateMachine。你在那里看到的taskField是对AsyncTaskMethodBuilder的m_task字段的引用。我们分配AsyncStateMachineBox<TStateMachine>,然后通过taskField将该对象存储到builder的m_task中(这是堆栈上状态机结构体中的builder),然后将堆栈上的状态机(现在已经包含了对该box的引用)复制到基于堆的AsyncStateMachineBox<TStateMachine>中,使得AsyncStateMachineBox<TStateMachine>适当且递归地引用它自身。这仍然是一种令人费解的操作,但效率要高得多。
- 然后,我们可以获得此实例上方法的 Action,该方法将调用其 MoveNext 方法,该方法将在调用 StateMachine 的 MoveNext 之前执行适当的 ExecutionContext 恢复。并且该 Action 可以缓存到 _moveNextAction 字段中,这样任何后续使用都可以重复使用相同的 Action。然后将该 Action 传递给等待者的 UnsafeOnCompleted 以连接继续。
这个解释解释了为什么大部分分配都已经消失了: <SomeMethodAsync>d__1不会被装箱,而是只作为任务本身的一个字段存在,而 MoveNextRunner 不再需要,因为它只是用于存储 Action 和 ExecutionContext。但是,根据这个解释,我们仍然应该看到1000个 Action 分配,即每个方法调用一个,但我们没有看到。为什么呢?那些 QueueUserWorkItemCallback 对象呢……我们仍然作为 Task.Yield() 的一部分排队,为什么它们没有出现?
正如我所指出的,将实现细节推迟到核心库中的一个好处是,它可以随时间演变实现方法,我们已经看到了它从 .NET Framework 演变到 .NET Core 的过程。它也进一步演变为 .NET Core 的初始重写,具有从系统的关键组件获得内部访问的附加优化。特别是,异步基础结构知道核心类型,如 Task 和 TaskAwaiter。因为它知道它们并具有内部访问权限,所以它不必遵守公开定义的规则。 C# 语言遵循的等待程序模式要求等待程序具有 AwaitOnCompleted 或 AwaitUnsafeOnCompleted 方法,这两种方法都将继续作为 Action,这意味着基础结构需要能够创建一个 Action 以表示继续,以便与基础结构不知道的任意等待程序一起工作。但是,如果基础结构遇到了它知道的等待程序,它不必采取相同的代码路径。因此,对于 System.Private.CoreLib 中定义的所有核心等待程序,基础结构都有一个更简单的路径可以遵循,它根本不需要 Action。这些等待程序都知道 IAsyncStateMachineBox,能够将 box 对象本身视为续集。因此,例如,由 Task.Yield 返回的 YieldAwaitable 能够直接将 IAsyncStateMachineBox 排队到 ThreadPool 中作为工作项,而在等待任务时使用的 TaskAwaiter 能够将 IAsyncStateMachineBox 直接存储到 Task 的续集列表中。不需要 Action,不需要 QueueUserWorkItemCallback。
因此,在一种非常常见的情况下,异步方法只等待来自System.Private.CoreLib(Task、Task<TResult>、ValueTask、ValueTask<TResult>、YieldAwaitable以及这些ConfigureAwait变体)的事物时,最坏情况是整个异步方法的整个生命周期只有一个与开销相关的单个分配:如果该方法暂停,则它会分配存储所有其他所需状态的单个Task派生类型,如果该方法从未暂停,则不会产生其他分配。
如果需要的话,我们也可以在分摊的方式下消除最后一个分配。正如已经展示的那样,Task有一个默认的构建器(AsyncTaskMethodBuilder),Task<TResult>也有一个默认的构建器(AsyncTaskMethodBuilder<TResult>),ValueTask和ValueTask<TResult>也有一个默认的构建器(AsyncValueTaskMethodBuilder和AsyncValueTaskMethodBuilder<TResult>)。对于ValueTask/ValueTask<TResult>,构建器本身非常简单,因为它们仅处理同步成功完成的情况,在这种情况下,异步方法在不暂停的情况下完成,构建器可以返回一个ValueTask.Completed或一个包装结果值的ValueTask<TResult>。对于其他所有情况,它们只需委托给AsyncTaskMethodBuilder/AsyncTaskMethodBuilder<TResult>,因为将返回的ValueTask/ValueTask<TResult>仅包装了一个Task,因此可以共享所有相同的逻辑。但是,.NET 6和C# 10引入了能够按方法覆盖使用的构建器的能力,并引入了一些专门为ValueTask/ValueTask<TResult>设计的构建器,这些构建器能够池化IValueTaskSource/IValueTaskSource<TResult>对象,这些对象代表最终完成,而不是使用Tasks。
