- A+
前言:
在当今信息化社会,网络数据分析越来越受到重视。而作为开发人员,掌握一门能够抓取网页内容的语言显得尤为重要。在此篇文章中,将分享如何使用 .NET构建网络抓取工具。详细了解如何执行 HTTP 请求来下载要抓取的网页,然后从其 DOM 树中选择 HTML 元素,进行匹配需要的字段信息,从中提取数据。
一、准备工作:
创建项目:
创建一个简单的Winfrom客户端程序,我使用的是.NET 5.0框架。为使项目显得条理清晰,此处进行了项目分层搭建项目,也就是多建立几个几个类库罢了,然后进行引用。
项目结构:
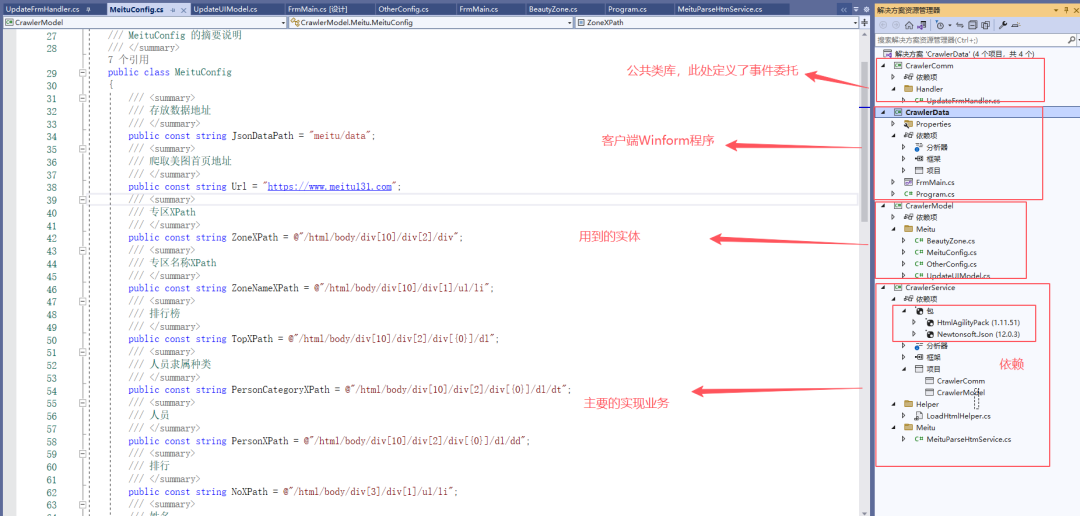
客户端界面设计:

NuGet添加引用类库HtmlAgilityPack:
HtmlAgilityPack是一个开源的C#库,它允许你解析HTML文档,从公DOM中选择元素并提取数据。该工具基本上提供了抓取静态内容网站所需要的一切。这是一个敏捷的HTML解析器,它构建了一个读和写DOM,并支持普通的XPATH或XSLT,你实际上不必了解XPATH也不必了解XSLT就可以使用它。它是一个.NET代码库,允许你解析“Web外”的HTML文件。解析器对“真实世界”中格式错误的HTML非常宽容。对象模型与System.Xml非常相似,但适用于HTML文档或流。
NuGet安装引用:
dotnet add package HtmlAgilityPack --version 1.11.51 二、实现核心代码:
设计定义实体:
网站爬取信息:
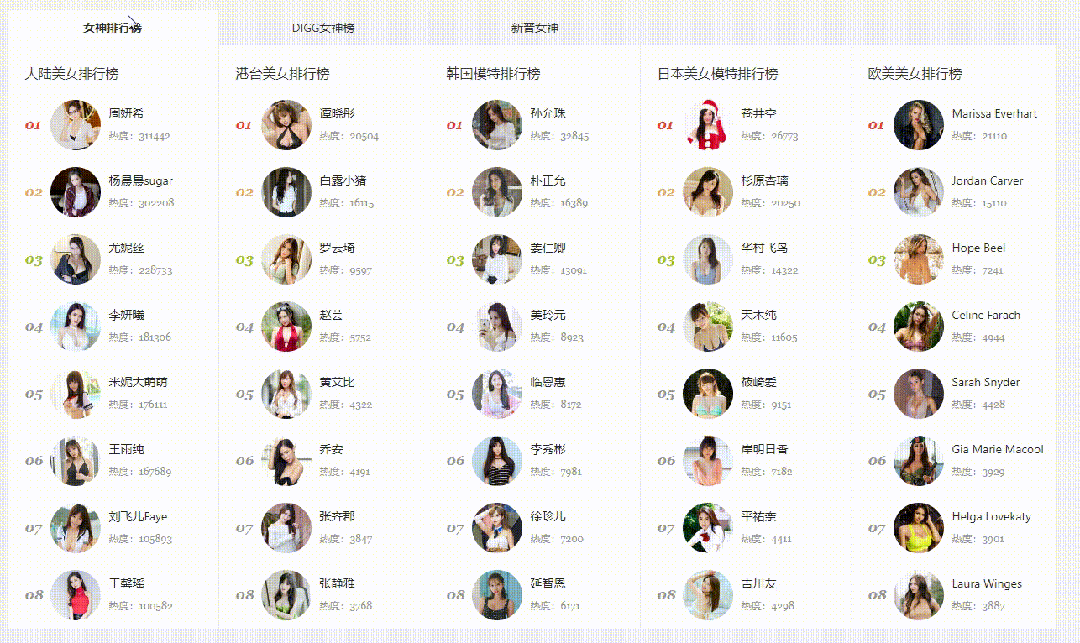
爬取信息实体定义:根据美图的首页展示的信息分析,进行定义爬取字段的信息,定义如下:
#region << 版 本 注 释 >> /*---------------------------------------------------------------- * 创建者:码农阿亮 * 创建时间:2023/8/4 9:58:03 * 版本:V1.0.0 * 描述: * * ---------------------------------------------------------------- * 修改人: * 时间: * 修改说明: * * 版本:V1.0.1 *----------------------------------------------------------------*/ #endregion << 版 本 注 释 >> using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace CrawlerModel.Meitu { /// <summary> /// 爬取的专区字段实体 /// </summary> public class BeautyZone { /// <summary> /// 专区标题 /// </summary> public string Tittle { get; set; } /// <summary> /// 专区每种类型美女排行榜 /// </summary> public List<EveryCategoryBeautyTop> categoryBeauties { get; set; } } /// <summary> /// 每分类美女排行榜 /// </summary> public class EveryCategoryBeautyTop { /// <summary> /// 类别 /// </summary> public string Category { get; set; } /// <summary> /// 每种类型排行榜 /// </summary> public List<Beauty> beauties { get; set; } } /// <summary> /// 美女排行信息 /// </summary> public class Beauty { /// <summary> /// 排行 /// </summary> public string No { get; set; } /// <summary> /// 姓名 /// </summary> public string Name { get; set; } /// <summary> /// 热度 /// </summary> public string Popularity { get; set; } /// <summary> /// 图片地址 /// </summary> public string ImageUrl { get; set; } } } 更新UI界面实体定义:根据客户端需要展示的界面,定义如下:
#region << 版 本 注 释 >> /*---------------------------------------------------------------- * 创建者:码农阿亮 * 创建时间:2023/8/04 16:42:12 * 版本:V1.0.0 * 描述: * * ---------------------------------------------------------------- * 修改人: * 时间: * 修改说明: * * 版本:V1.0.1 *----------------------------------------------------------------*/ #endregion << 版 本 注 释 >> using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace CrawlerModel.Meitu { /// <summary> /// UpdateUIModel 更新UI界面需要的字段 /// </summary> public class UpdateUIModel { /// <summary> /// 下载的数量 /// </summary> public int DownloadNumber { get; set; } /// <summary> /// 分类 /// </summary> public string Category { get; set; } /// <summary> /// 美女写真实体 /// </summary> public Beauty beauty =new Beauty(); } } 匹配DOM标签常量实体: 定义如下:
#region << 版 本 注 释 >> /*---------------------------------------------------------------- * 创建者:码农阿亮 * 创建时间:2023/8/4 10:08:06 * 版本:V1.0.0 * 描述: * * ---------------------------------------------------------------- * 修改人: * 时间: * 修改说明: * * 版本:V1.0.1 *----------------------------------------------------------------*/ #endregion << 版 本 注 释 >> using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace CrawlerModel.Meitu { /// <summary> /// MeituConfig DOM标签常量 /// </summary> public class MeituConfig { /// <summary> /// 存放数据地址 /// </summary> public const string JsonDataPath = "meitu/data"; /// <summary> /// 爬取美图首页地址 /// </summary> public const string Url = "https://www.meitu131.com"; /// <summary> /// 专区XPath /// </summary> public const string ZoneXPath = @"/html/body/div[10]/div[2]/div"; /// <summary> /// 专区名称XPath /// </summary> public const string ZoneNameXPath = @"/html/body/div[10]/div[1]/ul/li"; /// <summary> /// 排行榜 /// </summary> public const string TopXPath = @"/html/body/div[10]/div[2]/div[{0}]/dl"; /// <summary> /// 人员隶属种类 /// </summary> public const string PersonCategoryXPath = @"/html/body/div[10]/div[2]/div[{0}]/dl/dt"; /// <summary> /// 人员 /// </summary> public const string PersonXPath = @"/html/body/div[10]/div[2]/div[{0}]/dl/dd"; /// <summary> /// 排行 /// </summary> public const string NoXPath = @"/html/body/div[3]/div[1]/ul/li"; /// <summary> /// 姓名 /// </summary> public const string NameXPath = @"/html/body/div[3]/div[1]/ul/li"; /// <summary> /// 热度 /// </summary> public const string PopularityXPath = @"/html/body/div[3]/div[1]/ul/li"; /// <summary> /// 图片地址 /// </summary> public const string ImageUrlXPath = @"/html/body/div[3]/div[1]/ul/li"; } } 业务实现代码:
帮助类:Web请求和下载资源帮助方法,定义义如下:
#region << 版 本 注 释 >> /*---------------------------------------------------------------- * 创建者:码农阿亮 * 创建时间:2023/8/4 10:04:16 * 版本:V1.0.0 * 描述: * * ---------------------------------------------------------------- * 修改人: * 时间: * 修改说明: * * 版本:V1.0.1 *----------------------------------------------------------------*/ #endregion << 版 本 注 释 >> using HtmlAgilityPack; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Net; using System.Net.Http; using System.Text; using System.Threading.Tasks; namespace CrawlerService.Helper { /// <summary> /// 创建一个Web请求 /// </summary> public class MyWebClient : WebClient { protected override WebRequest GetWebRequest(Uri address) { HttpWebRequest request = base.GetWebRequest(address) as HttpWebRequest; request.AutomaticDecompression = DecompressionMethods.Deflate | DecompressionMethods.GZip; return request; } } /// <summary> /// 下载HTML帮助类 /// </summary> public static class LoadHtmlHelper { /// <summary> /// 从Url地址下载页面 /// </summary> /// <param name="url"></param> /// <returns></returns> public async static ValueTask<HtmlDocument> LoadHtmlFromUrlAsync(string url) { var data = new MyWebClient()?.DownloadString(url); var doc = new HtmlDocument(); doc.LoadHtml(data); return doc; } /// <summary> /// 获取单个节点扩展方法 /// </summary> /// <param name="htmlDocument">文档对象</param> /// <param name="xPath">xPath路径</param> /// <returns></returns> public static HtmlNode GetSingleNode(this HtmlDocument htmlDocument, string xPath) { return htmlDocument?.DocumentNode?.SelectSingleNode(xPath); } /// <summary> /// 获取多个节点扩展方法 /// </summary> /// <param name="htmlDocument">文档对象</param> /// <param name="xPath">xPath路径</param> /// <returns></returns> public static HtmlNodeCollection GetNodes(this HtmlDocument htmlDocument, string xPath) { return htmlDocument?.DocumentNode?.SelectNodes(xPath); } /// <summary> /// 获取多个节点扩展方法 /// </summary> /// <param name="htmlDocument">文档对象</param> /// <param name="xPath">xPath路径</param> /// <returns></returns> public static HtmlNodeCollection GetNodes(this HtmlNode htmlNode, string xPath) { return htmlNode?.SelectNodes(xPath); } /// <summary> /// 获取单个节点扩展方法 /// </summary> /// <param name="htmlDocument">文档对象</param> /// <param name="xPath">xPath路径</param> /// <returns></returns> public static HtmlNode GetSingleNode(this HtmlNode htmlNode, string xPath) { return htmlNode?.SelectSingleNode(xPath); } /// <summary> /// 下载图片 /// </summary> /// <param name="url">地址</param> /// <param name="filpath">文件路径</param> /// <returns></returns> public async static ValueTask<bool> DownloadImg(string url ,string filpath) { HttpClient httpClient = new HttpClient(); try { var bytes = await httpClient.GetByteArrayAsync(url); using (FileStream fs = File.Create(filpath)) { fs.Write(bytes, 0, bytes.Length); } return File.Exists(filpath); } catch (Exception ex) { throw new Exception("下载图片异常", ex); } } } } 主要业务实现方法:定义如下:
#region << 版 本 注 释 >> /*---------------------------------------------------------------- * 创建者:码农阿亮 * 创建时间:2023/8/4 10:07:17 * 版本:V1.0.0 * 描述: * * ---------------------------------------------------------------- * 修改人: * 时间: * 修改说明: * * 版本:V1.0.1 *----------------------------------------------------------------*/ #endregion << 版 本 注 释 >> using CrawlerComm.Handler; using CrawlerModel.Meitu; using CrawlerService.Helper; using HtmlAgilityPack; using Newtonsoft.Json; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using System.Threading.Tasks; namespace CrawlerService.Meitu { /// <summary> /// MeituParseHtml 的摘要说明 /// </summary> public class MeituParseHtmService { /// <summary> /// json数据文件夹存放文件夹位置 /// </summary> private static string _dataDirectoryPath = Path.Combine(Directory.GetCurrentDirectory(), MeituConfig.JsonDataPath); /// <summary> /// 爬取json数据文件 /// </summary> private static string _CrawlerData = Path.Combine(_dataDirectoryPath, "categories.json"); /// <summary> /// 开始爬取 /// </summary> /// <returns></returns> public async Task StartAsync() { //专区集合 List<BeautyZone> beautyZones = new List<BeautyZone>(); //获取首页Html文档 HtmlDocument htmlDocument = await LoadHtmlHelper.LoadHtmlFromUrlAsync(MeituConfig.Url); //创建存放数据的文件 FileInfo fileInfo = new FileInfo(_CrawlerData); //获取到专区标签 HtmlNodeCollection zoneHtmlNodes = htmlDocument.GetNodes(MeituConfig.ZoneXPath); //专区名称 HtmlNodeCollection zoneNameHtmlNodes = htmlDocument.GetNodes(MeituConfig.ZoneNameXPath); if (zoneHtmlNodes != null && zoneHtmlNodes.Count> 0) { //专区个数 var zoneCount = zoneHtmlNodes.Count; for (int i = 0; i < zoneCount; i++) { //每个专区 BeautyZone beautyZone = new BeautyZone() { Tittle = zoneNameHtmlNodes[i].InnerText, categoryBeauties = new List<EveryCategoryBeautyTop>() }; HtmlNodeCollection topHtmlNodes = htmlDocument.GetNodes(string.Format( MeituConfig.TopXPath,i+1)); if (topHtmlNodes != null && topHtmlNodes.Count > 0) { //每个专区下所有分类 HtmlNodeCollection personCategoryHtmlNodes = htmlDocument.GetNodes(string.Format(MeituConfig.PersonCategoryXPath, i + 1)); //爬取所有人员的标签内容 HtmlNodeCollection personHtmlNodes = htmlDocument.GetNodes(string.Format(MeituConfig.PersonXPath, i + 1)); if (personCategoryHtmlNodes !=null && personHtmlNodes!=null && personCategoryHtmlNodes.Count() > 0) { for (int j = 0; j < personCategoryHtmlNodes.Count(); j++) { //根据每个专区-分类下,进行遍历人气值人员排名 EveryCategoryBeautyTop everyCategoryBeautyTop = new EveryCategoryBeautyTop(); everyCategoryBeautyTop.Category = personCategoryHtmlNodes[j].InnerText; everyCategoryBeautyTop.beauties = new List<Beauty>(); for (int k = 8*j; k < personHtmlNodes.Count(); k++) { var child = personHtmlNodes[k];//每个美女对应的节点信息 var i1 = child.GetSingleNode(child.XPath + "/i");//排名节点 var