- A+
QEMU直接从tap/tun取数据
QEMU tap数据接收步骤:
- qemu从tun取数据包
- qemu将数据包放入virtio硬件网卡。
- qemu触发中断。
- 虚拟机收到中断,从virtio读取数据。
在qemu中步骤1(tap_read_packet)和步骤2(qemu_send_packet_async)都是在tap_send中完成的,其中步骤2是异步流程。
qemu/net/tap.c static void tap_send(void *opaque) { TAPState *s = opaque; int size; int packets = 0; while (true) { uint8_t *buf = s->buf; uint8_t min_pkt[ETH_ZLEN]; size_t min_pktsz = sizeof(min_pkt); size = tap_read_packet(s->fd, s->buf, sizeof(s->buf)); if (size <= 0) { break; } if (s->host_vnet_hdr_len && !s->using_vnet_hdr) { buf += s->host_vnet_hdr_len; size -= s->host_vnet_hdr_len; } if (net_peer_needs_padding(&s->nc)) { if (eth_pad_short_frame(min_pkt, &min_pktsz, buf, size)) { buf = min_pkt; size = min_pktsz; } } size = qemu_send_packet_async(&s->nc, buf, size, tap_send_completed); if (size == 0) { tap_read_poll(s, false); break; } else if (size < 0) { break; } /* * When the host keeps receiving more packets while tap_send() is * running we can hog the QEMU global mutex. Limit the number of * packets that are processed per tap_send() callback to prevent * stalling the guest. */ packets++; if (packets >= 50) { break; } } } 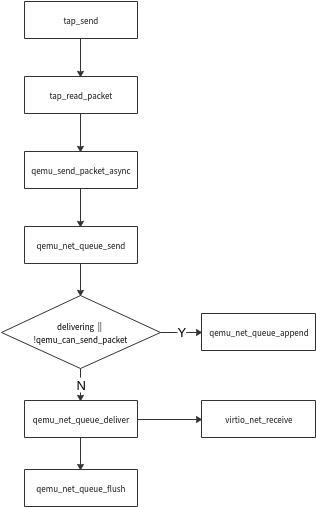
qemu通过qemu_net_queue_deliver将数据包发送到virtio_queue,在发送之前若delivering或!qemu_can_send_packet满足,则先将数据包加入packets队列,随后在qemu_net_queue_flush阶段将数据包发送到virtio_queue中,上图中virtio_net_receive就到达virtio虚拟硬件网卡了。

QEMU通过vhost-net从tap/tun取数据
vhost-net驱动加载时会生成/dev/vhost-net设备。
qemu-kvm启动时会open设备/dev/vhost-net,将调用vhost_net_open完成这个过程,vhost_net_open会进行handle_tx_net、handle_rx_net poll函数的初始化。
handle_tx_net、handle_rx_net最终会调用tun_recvmsg、tun_sendmsg进行数据收发。
/drivers/vhost/net.c: static int vhost_net_open(struct inode *inode, struct file *f) { ... ... vhost_poll_init(n->poll + VHOST_NET_VQ_TX, handle_tx_net, EPOLLOUT, dev); vhost_poll_init(n->poll + VHOST_NET_VQ_RX, handle_rx_net, EPOLLIN, dev); ... ... } static void handle_rx_net(struct vhost_work *work) { struct vhost_net *net = container_of(work, struct vhost_net, poll[VHOST_NET_VQ_RX].work); handle_rx(net); } handle_rx函数中recvmsg完成从tun取数据,通过copy_to_iter将msg放入virtio_queue,最后vhost_add_used_and_signal_n实现通知机制,qemu收到数据。
static void handle_rx(struct vhost_net *net) { ... ... err = sock->ops->recvmsg(sock, &msg, sock_len, MSG_DONTWAIT | MSG_TRUNC); ... ... num_buffers = cpu_to_vhost16(vq, headcount); if (likely(mergeable) && copy_to_iter(&num_buffers, sizeof num_buffers, &fixup) != sizeof num_buffers) { vq_err(vq, "Failed num_buffers write"); vhost_discard_vq_desc(vq, headcount); break; } vhost_add_used_and_signal_n(&net->dev, vq, vq->heads, headcount); ... ... } vhost_net通过vhost_worker内核线程进行工作队列的调度用于完成poll,vhost_worker内核线程是qemu通过vhost_dev_ioctl VHOST_SET_OWNER时创建的。
