- A+
每个版本必有的性能提升汇总文章又来了。大家可以学习阅读了。
微软 .NET 开发团队的工程师 Stephen Toub 发表博客《Performance Improvements in .NET 8》,详细介绍了 .NET 8 中的性能改进。

一言蔽之:
.NET 7 was super fast. .NET 8 is faster.
.NET 8 比 .NET 7 的超级快更快!
这篇博客全方位介绍了 .NET 8 的性能表现,包括 JIT、原生 AOT、VM、GC、Mono、线程、文件 I/O、网络、JSON 处理、日志等。
- JIT
- Native AOT
- VM
- GC
- Mono
- Threading
- Reflection
- Exceptions
- Primitives
- Strings, Arrays, and Spans
- Collections
- File I/O
- Networking
- JSON
- Cryptography
- Logging
- Configuration
- Peanut Butter
Benchmarking Setup
基准设置
在本文中,将使用微基准来突出讨论的改进方面。这些微基准大多使用BenchmarkDotNet v0.13.8实现,除非另有说明,否则每个基准都有一个简单的设置。
要跟随进行,首先确保您已安装.NET 7和.NET 8。在本文中,我使用的是.NET 8 Release Candidate(8.0.0-rc.1.23419.4)。
完成这些先决条件后,在一个新的基准目录中创建一个新的C#项目:
dotnet new console -o benchmarks cd benchmarks
该目录将包含两个文件:benchmarks.csproj(包含有关应该如何构建应用程序的信息的项目文件)和Program.cs(应用程序的代码)。将benchmarks.csproj的全部内容替换为以下内容:
Exe net8.0;net7.0 Preview enable true true
上述项目文件告诉构建系统我们想要:
构建一个可运行的应用程序(而不是库), 能够在.NET 8和.NET 7上运行(以便BenchmarkDotNet可以运行多个进程,一个使用.NET 7,一个使用.NET 8,以便能够比较结果), 尽管C# 12尚未正式发布,但能够使用C#语言的所有最新功能, 自动导入常用命名空间, 在代码中能够使用unsafe关键字, 并将垃圾回收器(GC)配置为“服务器”配置,这影响它在内存消耗和吞吐量之间做出的权衡(这不是严格必需的,我只是习惯使用它,并且对于ASP.NET应用程序来说,这是默认配置)。
最后的从NuGet中引入BenchmarkDotNet,以便我们能够在Program.cs中使用该库。(一些基准需要添加其他包;我已经在适用的位置做了说明。)
然后,我将每个基准的完整Program.cs源代码包含在了里面;只需将该代码复制并粘贴到Program.cs中,替换其全部内容。在每个测试中,您会注意到几个属性可以应用于Tests类。[内存诊断器]属性表示我想跟踪托管分配,[反汇编诊断器]属性表示我想报告实际为测试生成的汇编代码(默认情况下还有一个层级的函数调用),[隐藏列]属性仅仅抑制了BenchmarkDotNet可能默认输出但对我们在这里的目的无关紧要的一些数据列。
然后,运行基准非常简单。每个显示的测试还包括一个以dotnet命令开头的注释,用于运行基准测试。通常是这样的:
dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
上述dotnet run命令:
以发布版本构建基准。这对性能测试很重要,因为大多数优化在调试构建中都被禁用了,包括C#编译器和JIT编译器。 针对主机项目选择的是.NET 7。通常情况下,对于BenchmarkDotNet,您需要针对您将执行的所有运行时的最低公共标准进行目标设定,以确保所有被使用的API在需要的地方都可用。 运行整个程序中的所有基准。--filter参数可以缩小范围,仅对所需基准的子集进行范围限制,但“*”表示“运行所有基准”。 在.NET 7和.NET 8上运行测试。
整篇文章中,我展示了许多基准和我运行它们时得到的结果。所有的代码在所有支持的操作系统和架构上都运行良好。除非另有说明,否则所示的基准结果均来自在Linux(Ubuntu 22.04)上(一个x64处理器)运行时的结果(唯一的例外是当我使用[反汇编诊断器]显示汇编代码时,我在Windows 11上运行了它们,因为在Unix上使用[反汇编诊断器]运行.NET 7并不总是产生所请求的汇编)。我的标准警告:这些是微基准,通常测量非常短的操作时间,并且当这些时间的改进通过一遍又一遍的执行而累积起来时,其影响是显著的。不同的硬件、不同的操作系统、您的计算机上运行的其他内容、您当前的心情以及您早餐吃了什么都可能影响涉及的数字。简而言之,不要指望您看到的数字与我在这里报告的数字完全匹配,尽管我选择的示例中,所引用的差异的数量级可完全重现。
解释完了,我们开始吧...”