img = child.GetSingleNode(child.XPath + "/a[1]/div[1]/img[1]");//姓名和图片地址 var span2 = child.GetSingleNode(child.XPath + "/a[1]/div[2]/span[2]");//热度值 //同一类别添加美女到集合 everyCategoryBeautyTop.beauties.Add(new Beauty { No = i1.InnerText, Name = img.GetAttributeValue("alt", "未找到"), Popularity = span2.InnerText, ImageUrl = img.GetAttributeValue("data-echo", "未找到") } ); } //将在同一分区内Top分类添加到集合 beautyZone.categoryBeauties.Add(everyCategoryBeautyTop); } } } beautyZones.Add(beautyZone); } if (beautyZones.Count()> 0) { //爬取数据转Json string beautiesJsonData = JsonConvert.SerializeObject(beautyZones); ; //写入爬取数据数据 string jsonFile = "beauties.json"; WriteData(jsonFile, beautiesJsonData); //下载图片 DownloadImage(beautyZones); } } } /// <summary> /// 写入文件数据 /// </summary> /// <param name="fileName"></param> /// <param name="data"></param> private void WriteData(string fileName, string data) { FileStream fs = new FileStream(fileName, FileMode.OpenOrCreate, FileAccess.Write); StreamWriter sw = new StreamWriter(fs); try { sw.Write(data); } finally { if (sw != null) { sw.Close(); } } } /// <summary> /// 下载图片 /// </summary> /// <param name="beautyZones"></param> private async void DownloadImage(List<BeautyZone> beautyZones) { int count = 0; foreach (var beautyZone in beautyZones) { string rootPath = System.IO.Directory.GetCurrentDirectory() +"\DownloadImg\"+ beautyZone.Tittle; foreach (var category in beautyZone.categoryBeauties) { string downloadPath = rootPath + "\" + category.Category; foreach (var beauty in category.beauties) { count += 1;//下载数量累加 string filePath = downloadPath + "\" + beauty.Name+".jpg"; if (!Directory.Exists(downloadPath)) { Directory.CreateDirectory(downloadPath); } UpdateUIModel updateUIModel = new UpdateUIModel() { DownloadNumber =count, Category = category.Category, beauty = beauty }; //更新UI UpdateFrmHandler.OnUpdateUI(updateUIModel); //异步下载 await LoadHtmlHelper.DownloadImg(beauty.ImageUrl,filePath); } } } } } } 定义委托代码:
更新UI界面的委托事件:定义如下:
#region << 版 本 注 释 >> /*---------------------------------------------------------------- * 创建者:码农阿亮 * 创建时间:2023/8/04 11:28:24 * 版本:V1.0.0 * 描述: * * ---------------------------------------------------------------- * 修改人: * 时间: * 修改说明: * * 版本:V1.0.1 *----------------------------------------------------------------*/ #endregion << 版 本 注 释 >> using CrawlerModel.Meitu; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace CrawlerComm.Handler { /// <summary> /// UpdateFrmHandler 更新UI事件委托 /// </summary> public class UpdateFrmHandler { /// <summary> /// 更新下载界面事件 /// </summary> public static event EventHandler<UpdateUIModel> UpdateUI; public static void OnUpdateUI(UpdateUIModel updateUIModel) { UpdateUI?.Invoke(null, updateUIModel); } } } 客户端执行代码:
点击触发事件:定义如下:
#region << 版 本 注 释 >> /*---------------------------------------------------------------- * 创建者:码农阿亮 * 创建时间:2023/8/4 08:07:17 * 版本:V1.0.0 * 描述: * * ---------------------------------------------------------------- * 修改人: * 时间: * 修改说明: * * 版本:V1.0.1 *----------------------------------------------------------------*/ #endregion << 版 本 注 释 >> using CrawlerComm.Handler; using CrawlerModel.Meitu; using CrawlerService.Meitu; using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.IO; using System.Linq; using System.Net; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; namespace CrawlerData { public partial class FrmMain : Form { public FrmMain() { InitializeComponent(); //订阅委托 UpdateFrmHandler.UpdateUI += UpdateUIFuc; } /// <summary> /// 更新界面委托方法 /// </summary> /// <param name="sender"></param> /// <param name="updateUIModel"></param> private void UpdateUIFuc(object sender, UpdateUIModel updateUIModel ) { try { //改变界面UI中的值 this.Invoke((Action)delegate { UpdateUIBiz(updateUIModel); }); } catch (Exception ex) { } } /// <summary> /// 更新UI界面业务 /// </summary> /// <param name="updateUIModel"></param> private void UpdateUIBiz(UpdateUIModel updateUIModel) { try { //分类 tbCategory.Text = updateUIModel.Category; //排名 tbNo.Text = updateUIModel.beauty.No; //姓名 tbName.Text = updateUIModel.beauty.Name; //人气值 tbPopularity.Text = updateUIModel.beauty.Popularity; //图片地址 tbUrl.Text = updateUIModel.beauty.ImageUrl; //图片 WebClient client = new WebClient(); string imageUrl = updateUIModel.beauty.ImageUrl;// 要显示的网络图片的URL byte[] imageBytes = client.DownloadData(imageUrl); Image img = Image.FromStream(new MemoryStream(imageBytes)); picBox.Image = img; //爬取数量 lbNumber.Text = updateUIModel.DownloadNumber.ToString(); } catch (Exception ex) { } } /// <summary> /// 开始执行按钮点击事件 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void btStart_Click(object sender, EventArgs e) { StartCrawler(); } /// <summary> /// 开始爬取 /// </summary> public async void StartCrawler() { try { MeituParseHtmService meituParseHtml = new MeituParseHtmService(); await meituParseHtml.StartAsync(); } catch (Exception ex ) { } } } } 三、爬取验证:
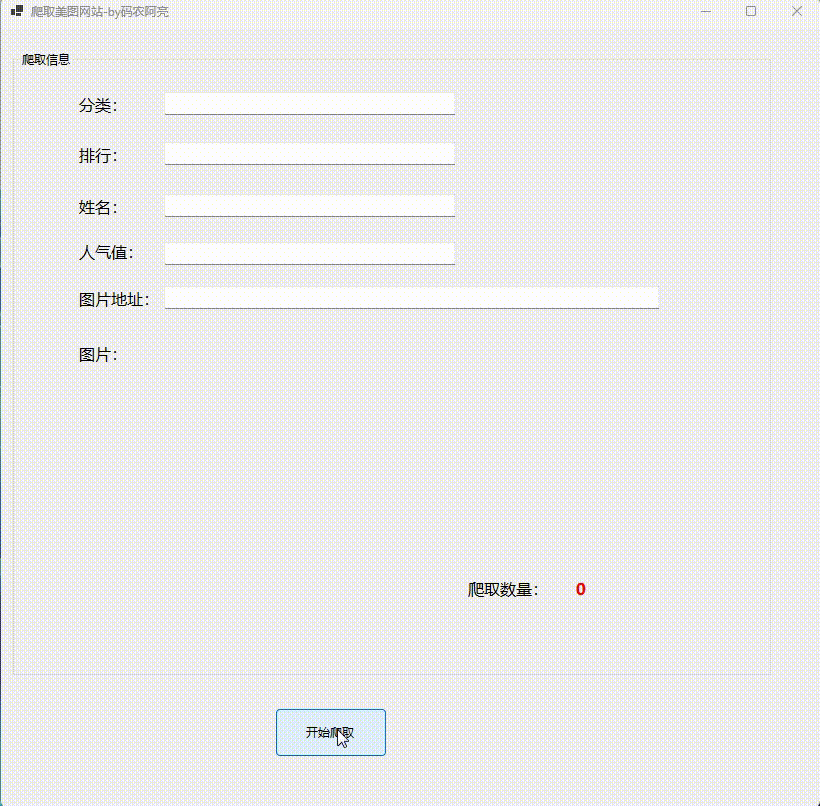
启动客户端:
文章上传图片大小有限制,只截取了部分gif:
爬取的Json数据结果:

下载的图片资源:
分目录层级存放:

源码链接地址:
Gitee完整实例地址:
建群声明:本着技术在于分享,方便大家交流学习的初心,特此建立【编程内功修炼交流群】,热烈欢迎各位爱交流学习的程序员进群,也希望进群的大佬能不吝分享自己遇到的技术问题和学习心得





