- A+
前言
提到爬虫可能大多都会想到python,其实爬虫的实现并不限制任何语言。
下面我们就使用js来实现,后端为express,前端为vue3。
实现功能
话不多说,先看结果:

这是项目链接:https://gitee.com/xi1213/worm
项目用到的库有:vue、axios、cheerio、cron、express、node-dev
计划功能有:
- 微博热榜爬取。
- 知乎热榜爬取。
- B站排行榜爬取。
- 三个壁纸网站爬取。
- 随机生成人脸。
- 爬取指定页面所有图片。
- 删除爬取的数据。
- 定时任务(开发中)。
使用形式为:
双击打包出的exe(最好右键管理员运行,以防权限不足)。
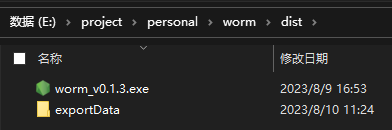
双击exe后会弹出node后端启动的黑框。
自动在浏览器中打开操作界面(用户界面)。

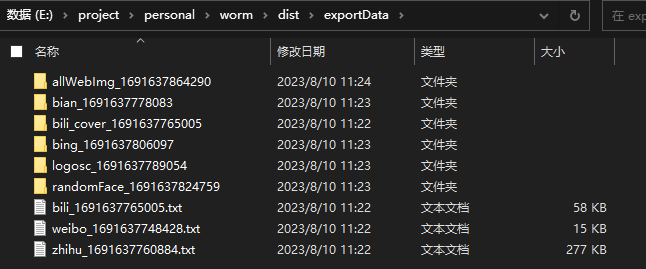
爬取出的数据在exe同级目录下的exportData中。
具体实现
微博热榜
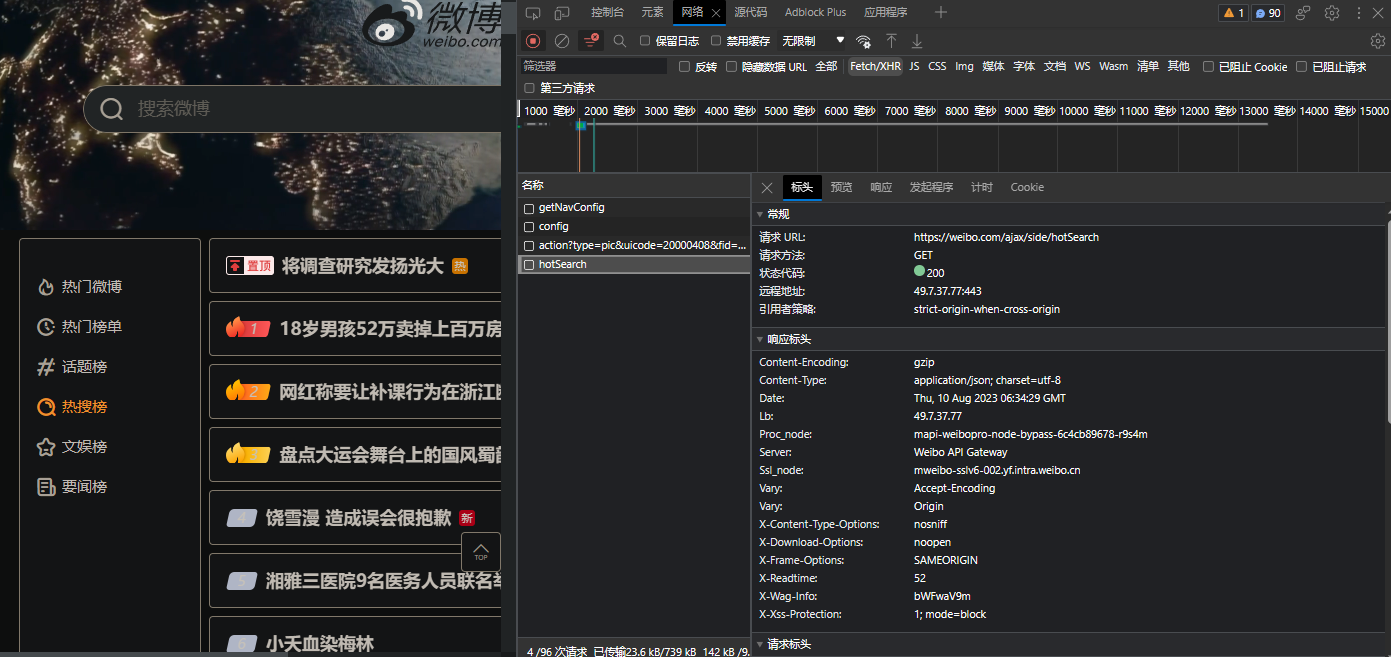
打开微博官网,f12分析后台请求,会发现它的热榜数据列表在请求接口:https://weibo.com/ajax/side/hotSearch 中,无参。
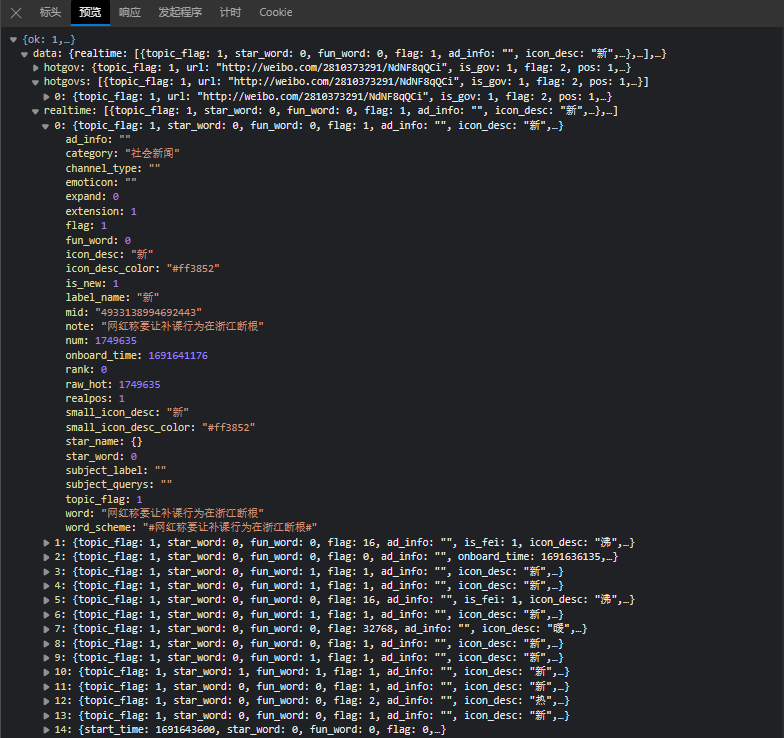
在接口列表realtime中根据页面信息,推测其字段含义:
- word为关键字,
- category为类别,
- https://s.weibo.com/weibo?q=%23 + word为链接,
- num为热度。
既然数据是现成的,那我们直接使用axios即可。
获取到数据列表后将其遍历拼接成指定格式的字符串,写入txt,下面是具体方法:
weibo.js
let axios = require('axios'), writeTxt = require("../utils/writeTxt"), { addMsg } = require("../store/index"); //抓取weibo async function weiboWorm(dir, time) { let com = 'https://weibo.com'; addMsg(`${com} 爬取中...`) let res = await axios.get(`${com}/ajax/side/hotSearch`); //拼接数据 let strData = `微博热榜rn爬取时间:${time}rn` await res.data.data.realtime.forEach((l, index) => { strData = strData + 'rn序号:' + (index + 1) + 'rn' + '关键字:' + l.word + 'rn' + '类别:' + l.category + 'rn' + '链接:https://s.weibo.com/weibo?q=%23' + l.word.replace(/s+/g, "") + 'rn' + '热度:' + l.num + 'rn' + 'rnrn==================================================================================================================' }) writeTxt(`${dir}/weibo_${Date.now()}.txt`, strData);//写入txt addMsg('$END'); } module.exports = weiboWorm; writeTxt.js
let fs = require('fs'); //写入txt function writeTxt(filePath, data) { fs.writeFile(filePath, data, (err) => { }) } module.exports = writeTxt; 需要注意的是在windows中换行使用的是rn,在链接中需要去掉空格。
知乎热榜