drivers/vhost/vhost.c: static int vhost_poll_wakeup(wait_queue_entry_t *wait, unsigned mode, int sync, void *key) { struct vhost_poll *poll = container_of(wait, struct vhost_poll, wait); if (!(key_to_poll(key) & poll->mask)) return 0; vhost_poll_queue(poll); return 0; } void vhost_work_init(struct vhost_work *work, vhost_work_fn_t fn) { clear_bit(VHOST_WORK_QUEUED, &work->flags); work->fn = fn; } EXPORT_SYMBOL_GPL(vhost_work_init); /* Init poll structure */ void vhost_poll_init(struct vhost_poll *poll, vhost_work_fn_t fn, __poll_t mask, struct vhost_dev *dev) { init_waitqueue_func_entry(&poll->wait, vhost_poll_wakeup); init_poll_funcptr(&poll->table, vhost_poll_func); poll->mask = mask; poll->dev = dev; poll->wqh = NULL; vhost_work_init(&poll->work, fn); } EXPORT_SYMBOL_GPL(vhost_poll_init); static int vhost_worker(void *data) { ... ... for (;;) { ... ... node = llist_del_all(&dev->work_list); if (!node) schedule(); node = llist_reverse_order(node); /* make sure flag is seen after deletion */ smp_wmb(); llist_for_each_entry_safe(work, work_next, node, node) { clear_bit(VHOST_WORK_QUEUED, &work->flags); __set_current_state(TASK_RUNNING); work->fn(work); if (need_resched()) schedule(); } ... ... } ... ... } long vhost_dev_set_owner(struct vhost_dev *dev) { ... ... worker = kthread_create(vhost_worker, dev, "vhost-%d", current->pid); ... ... } long vhost_dev_ioctl(struct vhost_dev *d, unsigned int ioctl, void __user *argp) { ... ... if (ioctl == VHOST_SET_OWNER) { r = vhost_dev_set_owner(d); goto done; } ... ... } drivers/vhost/net.c: static long vhost_net_ioctl(struct file *f, unsigned int ioctl, unsigned long arg) { ... ... switch (ioctl) { ... ... case VHOST_RESET_OWNER: return vhost_net_reset_owner(n); case VHOST_SET_OWNER: return vhost_net_set_owner(n); default: mutex_lock(&n->dev.mutex); r = vhost_dev_ioctl(&n->dev, ioctl, argp); if (r == -ENOIOCTLCMD) r = vhost_vring_ioctl(&n->dev, ioctl, argp); else vhost_net_flush(n); mutex_unlock(&n->dev.mutex); return r; } } static long vhost_net_set_owner(struct vhost_net *n) { ... ... r = vhost_dev_set_owner(&n->dev); ... ... return r; } static const struct file_operations vhost_net_fops = { .owner = THIS_MODULE, .release = vhost_net_release, .read_iter = vhost_net_chr_read_iter, .write_iter = vhost_net_chr_write_iter, .poll = vhost_net_chr_poll, .unlocked_ioctl = vhost_net_ioctl, #ifdef CONFIG_COMPAT .compat_ioctl = vhost_net_compat_ioctl, #endif .open = vhost_net_open, .llseek = noop_llseek, }; static struct miscdevice vhost_net_misc = { .minor = VHOST_NET_MINOR, .name = "vhost-net", .fops = &vhost_net_fops, }; static int vhost_net_init(void) { if (experimental_zcopytx) vhost_net_enable_zcopy(VHOST_NET_VQ_TX); return misc_register(&vhost_net_misc); } 附
主机vhost驱动加载时调用vhost_net_init注册一个MISC驱动,生成/dev/vhost-net的设备文件。
主机qemu-kvm启动时调用open对应的vhost_net_open做主要创建队列和收发函数的挂载,接着调用ioctl启动内核线程vhost,做收发包的处理。
主机qemu通过ioctl配置kvm模块,主要设置通信方式,因为主机vhost和virtio只进行报文的传输,kvm进行提醒。
虚拟机virtio模块注册,生成虚拟机的网络设备,配置中断和NAPI。
虚拟机发包流程如下:
直接从应用层走协议栈最后调用发送接口ndo_start_xmit对应的start_xmit,将报文放入发送队列,vp_notify通知kvm。
kvm通过vmx_handle_exit一系列调用到wake_up_process唤醒vhost线程。
vhost模块的线程激活并且拿到报文,在通过之前绑定的发送接口handle_tx_kick进行发送,调用虚拟网卡的tun_sendmsg最终到netif_rx接口进入主机内核协议栈。
虚拟机收包流程如下:
tap设备的ndo_start_xmit对应的tun_net_xmit最终调用到wake_up_process激活vhost线程,调用handle_rx_kick,将报文放入接收队列。
通过一系列的调用到kvm模块的接口kvm_vcpu_kick,向qemu虚拟机注入中断。
虚拟机virtio模块中断调用接口vp_interrupt,调用virtnet_poll,再调用到netif_receive_skb进入虚拟机的协议栈。
资料来源:https://blog.csdn.net/qq_20817327/article/details/106838029