全文请看: Performance Improvements in .NET 8 - .NET Blog (microsoft.com)
JIT
Code generation permeates every single line of code we write, and it’s critical to the end-to-end performance of applications that the compiler doing that code generation achieves high code quality. In .NET, that’s the job of the Just-In-Time (JIT) compiler, which is used both “just in time” as an application executes as well as in Ahead-Of-Time (AOT) scenarios as the workhorse to perform the codegen at build-time. Every release of .NET has seen significant improvements in the JIT, and .NET 8 is no exception. In fact, I dare say the improvements in .NET 8 in the JIT are an incredible leap beyond what was achieved in the past, in large part due to dynamic PGO…
Tiering and Dynamic PGO
To understand dynamic PGO, we first need to understand “tiering.” For many years, a .NET method was only ever compiled once: on first invocation of the method, the JIT would kick in to generate code for that method, and then that invocation and every subsequent one would use that generated code. It was a simple time, but also one frought with conflict… in particular, a conflict between how much the JIT should invest in code quality for the method and how much benefit would be gained from that enhanced code quality. Optimization is one of the most expensive things a compiler does; a compiler can spend an untold amount of time searching for additional ways to shave off an instruction here or improve the instruction sequence there. But none of us has an infinite amount of time to wait for the compiler to finish, especially in a “just in time” scenario where the compilation is happening as the application is running. As such, in a world where a method is compiled once for that process, the JIT has to either pessimize code quality or pessimize how long it takes to run, which means a tradeoff between steady-state throughput and startup time.
As it turns out, however, the vast majority of methods invoked in an application are only ever invoked once or a small number of times. Spending a lot of time optimizing such methods would actually be a deoptimization, as likely it would take much more time to optimize them than those optimizations would gain. So, .NET Core 3.0 introduced a new feature of the JIT known as “tiered compilation.” With tiering, a method could end up being compiled multiple times. On first invocation, the method would be compiled in “tier 0,” in which the JIT prioritizes speed of compilation over code quality; in fact, the mode the JIT uses is often referred to as “min opts,” or minimal optimization, because it does as little optimization as it can muster (it still maintains a few optimizations, primarily the ones that result in less code to be compiled such that the JIT actually runs faster). In addition to minimizing optimizations, however, it also employs call counting “stubs”; when you invoke the method, the call goes through a little piece of code (the stub) that counts how many times the method was invoked, and once that count crosses a predetermined threshold (e.g. 30 calls), the method gets queued for re-compilation, this time at “tier 1,” in which the JIT throws every optimization it’s capable of at the method. Only a small subset of methods make it to tier 1, and those that do are the ones worthy of additional investment in code quality. Interestingly, there are things the JIT can learn about the method from tier 0 that can lead to even better tier 1 code quality than if the method had been compiled to tier 1 directly. For example, the JIT knows that a method “tiering up” from tier 0 to tier 1 has already been executed, and if it’s already been executed, then any static readonly fields it accesses are now already initialized, which means the JIT can look at the values of those fields and base the tier 1 code gen on what’s actually in the field (e.g. if it’s a static readonly bool, the JIT can now treat the value of that field as if it were const bool). If the method were instead compiled directly to tier 1, the JIT might not be able to make the same optimizations. Thus, with tiering, we can “have our cake and eat it, too.” We get both good startup and good throughput. Mostly…
One wrinkle to this scheme, however, is the presence of longer-running methods. Methods might be important because they’re invoked many times, but they might also be important because they’re invoked only a few times but end up running forever, in particular due to looping. As such, tiering was disabled by default for methods containing backward branches, such that those methods would go straight to tier 1. To address that, .NET 7 introduced On-Stack Replacement (OSR). With OSR, the code generated for loops also included a counting mechanism, and after a loop iterated to a certain threshold, the JIT would compile a new optimized version of the method and jump from the minimally-optimized code to continue execution in the optimized variant. Pretty slick, and with that, in .NET 7 tiering was also enabled for methods with loops.