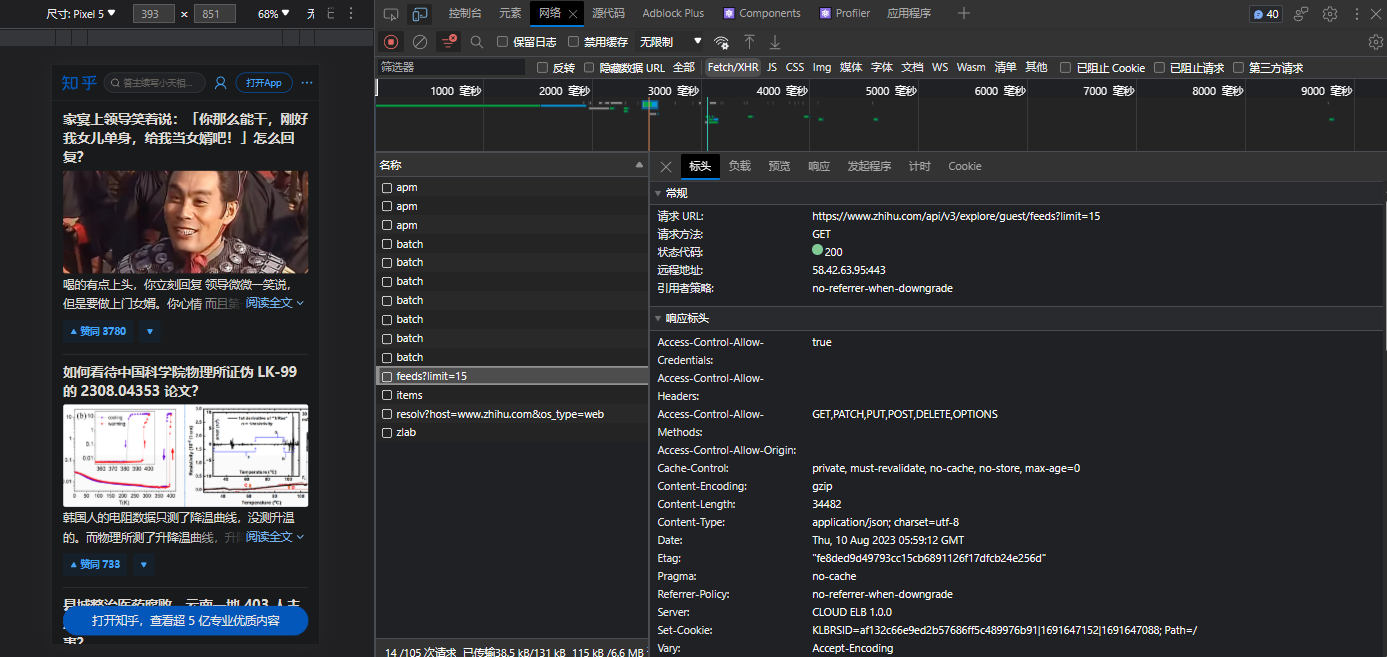
打开知乎官网,会发现它是需要登录的。
f12后点击左上角第二个按钮,在浏览器中切换为手机布局,刷新后即可不登录显示文章信息。
分析请求发现文章数据在请求接口:https://www.zhihu.com/api/v3/explore/guest/feeds 中,参数为limit,限制文章数。
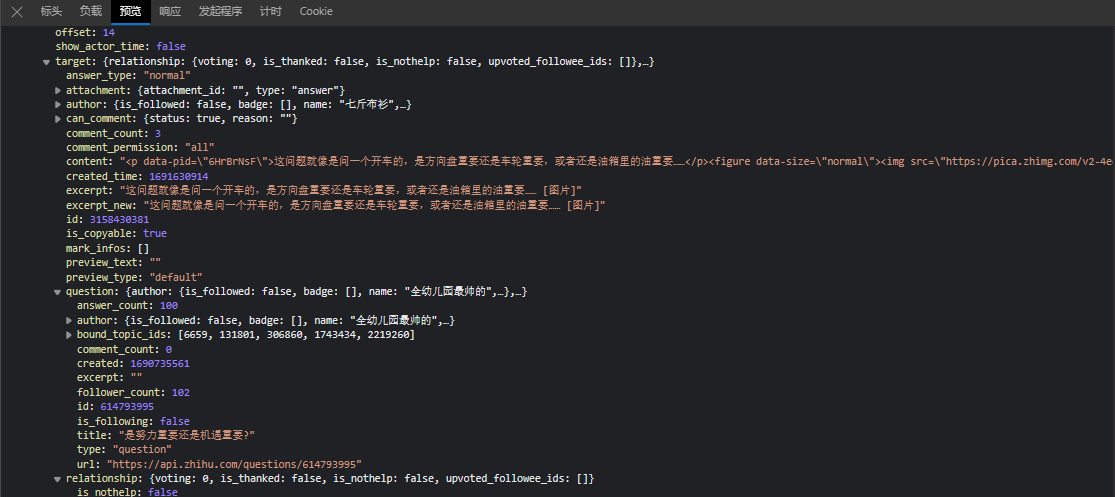
根据页面信息推测接口字段含义:
- target.question.title为问题标题,
- https://www.zhihu.com/question/ + target.question.id为问题链接,
- target.question.answer_count为问答数,
- target.question.author.name为提问的用户名,
- https://www.zhihu.com/org/ + target.question.author.url_token为提问的用户链接,
- target.content为高赞回答的内容。
需要注意的是高赞回答的内容中有html的标签,需要自己str.replace(/xxx/g,'')去除。
数据的具体获取方法同微博类似。
B站排行榜
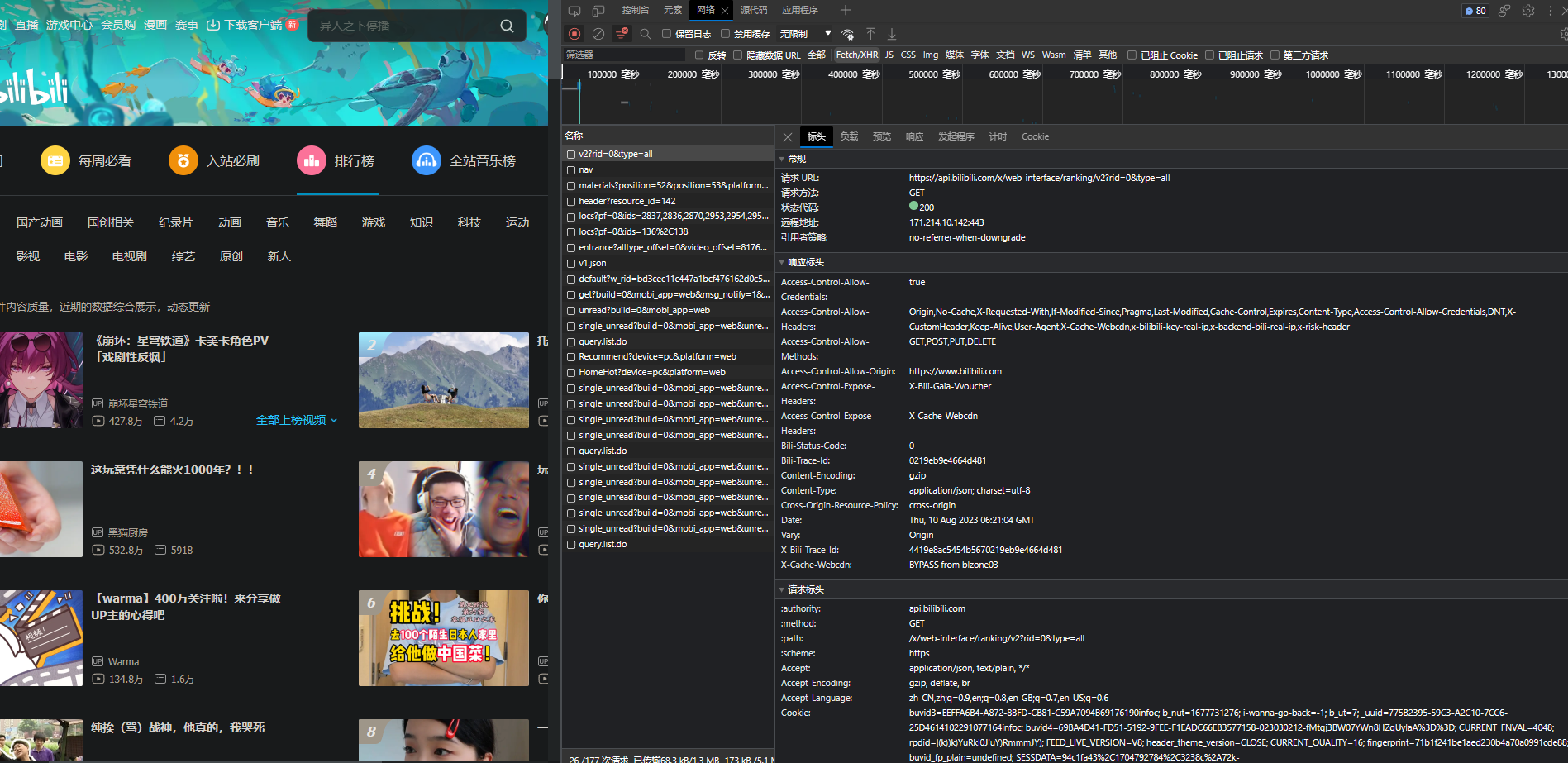
打开B站官网,找到排行榜,f12后发现数据在接口请求:https://api.bilibili.com/x/web-interface/ranking/v2 中,无参。
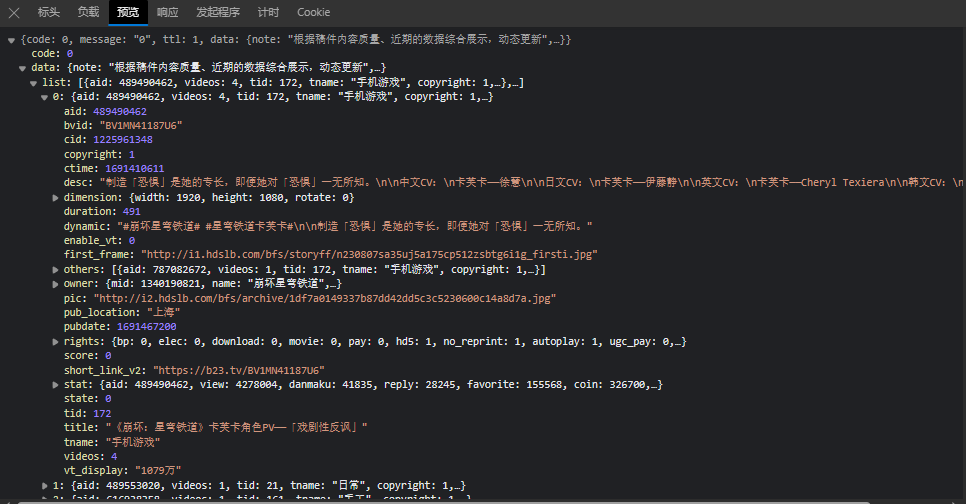
推测接口字段含义:
- title为视频标题,
- short_link_v2为视频短链,
- stat.view为视频浏览量,
- desc为视频描述,
- pic为视频封面,
- owner.name为视频作者,
- pub_location为发布地址,
- https://space.bilibili.com/ + owner.mid为作者链接。
数据的具体获取方法同微博类似。
壁纸网站爬取
项目使用了下面三个网站作为例子:
http://www.netbian.com/

https://www.logosc.cn/so/
https://bing.ioliu.cn/
具体思路如下:
- 用axios请求页面。
- 将请求到的数据使用cheerio.load解析(cheerio为node中的jq,语法同jq)。
- f12分析需要的数据在什么元素中,使用cheerio获取到该目标元素。
- 获取到元素中img的src内容。
- axios请求src(需要encodeURI转码,防止中文报错),记得设置responseType为stream。
- 有分页的需要考虑到动态改变url中的页码。
- 需要保证下载顺序,一张图片下载完成后才能下载另一张,否则下载量过大会有下载失败的可能,使用for配合async与await即可。
具体实现代码如下:
bian.js
let fs = require('fs'), cheerio = require('cheerio'), axios = require('axios'), downloadImg = require("../utils/downloadImg.js"), { addMsg } = require("../store/index"); //抓取彼岸图片 async function bianWorm(dir, pageNum) { let page = pageNum,//抓取页数 pagUrlList = [], imgList = [], index = 0, com = 'https://pic.netbian.com'; addMsg(`${com} 爬取中...