我们可以在我们的示例中看到这种影响。让我们轻微地调整我们正在分析的SomeMethodAsync,以返回ValueTask而不是Task:
static async ValueTask SomeMethodAsync() { for (int i = 0; i < 1000; i++) { await Task.Yield(); } }这将产生以下生成的入口点:
[AsyncStateMachine(typeof(<SomeMethodAsync>d__1))] private static ValueTask SomeMethodAsync() { <SomeMethodAsync>d__1 stateMachine = default; stateMachine.<>t__builder = AsyncValueTaskMethodBuilder.Create(); stateMachine.<>1__state = -1; stateMachine.<>t__builder.Start(ref stateMachine); return stateMachine.<>t__builder.Task; }现在,我们将[AsyncMethodBuilder(typeof(PoolingAsyncValueTaskMethodBuilder))]添加到SomeMethodAsync的声明中:
[AsyncMethodBuilder(typeof(PoolingAsyncValueTaskMethodBuilder))] static async ValueTask SomeMethodAsync() { for (int i = 0; i < 1000; i++) { await Task.Yield(); } }编译器输出如下:
[AsyncStateMachine(typeof(<SomeMethodAsync>d__1))] [AsyncMethodBuilder(typeof(PoolingAsyncValueTaskMethodBuilder))] private static ValueTask SomeMethodAsync() { <SomeMethodAsync>d__1 stateMachine = default; stateMachine.<>t__builder = PoolingAsyncValueTaskMethodBuilder.Create(); stateMachine.<>1__state = -1; stateMachine.<>t__builder.Start(ref stateMachine); return stateMachine.<>t__builder.Task; }实际的C#代码生成对于整个实现,包括整个状态机(未显示)几乎是相同的;唯一的区别是创建和存储的构建器类型,因此在我们以前看到构建器的引用处处使用。如果您查看PoolingAsyncValueTaskMethodBuilder的代码,您会发现它的结构几乎与AsyncTaskMethodBuilder相同,包括使用一些完全相同的共享例程来执行特定的awaiter类型。关键区别是,当方法首次暂停时,它不会执行new AsyncStateMachineBox<TStateMachine>(),而是执行StateMachineBox<TStateMachine>.RentFromCache(),并且在完成异步方法(SomeMethodAsync)并等待返回的ValueTask完成时,租用的框将返回到缓存中。这意味着(摊销)零分配:

缓存本身有点有趣。对象池可能是一个好主意,也可能是一个坏主意。对象的创建成本越高,对它们进行池化的价值就越大;例如,池化非常大的数组比池化非常小的数组更有价值,因为较大的数组不仅需要更多的CPU周期和内存访问来清零,而且会对垃圾回收器产生更多的压力,导致更频繁的垃圾回收。然而,对于非常小的对象,池化它们可能是一个净负面效应。池本身仅仅是内存分配器,垃圾回收器也是内存分配器,因此,在进行池化时,您正在用一个分配器的成本来换取另一个分配器的成本,而垃圾回收器非常擅长处理大量的小型短寿命对象。如果您在对象的构造函数中进行了大量工作,则避免这些工作可以使分配器本身的成本相形见绌,从而使池化更有价值。但是,如果您在对象的构造函数中几乎没有做任何工作,并且对其进行池化,则您正在打赌您的分配器(您的池)对所使用的访问模式比GC更高效,这通常是一个错误的赌注。还存在其他成本,有些情况下,您可能会有效地反对GC的启发式算法;例如,GC基于这样的前提进行优化,即从较高代(例如gen2)对象到较低代(例如gen0)对象的引用相对较少,但是池化对象可能会使这些前提无效。