But why is OSR important? If there are only a few such long-running methods, what’s the big deal if they just go straight to tier 1? Surely startup isn’t significantly negatively impacted? First, it can be: if you’re trying to trim milliseconds off startup time, every method counts. But second, as noted before, there are throughput benefits to going through tier 0, in that there are things the JIT can learn about a method from tier 0 which can then improve its tier 1 compilation. And the list of things the JIT can learn gets a whole lot bigger with dynamic PGO.
Profile-Guided Optimization (PGO) has been around for decades, for many languages and environments, including in .NET world. The typical flow is you build your application with some additional instrumentation, you then run your application on key scenarios, you gather up the results of that instrumentation, and then you rebuild your application, feeding that instrumentation data into the optimizer, allowing it to use the knowledge about how the code executed to impact how it’s optimized. This approach is often referred to as “static PGO.” “Dynamic PGO” is similar, except there’s no effort required around how the application is built, scenarios it’s run on, or any of that. With tiering, the JIT is already generating a tier 0 version of the code and then a tier 1 version of the code… why not sprinkle some instrumentation into the tier 0 code as well? Then the JIT can use the results of that instrumentation to better optimize tier 1. It’s the same basic “build, run and collect, re-build” flow as with static PGO, but now on a per-method basis, entirely within the execution of the application, and handled automatically for you by the JIT, with zero additional dev effort required and zero additional investment needed in build automation or infrastructure.
Dynamic PGO first previewed in .NET 6, off by default. It was improved in .NET 7, but remained off by default. Now, in .NET 8, I’m thrilled to say it’s not only been significantly improved, it’s now on by default. This one-character PR to enable it might be the most valuable PR in all of .NET 8: dotnet/runtime#86225.
There have been a multitude of PRs to make all of this work better in .NET 8, both on tiering in general and then on dynamic PGO in particular. One of the more interesting changes is dotnet/runtime#70941, which added more tiers, though we still refer to the unoptimized as “tier 0” and the optimized as “tier 1.” This was done primarily for two reasons. First, instrumentation isn’t free; if the goal of tier 0 is to make compilation as cheap as possible, then we want to avoid adding yet more code to be compiled. So, the PR adds a new tier to address that. Most code first gets compiled to an unoptimized and uninstrumented tier (though methods with loops currently skip this tier). Then after a certain number of invocations, it gets recompiled unoptimized but instrumented. And then after a