`) for (let i = 1; i <= page; i++) { let url = i == 1 ? `${com}/index.html` : `${com}/index_${i}.html`; let res = await axios.get(url); let $ = cheerio.load(res.data);//解析页面 let slistEl = $('.slist');//找到元素列表 slistEl.find('a').each(async (j, e) => { pagUrlList.push(`${com}${$(e).attr('href')}`);//获取到页面url列表 }) } pagUrlList.forEach(async (p, i) => { let pRes = await axios.get(p); let p$ = cheerio.load(pRes.data);//解析页面 let imgEl = p$('.photo-pic').find('img');//找到元素列表 let imgUrl = `${com}${imgEl.attr('src')}`;//获取图片url imgList.push(imgUrl); index++; //循环的次数等于列表长度时获取图片 if (index == pagUrlList.length) { let dirStr = `${dir}/bian_${Date.now()}`; fs.mkdir(dirStr, (err) => { }) downloadImg(imgList, dirStr);//下载图片 } }) } module.exports = bianWorm; downloadImg.js
let fs = require('fs'), axios = require('axios'), { addMsg } = require("../store/index"); //下载图片 async function downloadImg(list, path) { if (list.length == 0) { addMsg('$END'); return; } // console.log(list.length); for (let i = 0; i < list.length; i++) { let url = encodeURI(list[i]);//转码,防止url中文报错 try { //计算下载的百分比 let percent = ((i + 1) / list.length * 100).toFixed(2); let msgStr = `${percent}% 爬取中... ${url}`; addMsg(msgStr); if (i == list.length - 1) { msgStr = `图片爬取完成,共${list.length}项。` addMsg(msgStr); addMsg('$END'); } let typeList = ['jpg', 'png', 'jpeg', 'gif', 'webp', 'svg', 'psd', 'bmp', 'tif', 'tiff', 'ico']; let type = typeList.find((item) => { return url.includes(item); });//获取图片类型 (type == undefined) && (type = 'jpg');//判断type是否为undefined const imgPath = `${path}/${i + 1}.${type}`;//拼接本地路径 const writer = fs.createWriteStream(imgPath); const response = await axios .get(url, { responseType: 'stream', timeout: 5000 }).catch(err => { }); response.data.pipe(writer); await new Promise((resolve, reject) => { writer.on('finish', resolve); writer.on('error', reject); }); } catch (error) { } } } module.exports = downloadImg; 值得注意的是需要保证准确获取图片资源的不同后缀。
随机生成人脸