现在,异步方法创建的对象并不是微小的,而且它们可能出现在超级热的路径上,因此进行池化可能是合理的。但是为了使其尽可能有价值,我们也希望尽可能避免开销。因此,池非常简单,选择使租借和归还非常快速,几乎没有争用,即使这意味着它可能会分配比更积极缓存更多的对象。对于每种状态机类型,实现会为每个线程和每个核心池化多达一个状态机盒子;这使它能够以最小的开销和最小的争用租用和归还(没有其他线程可以同时访问线程特定的缓存,而且很少有其他线程可以同时访问核心特定的缓存)。虽然这可能看起来像是一个相对较小的池,但它也非常有效地显著减少了稳态分配,因为池仅负责存储当前未使用的对象;您可以有一百万个异步方法在任何给定时间都在运行,即使池只能存储每个线程和每个核心一个对象,它仍然可以避免丢失大量对象,因为它只需要存储一个对象足以将其从一个操作传输到另一个操作,而不是在该操作中使用它。
SynchronizationContext and ConfigureAwait
我们之前在EAP模式的上下文中讨论了SynchronizationContext,并提到它会再次出现。SynchronizationContext使得调用可重用的帮助程序并在任何时候和任何地方自动进行调度成为可能。因此,我们自然希望在async/await中“只要工作”,实际上它确实可以。回到之前的按钮单击处理程序:
ThreadPool.QueueUserWorkItem(_ => { string message = ComputeMessage(); button1.BeginInvoke(() => { button1.Text = message; }); });使用async/await,我们希望可以像以下这样编写:
button1.Text = await Task.Run(() => ComputeMessage());
ComputeMessage的调用被卸载到线程池中,方法完成后,执行会转回与按钮关联的UI线程,并在该线程上设置其Text属性。
SynchronizationContext与awaiter实现的集成(状态机生成的代码对SynchronizationContext一无所知)留给了awaiter实现自己完成,因为当被表示的异步操作完成时,awaiter负责实际调用或排队提供的继续操作。虽然自定义的awaiter不需要尊重SynchronizationContext.Current,但Task、Task<TResult>、ValueTask和ValueTask<TResult>的awaiter都会这样做。这意味着,当您默认等待Task、Task<TResult>、ValueTask、ValueTask<TResult>甚至是Task.Yield()调用的结果时,awaiter默认会查找当前的SynchronizationContext,然后如果成功获取到非默认上下文,最终将继续操作排队到该上下文中。
如果我们查看TaskAwaiter中涉及的代码,就可以看到这一点。以下是来自Corelib的相关代码片段:
internal void UnsafeSetContinuationForAwait(IAsyncStateMachineBox stateMachineBox, bool continueOnCapturedContext) { if (continueOnCapturedContext) { SynchronizationContext? syncCtx = SynchronizationContext.Current; if (syncCtx != null && syncCtx.GetType() != typeof(SynchronizationContext)) { var tc = new SynchronizationContextAwaitTaskContinuation(syncCtx, stateMachineBox.MoveNextAction, flowExecutionContext: false); if (!AddTaskContinuation(tc, addBeforeOthers: false)) { tc.Run(this, canInlineContinuationTask: false); } return; } else { TaskScheduler? scheduler = TaskScheduler.InternalCurrent; if (scheduler != null && scheduler != TaskScheduler.Default) { var tc = new TaskSchedulerAwaitTaskContinuation(scheduler, stateMachineBox.MoveNextAction, flowExecutionContext: false); if (!AddTaskContinuation(tc, addBeforeOthers: false)) { tc.Run(this, canInlineContinuationTask: false); } return; } } } ... }这是一种确定要存储到任务作为继续的对象的方法的一部分。它被传递了stateMachineBox,正如先前所提到的,它可以直接存储到任务的继续列表中。然而,这种特殊逻辑可能会包装IAsyncStateMachineBox,以便在存在调度程序的情况下也可以将其纳入其中。它会检查当前是否有非默认的同步上下文,如果有,则创建一个SynchronizationContextAwaitTaskContinuation作为实际将被存储为继续的对象;该对象反过来又包装了原始对象和捕获的同步上下文,并知道如何在排队到后者的工作项中调用前者的MoveNext。这就是你能够在UI应用程序的某个事件处理程序中等待并使代码在等待完成后继续在正确的线程上运行的原因。这里需要注意的下一个有趣的事情是,它不仅注意同步上下文:如果找不到要使用的自定义同步上下文,它还会查看任务使用的TaskScheduler类型是否有需要考虑的自定义类型。与SynchronizationContext一样,如果存在非默认的类型,则使用原始框包装一个TaskSchedulerAwaitTaskContinuation作为继续对象。