certain number of invocations, it gets compiled as optimized using the resulting instrumentation data. Second, crossgen/ReadyToRun (R2R) images were previously unable to participate in dynamic PGO. This was a big problem for taking full advantage of all that dynamic PGO offers, in particular because there’s a significant amount of code that every .NET application uses that’s already R2R’d: the core libraries. ReadyToRun is an AOT technology that enables most of the code generation work to be done at build-time, with just some minimal fix-ups applied when that precompiled code is prepared for execution. That code is optimized and not instrumented, or else the instrumentation would slow it down. So, this PR also adds a new tier for R2R. After an R2R method has been invoked some number of times, it’s recompiled, again with optimizations but this time also with instrumentation, and then when that’s been invoked sufficiently, it’s promoted again, this time to an optimized implementation utilizing the instrumentation data gathered in the previous tier. 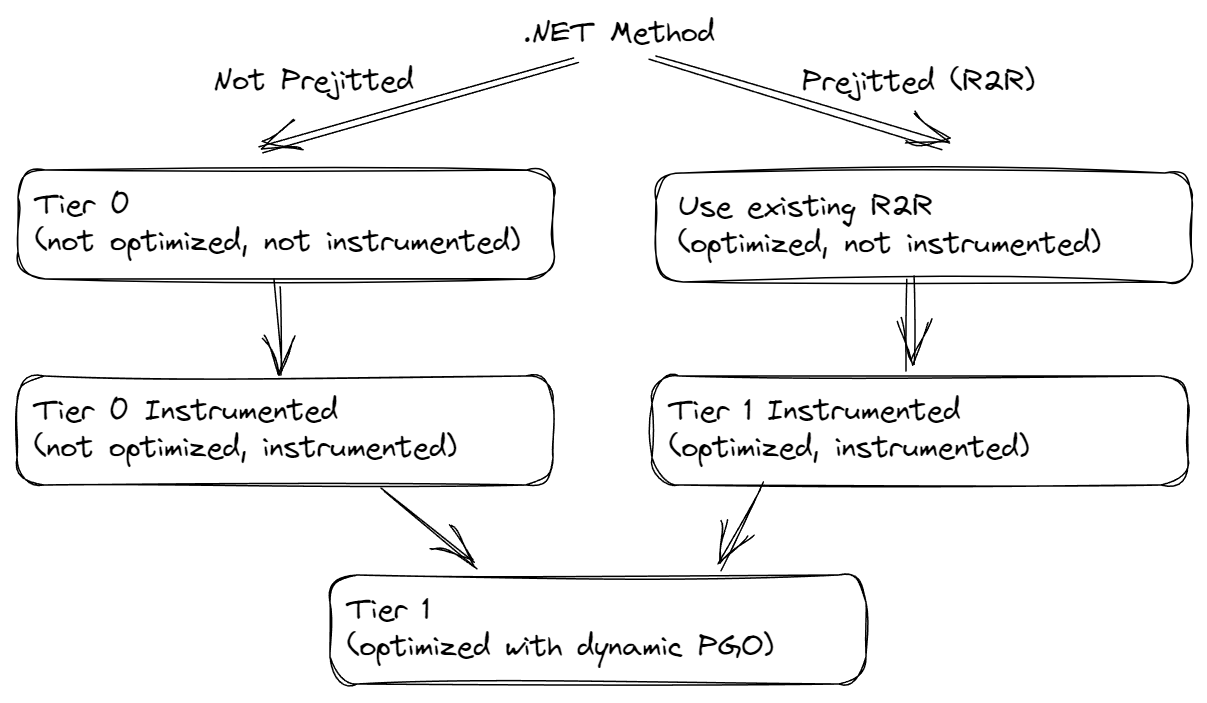
There have also been multiple changes focused on doing more optimization in tier 0. As noted previously, the JIT wants to be able to compile tier 0 as quickly as possible, however some optimizations in code quality actually help it to do that. For example, dotnet/runtime#82412 teaches it to do some amount of constant folding (evaluating constant expressions at compile time rather than at execution time), as that can enable it to generate much less code. Much of the time the JIT spends compiling in tier 0 is for interactions with the Virtual Machine (VM) layer of the .NET runtime, such as resolving types, and so if it can significantly trim away branches that won’t ever be used, it can actually speed up tier 0 compilation while also getting better code quality. We can see this with a simple repro app like the following:
// dotnet run -c Release -f net8.0 MaybePrint(42.0); static void MaybePrint<T>(T value) { if (value is int) Console.WriteLine(value); }I can set the DOTNET_JitDisasm environment variable to *MaybePrint*; that will result in the JIT printing out to the console the code it emits for this method. On .NET 7, when I run this (dotnet run -c Release -f net7.0), I get the following tier 0 code:
; Assembly listing for method Program:<<Main>$>g__MaybePrint|0_0[double](double) ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-0 compilation ; MinOpts code ; rbp based frame ; partially interruptible G_M000_IG01: ;; offset=0000H 55 push rbp 4883EC30 sub rsp, 48 C5F877 vzeroupper 488D6C2430 lea rbp, [rsp+30H] 33C0 xor eax, eax 488945F8 mov qword ptr [rbp-08H], rax C5FB114510 vmovsd qword ptr [rbp+10H], xmm0 G_M000_IG02: ;; offset=0018H 33C9 xor ecx, ecx 85C9 test ecx, ecx 742D je SHORT G_M000_IG03 48B9B877CB99F97F0000 mov rcx, 0x7FF999CB77B8 E813C9AE5F call CORINFO_HELP_NEWSFAST 488945F8 mov gword ptr [rbp-08H],