这里可没有人脸算法之类的,调用的是https://thispersondoesnotexist.com/ 站点的接口,此接口每次刷新可生成不同人脸。
axios请求接口后,使用fs的createWriteStream创建可写流,将数据流写入文件中,下面是具体实现方法:
randomFace.js
let fs = require('fs'), axios = require('axios'), { addMsg } = require("../store/index"); //生成随机人脸 async function randomFace(dir, faceNum) { let com = 'https://thispersondoesnotexist.com'; addMsg(`人脸生成中...`); let dirStr = `${dir}/randomFace_${Date.now()}`; fs.mkdir(dirStr, (err) => { }) for (let i = 1; i <= faceNum; i++) { await axios.get(com, { responseType: 'stream' }) .then((resp) => { const writer = fs.createWriteStream(`${dirStr}/${i}.jpg`);// 创建可写流 resp.data.pipe(writer);// 将响应的数据流写入文件 writer.on('finish', () => { //计算下载的百分比 let percent = ((i) / faceNum * 100).toFixed(2); let msgStr = `${percent}% 人脸生成中... ${dirStr}/${i}.jpg`; addMsg(msgStr); if (i == faceNum) { msgStr = `人脸生成完成,共${faceNum}张。` addMsg(msgStr); addMsg('$END'); } }); writer.on('error', (err) => { addMsg('$END'); }); }) } } module.exports = randomFace; 爬取指定页面所有图片
思路同上面获取壁纸类似,只不过这次是获取页面所有的img标签的src。
由于范围扩大到所有页面了,所以需要考虑的情况就会比较多。
有的src中是没有http或者https的,有的src使用的是相对路径,有的可能有中文字符,还有很多我没考虑到的情况。
所以并不能爬取任意页面的所有图片,比如页面加载过慢,或者用了懒加载、防盗链等技术。
下面是我实现的方法:
allWebImg.js
let fs = require('fs'), cheerio = require('cheerio'), axios = require('axios'), downloadImg = require("../utils/downloadImg.js"), { addMsg } = require("../store/index"); //网站所有图片 async function allWebImgWorm(dir, com) { let imgList = []; addMsg(`${com} 爬取中...`); let res = await axios.get(com).catch(err => { }); if (!res) { addMsg('$END'); return } let $ = cheerio.load(res.data);//解析页面 //获取到页面所有图片标签组成的列表 $('img').each(async (j, e) => { let imgUrl = e.attribs.src;//获取图片链接 if (imgUrl) { !imgUrl.includes('https') && (imgUrl = `https:${imgUrl}`);//判断是否有https,没有则加上 imgList.push(imgUrl); } }) let dirStr = `${dir}/allWebImg_${Date.now()}`; fs.mkdir(dirStr, (err) => { }) downloadImg(imgList, dirStr);//下载图片 } module.exports = allWebImgWorm; 删除爬取的数据