但可以说,注意到这个方法体的第一行是最有趣的:if (continueOnCapturedContext)。如果continueOnCapturedContext为true,我们才会对SynchronizationContext/TaskScheduler进行这些检查;如果为false,则实现会像两者都是默认的一样行动并忽略它们。那么,是什么把continueOnCapturedContext设置为false呢?你可能已经猜到了:使用备受欢迎的ConfigureAwait(false)。
我在ConfigureAwait FAQ中详细讨论了ConfigureAwait,因此我建议您阅读更多信息。简而言之,ConfigureAwait(false)作为等待的一部分唯一的作用就是将其布尔参数作为continueOnCapturedContext值传递到此函数(以及其他类似函数)中,以便跳过对SynchronizationContext/TaskScheduler的检查,并表现得好像它们都不存在。对于任务来说,这允许任务在任何它认为合适的地方调用其继续,而不是被迫将它们排队以在某个特定的调度程序上执行。
我之前提到了同步上下文的另一个方面,我说我们会再次看到它:OperationStarted/OperationCompleted。现在是时候了。它们作为大家爱恨交加的特性的一部分出现:异步void。除了ConfigureAwait之外,异步void可以说是作为异步/等待的一部分添加的最具分裂性的特性之一。它只有一个目的:事件处理程序。在UI应用程序中,您希望能够编写如下代码:
button1.Click += async (sender, eventArgs) => { button1.Text = await Task.Run(() => ComputeMessage()); };但是,如果所有的异步方法都必须像Task一样有一个返回类型,你将无法这样做。Click事件的签名为“public event EventHandler? Click;”,其中EventHandler被定义为“public delegate void EventHandler(object? sender, EventArgs e);”,因此为了提供匹配该签名的方法,该方法需要返回void。
有许多原因认为异步void方法不好,文章建议在任何可能的情况下都要避免使用它,因此分析器已经出现来标记使用它们的情况。其中最大的问题之一是委托推断。考虑以下程序:
using System.Diagnostics; Time(async () => { Console.WriteLine("Enter"); await Task.Delay(TimeSpan.FromSeconds(10)); Console.WriteLine("Exit"); }); static void Time(Action action) { Console.WriteLine("Timing..."); Stopwatch sw = Stopwatch.StartNew(); action(); Console.WriteLine($"...done timing: {sw.Elapsed}"); }人们很容易期望这个程序的输出时间至少为10秒,但是如果您运行它,您会发现像这样的输出:
Timing... Enter ...done timing: 00:00:00.0037550嗯?当然,基于我们在本篇文章中讨论的一切,应该理解问题出在哪里。异步lambda实际上是一个async void方法。异步方法在第一个挂起点时返回给调用者。如果这是一个异步的Task方法,那么返回的就是Task。但是在async void的情况下,没有返回值。Time方法只知道它调用了action(),委托调用返回了;它不知道异步方法实际上仍在“运行”,并且将在以后异步完成。
这就是OperationStarted/OperationCompleted的作用。这些异步void方法在性质上类似于前面讨论过的EAP方法:这些方法的启动是void的,因此您需要另一种机制来跟踪所有这些正在执行的操作。因此,EAP实现在操作启动时调用当前SynchronizationContext的OperationStarted,在完成时调用OperationCompleted。异步void也是如此。与异步void相关联的构建器是AsyncVoidMethodBuilder。还记得在异步方法的入口点中,编译器生成的代码如何调用构建器的静态Create方法来获取一个适当的构建器实例吗?AsyncVoidMethodBuilder利用这一点来挂钩创建并调用OperationStarted:
public static AsyncVoidMethodBuilder Create() { SynchronizationContext? sc = SynchronizationContext.Current; sc?.OperationStarted(); return new AsyncVoidMethodBuilder() { _synchronizationContext = sc }; }同样地,当构建器通过SetResult或SetException标记为完成时,它会调用相应的OperationCompleted方法。这就是为什么像xunit这样的单元测试框架能够拥有异步void测试方法,并且仍然可以在并发测试执行中使用最大程度的并发度的原因,例如在xunit的AsyncTestSyncContext中。
有了这些知识,我们现在可以重写我们的计时示例:
using System.Diagnostics; Time(async () => { Console.WriteLine("Enter"); await Task.Delay(TimeSpan.FromSeconds(10)); Console.WriteLine("Exit"); }); static void Time(Action action) { var oldCtx = SynchronizationContext.Current; try { var newCtx = new CountdownContext(); SynchronizationContext.SetSynchronizationContext(newCtx); Console.WriteLine("Timing..."); Stopwatch sw = Stopwatch.StartNew(); action(); newCtx.SignalAndWait(); Console.WriteLine($"...done timing: {sw.Elapsed}"); } finally { SynchronizationContext.SetSynchronizationContext(oldCtx); } } sealed class CountdownContext : SynchronizationContext { private readonly ManualResetEventSlim _mres = new ManualResetEventSlim(false); private int _remaining = 1; public override void OperationStarted() => Interlocked.Increment(ref _remaining); public override void OperationCompleted() { if (Interlocked.Decrement(ref _remaining) == 0) { _mres.Set(); } } public void SignalAndWait() { OperationCompleted(); _mres.Wait(); } }在这里,我创建了一个同步上下文,用于跟踪挂起操作的计数,并支持阻止等待它们全部完成。当我运行它时,我会得到类似以下的输出:
Timing... Enter Exit ...done timing: 00:00:10.0149074状态机字段
到目前为止,我们已经看到了生成的入口方法以及MoveNext实现中的所有内容。我们还瞥见了状态机上定义的一些字段。让我们更仔细地看看这些。
对于之前显示的CopyStreamToStream方法:
public async Task CopyStreamToStreamAsync(Stream source, Stream destination) { var buffer = new byte[0x1000]; int numRead; while ((numRead = await source.ReadAsync(buffer, 0, buffer.Length)) != 0) { await destination.WriteAsync(buffer, 0, numRead); } }这些是我们最终得到的字段:
private struct <CopyStreamToStreamAsync>d__0 : IAsyncStateMachine { public int <>1__state; public AsyncTaskMethodBuilder <>t__builder; public Stream source; public Stream destination; private byte[] <buffer>5__2; private TaskAwaiter <>u__1; private TaskAwaiter<int> <>u__2; ... }它们分别是什么呢?