使用fs.unlinkSync删除文件,fs.rmdirSync删除目录。
需要提前判断文件夹是否存在。
需要遍历文件,判断是否为文件。为文件则删除,否则递归遍历。
下面是我的方法:
deleteFiles.js
let fs = require('fs'), path = require('path'); //删除文件夹及文件夹下所有文件 const deleteFiles = (directory) => { if (fs.existsSync(directory)) { fs.readdirSync(directory).forEach((file) => { const filePath = path.join(directory, file); const stat = fs.statSync(filePath); if (stat.isFile()) { fs.unlinkSync(filePath); } else if (stat.isDirectory()) { deleteFiles(filePath); } }); if (fs.readdirSync(directory).length === 0) { fs.rmdirSync(directory); } } fs.mkdir('./exportData', (err) => { }) }; module.exports = deleteFiles; 定时任务
项目中该功能正在开发中,只放了一个按钮,但思路已有了。
在node中的定时操作可用cron实现。
下面是一个小例子,每隔10秒打印一次1:
const cron = require('cron'); async function startTask() { let cronJob = new cron.CronJob( //秒、分、时、天、月、周 //通配符:,(时间点)-(时间域)*(所有值)/(周期性,/之前的0与*等效)?(不确定) '0/10 * * * * *', async () => { console.log(1); }, null, true, 'Asia/Shanghai'//时区标识符 ); }; 注意事项
Server-Sent Events(SSE)
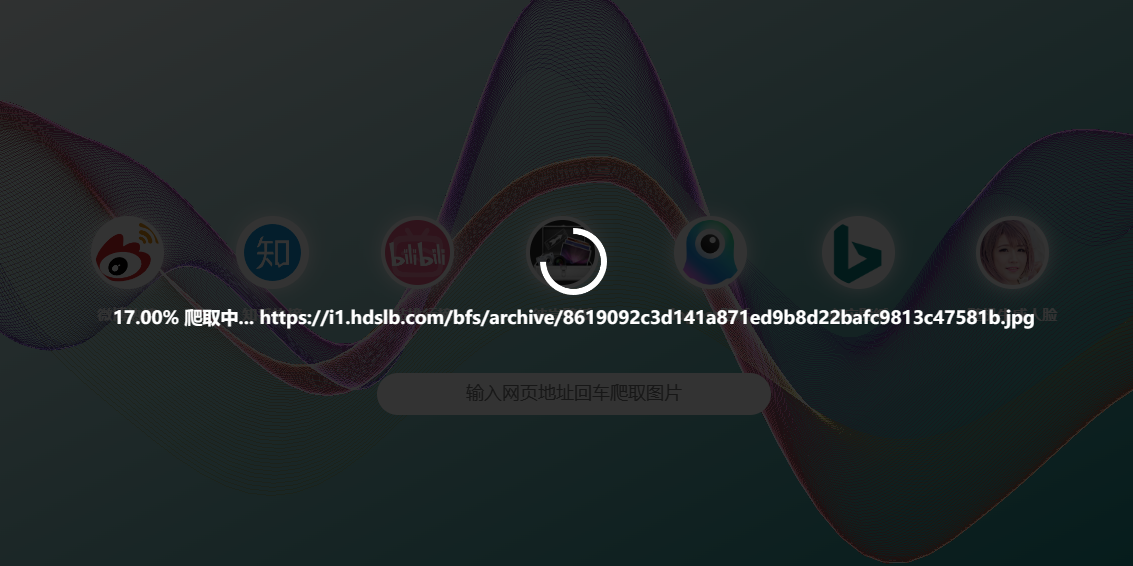
该项目中前后端数据交互接口大多使用的是get请求,但有一个除外,反显爬取进度的接口:/getTaskState。
该接口使用的是SSE,爬取的进度与链接是实时显示的。
最近火热的ChatGPT的流式输出(像人打字一样一个字一个字的显示)使用的便是这个。
SSE虽然与WebSocket一样都是长链接,但不同的是,WebSocket为双工通信(服务器与客户端双向通信),SSE为单工通信(只能服务器向客户端单向通信)。
项目中node服务端发送数据是这样的:
// 事件流获取任务状态 app.get('/getTaskState', async (req, res, next) => { res.writeHead(200, { 'Content-Type': 'text/event-stream', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', }); let sendStr = ''//发送的消息 let id = setInterval(() => { msgList = getMsg(); //消息列表不为空且最后一条消息不等于上一次发送的消息才能执行 if (msgList.length != 0 && msgList[msgList.length - 1] != sendStr) { sendStr = msgList[msgList.length - 1]; console.log('x1B[32m%sx1B[0m', sendStr) res.write(`data: ${sendStr}nn`);//发送消息 } }, 10); req.on('close', () => { clearMsg();//清空消息 res.end();//结束响应 clearInterval(id);//清除定时器(否则内存泄漏) }); }); 需要在res.writeHead中Content-Type设置为text/event-stream即表示使用SSE发送数据。
res.write('data: testnn')即表示发送消息:test,每次发送消息需要以data:开头,nn结尾。
使用setInterval控制消息发送频率。
需要在服务端监听何时关闭,使用req.on('close',()=>{})。
监听到关闭时执行响应结束res.end()与清除定时器clearInterval(id)。
在vue客户端接收数据是这样的:
//事件流获取任务状态 const getTaskState = () => { stateMsg.value = ""; isState.value = true; let eventSource = new EventSource(origin.value + '/getTaskState'); eventSource.onmessage = (event) => { if (event.data != '$END') { stateMsg.value = event.data; } else { eventSource.close();//关闭连接(防止浏览器3秒重连) stateMsg.value = '执行完成!是否打开数据文件夹?'; isState.value = false; setTimeout(() => { confirm(stateMsg.value) && axios.get(origin.value + '/openDir').then(res => { })//打开数据文件夹 }, 100); } }; //处理错误 eventSource.onerror = (err) => { eventSource.close();//关闭连接 stateMsg.value = '' isState.value = false; }; }; 直接在方法中new一个EventSource(url),这是H5中新提出的对象,可用于接收服务器发送的事件流数据。
使用EventSource接收数据,直接在onmessage中获取event.data即可。
关闭连接记得使用eventSource.close()方法,因为服务器单方面关闭连接会触发浏览器3秒重连。
处理错误使用eventSource.onerror方法。
关于关闭SSE连接的时机,这是由node服务端决定的。
我在后端有一个store专门用于存储消息数据:
store/index.js
let msgList = [];//消息列表 function addMsg(msg) { msgList.push(msg); } function getMsg() { return msgList; } function clearMsg() { //清空msgList中元素 msgList = []; } module.exports = { addMsg, getMsg, clearMsg }; - 在爬取数据时,后端会计算爬取的进度,将生成的消息字符串push到msgList列表中,每隔10ms发送给前端msgList列表中的最后一个元素。
- 当后端数据爬取完成时会向msgList中push存入指定字符串:$END,表示获取完成。
- 当前端识别到获取的消息为$END时,关闭连接。
- 后端监听到前端连接被关闭,则后端也关闭连接。
pkg打包
全局安装pkg时最好网络环境为可访问github的环境,否则你只能手动下载那个失败的包再扔到指定路径。
pkg安装完成后需要在package.json中配置一番(主要是配置assets,将public与需要的依赖包打包进exe中)。
这是我的package.json配置:
{ "name": "worm", "version": "0.1.3", "description": "", "bin": "./index.js", "scripts": { "start": "node-dev ./index.js", "dist": "node pkg-build.js" }, "pkg": { "icon": "./public/img/icon.ico", "assets": [ "public/**/*", "node_modules/axios/**/*.*", "node_modules/cheerio/**/*.*", "node_modules/cron/**/*.*", "node_modules/express/**/*.*" ] }, "author": "", "license": "ISC", "dependencies": { "axios": "^0.27.2", "cheerio": "^1.0.0-rc.12", "cron": "^2.3.1", "express": "^4.18.2", "node-dev": "^8.0.0" } } 我的打包命令是通过scripts中的dist在pkg-build.js中引入的,因为我需要将版本号输出在打包出的exe文件名中。
若打包命令直接写在package.json的scripts中会无法读取打包进程中项目的version。
这是我的pkg-build.js:
//只有通过node xxx.js方式执行的命令才能获取到package.json的version const pkg = require('./package.json'), { execSync } = require('child_process'); const outputName = `dist/worm_v${pkg.version}.exe`;//拼接文件路径 const pkgCommand = `pkg . --output=${outputName} --target=win --compress=GZip`;//打包命令 execSync(pkgCommand);//执行打包命令 上面命令中的output表示输出路径(包含exe文件名),target表示打包的平台,compress表示压缩格式。
需要注意的是使用pkg打包时,项目中axios的版本不能太高。
否则即使你将axios写在pkg的打包配置里也无济于事,我使用的axios版本为0.27.2。
解决跨域
我node使用的是express,直接在header中配置Access-Control-Allow-Origin为* 即可。
app.all('*', (req, res, next) => { res.header("Access-Control-Allow-Origin", "*");//允许所有来源访问(设置跨域) res.header("Access-Control-Allow-Headers", "X-Requested-With,Content-Type");//允许访问的响应头 res.header("Access-Control-Allow-Methods", "PUT,POST,GET,DELETE,OPTIONS");//允许访问的方法 res.header("X-Powered-By", ' 3.2.1');//响应头 res.header("Content-Type", "application/json;charset=utf-8");//响应类型 next(); }); child_process模块
众所周知,node是单线程运行的,在主线程中执行大量计算任务时会产生无响应的问题。
但node内置的child_process模块却可以创建新的进程,在新进程中执行操作不会影响到主进程的运行。
在此项目中自动打开浏览器、打开指定文件夹、执行打包命令用的就是它。