- <>1__state. 这是“状态机”中的“状态”。“state”定义了状态机的当前状态,最重要的是,下一次调用MoveNext时应该执行什么。如果状态为-2,则操作已完成。如果状态为-1,则要么我们即将第一次调用MoveNext,要么MoveNext代码当前正在某个线程上运行。如果您正在调试异步方法的处理过程,并且看到状态为-1,则意味着某个线程实际上正在执行方法中包含的代码。如果状态为0或更高,则该方法已暂停,并且状态的值告诉您它暂停在哪个await处。虽然这不是一条硬性规则(某些代码模式可能会混淆编号),但通常分配的状态与源代码自上而下排序中await的基于0的编号相对应。因此,例如,如果异步方法的主体完全是:
await A(); await B(); await C(); await D();如果你发现状态值为2,那几乎可以确定异步方法当前已经暂停,正在等待从C()返回的任务完成。<>t__builder。这是状态机的生成器,例如AsyncTaskMethodBuilder用于Task,AsyncValueTaskMethodBuilder<TResult>用于ValueTask<TResult>,AsyncVoidMethodBuilder用于异步void方法,或者在异步返回类型上使用[AsyncMethodBuilder(...)]声明以供使用的任何构建器,或者通过此类属性在异步方法本身上进行覆盖。如前所述,生成器负责异步方法的生命周期,包括创建返回任务、最终完成该任务,并作为中介器进行暂停,异步方法中的代码要求生成器暂停,直到特定的awaiter完成。源/目标。这些是方法参数。你可以通过它们来判断,因为它们没有被重命名,编译器按照参数名称指定的方式对它们进行了命名。正如之前提到的那样,所有被方法体使用的参数都需要存储到状态机中,以便MoveNext方法可以访问它们。请注意,我说的是“被使用的”。如果编译器发现一个参数在异步方法的方法体中未被使用,它可以优化掉存储该字段的需要。例如,给定以下方法:
public async Task M(int someArgument) { await Task.Yield(); }编译器将在状态机中发出这些字段:
private struct <M>d__0 : IAsyncStateMachine { public int <>1__state; public AsyncTaskMethodBuilder <>t__builder; private YieldAwaitable.YieldAwaiter <>u__1; ... }请注意,没有名为someArgument的字段。但是,如果我们更改异步方法以任何方式使用该参数:
public async Task M(int someArgument) { Console.WriteLine(someArgument); await Task.Yield(); }它就会出现:
private struct <M>d__0 : IAsyncStateMachine { public int <>1__state; public AsyncTaskMethodBuilder <>t__builder; public int someArgument; private YieldAwaitable.YieldAwaiter <>u__1; ... }- <buffer>5__2;. 这是缓冲区“local”,它被提升为字段,以便可以在await点之间保持其状态。编译器会尽量避免不必要地提升状态。需要注意的是,源代码中还有另一个本地变量numRead,但状态机中没有相应的字段。为什么?因为这不是必要的。该本地变量被设置为ReadAsync调用的结果,然后用作WriteAsync调用的输入。在这两者之间没有await,也没有跨越其中的numRead值需要被存储。就像在同步方法中JIT编译器可以选择将这样的值完全存储在寄存器中,而从未将其溢出到堆栈中一样,C#编译器可以避免将此本地变量提升为字段,因为它不需要在任何await中保留其值。通常情况下,如果C#编译器能够证明它们的值不需要在await中保留,它可以省略提升本地变量。
- <>u1和<>u2。异步方法中有两个await:一个是由ReadAsync返回的Task<int>,另一个是由WriteAsync返回的Task。Task.GetAwaiter()返回TaskAwaiter,Task<TResult>.GetAwaiter()返回TaskAwaiter<TResult>,两者都是不同的结构体类型。由于编译器需要在await之前获取这些等待者(IsCompleted,UnsafeOnCompleted),然后需要在await之后访问它们(GetResult),因此需要存储等待者。由于它们是不同的结构体类型,编译器需要维护两个单独的字段来存储它们(另一种选择是将它们装箱并为等待者创建一个单独的对象字段,但这会导致额外的分配成本)。然而,编译器会尽可能地重用字段。如果有:
public async Task M() { await Task.FromResult(1); await Task.FromResult(true); await Task.FromResult(2); await Task.FromResult(false); await Task.FromResult(3); }这里有五种等待,但只涉及两种不同类型的等待者:三个是TaskAwaiter<int>,两个是TaskAwaiter<bool>。因此,在状态机上只有两个等待者字段:
private struct <M>d__0 : IAsyncStateMachine { public int <>1__state; public AsyncTaskMethodBuilder <>t__builder; private TaskAwaiter<int> <>u__1; private TaskAwaiter<bool> <>u__2; ... }然后,如果我将我的示例更改为:
public async Task M() { await Task.FromResult(1); await Task.FromResult(true); await Task.FromResult(2).ConfigureAwait(false); await Task.FromResult(false).ConfigureAwait(false); await Task.FromResult(3); }仍然只涉及Task<int>和Task<bool>,但实际上我使用了四种不同的结构体等待类型,因为在ConfigureAwait返回的内容上调用GetAwaiter()返回的等待者类型与Task.GetAwaiter()返回的不同...这再次可以从编译器创建的等待者字段中看出:
private struct <M>d__0 : IAsyncStateMachine { public int <>1__state; public AsyncTaskMethodBuilder <>t__builder; private TaskAwaiter<int> <>u__1; private TaskAwaiter<bool> <>u__2; private ConfiguredTaskAwaitable<int>.ConfiguredTaskAwaiter <>u__3; private ConfiguredTaskAwaitable<bool>.ConfiguredTaskAwaiter <>u__4; ... }如果你想优化与异步状态机相关的大小,你可以看看是否可以合并正在等待的事物的类型,从而合并这些等待者字段。
在状态机中,可能会定义其他类型的字段。特别是,你可能会看到一些包含“wrap”一词的字段。考虑下面这个愚蠢的例子:
public async Task<int> M() => await Task.FromResult(42) + DateTime.Now.Second;
这将产生一个具有以下字段的状态机:
private struct <M>d__0 : IAsyncStateMachine { public int <>1__state; public AsyncTaskMethodBuilder<int> <>t__builder; private TaskAwaiter<int> <>u__1; ... }到目前为止还没有什么特别的。现在反转被添加表达式的顺序:
public async Task<int> M() => DateTime.Now.Second + await Task.FromResult(42);
这样,你就会得到这些字段:
private struct <M>d__0 : IAsyncStateMachine { public int <>1__state; public AsyncTaskMethodBuilder<int> <>t__builder; private int <>7__wrap1; private TaskAwaiter<int> <>u__1; ... }现在我们有了一个额外的字段:<>7wrap1。为什么?因为我们计算了DateTime.Now.Second的值,只有在计算完之后,我们才需要等待某些东西,而第一个表达式的值需要被保留,以便将其添加到第二个表达式的结果中。因此,编译器需要确保该第一个表达式的临时结果可用于添加到await的结果中,这意味着它需要将表达式的结果溢出到一个临时变量中,它使用这个<>7wrap1字段来实现。如果你发现自己在极度优化异步方法实现以降低分配的内存量,你可以寻找这样的字段,并查看是否可以通过对源代码进行小的调整来避免需要溢出,从而避免需要这样的临时变量。
总结
希望这篇文章能够帮助你了解在使用async/await时发生的具体情况,但幸运的是,你通常不需要知道或关心这些。这里有很多流动的部分,它们共同创造了一种有效的解决方案,可以编写可扩展的异步代码,而不必处理回调地狱。然而,最终这些部分实际上是相对简单的:任何异步操作的通用表示,一种能够将正常控制流重写为协程状态机实现的语言和编译器,以及将它们全部绑在一起的模式。其他所有东西都是优化的加成。