// 打开数据文件夹 app.get('/openDir', (req, res) => { res.send('ok'); //打开文件夹,exe环境下需要使用exe所在目录 let filePath = isPkg ? `${path.dirname(process.execPath)}${dir.replace('./', '\')}` : path.resolve(__dirname, dir); exec(`start ${filePath}`); }); //监听端口 app.listen(port, () => { let url = `http://${ipStr}:${port}`; isPkg && exec(`start ${url}`);//打包环境下自动打开浏览器 //判断是否存在exportData文件夹,没有则创建 fs.exists(dir, async (exists) => { !exists && fs.mkdir(dir, (err) => { }); }) console.log( 'x1B[31m%sx1B[0m', `n ${time} 爬虫服务开启!n 运行过程中禁止点击此窗口!n 如需关闭爬虫关闭此窗口即可!n` ); }); 设置静态资源
前端使用vue开发时,需要将vue.config.js中的publicPath配置设置为./之后再打包。
将vue打包后dist内的文件拷贝到node项目的public目录下。
需要在express设置请求头之前使用static(path.join(__dirname, './public'))设置静态资源:
const app = express(); const isPkg = process.pkg;//判断是否为打包环境 const port = isPkg ? 2222 : 1111;//端口 const ipStr = getLocalIp();//获取本机ip let time = getFormatTime();//获取格式化时间 let dir = './exportData'; app.use(express.json());//解析json格式 app.use(express.static(path.join(__dirname, './public')));//设置静态资源 app.all('*', (req, res, next) => { res.header("Access-Control-Allow-Origin", "*");//允许所有来源访问(设置跨域) res.header("Access-Control-Allow-Headers", "X-Requested-With,Content-Type");//允许访问的响应头 res.header("Access-Control-Allow-Methods", "PUT,POST,GET,DELETE,OPTIONS");//允许访问的方法 res.header("X-Powered-By", ' 3.2.1');//响应头 res.header("Content-Type", "application/json;charset=utf-8");//响应类型 next(); }); 关于运行时的黑框
双击exe时,不仅会弹出浏览器用户页面,还会弹出黑框,点击黑框内部还会暂停程序运行。
我有想过使用pm2守护进程干掉黑框,但想到关闭爬虫时只需关闭黑框即可,便留下了黑框。
限制爬取次数
做人,特别是做开发,你得有道德,你把人家网站给玩儿崩了这好吗(′⌒`)?
没有任何东西是无限制的,我的限制是放在前端的(可能不太严谨),以爬取壁纸为例,调用inputLimit(num),入参为执行次数,方法是这样的:
//输入限制 const inputLimit = (pageNum) => { let val = prompt(`输入执行次数(小于等于${pageNum})`, ""); if (val == null || isNaN(val) || parseInt(val) < 1 || parseInt(val) > pageNum) { return false; } return parseInt(val); }; //彼岸壁纸 const bianWorm = () => { let val = inputLimit(10); if (val) { axios.get(origin.value + '/bianWorm?pageNum=' + val).then(res => { }); getTaskState(); } }; 后端获取到pageNum参数后,以此作为执行爬虫逻辑的循环依据。
结语
这是我第一次用js玩儿爬虫,很多地方可能不太完善,还请大佬们指出,谢谢啦!
此项目仅供学习研究,勿作他用。




