- A+
个人学习-Linux文件系统架构
1. 参考文章
[1]https://blog.csdn.net/Holy_666/article/details/86532671
[2]CSDN博主土豆西瓜大芝麻:[Linux的VFS详解]:https://blog.csdn.net/jinking01/article/details/90669534
[3]深入理解 Linux的 I/O 系统:https://z.itpub.net/article/detail/9595A9A27188FF73810F07F00DAA08ED
[4]Linux嵌入式的知乎专栏:https://zhuanlan.zhihu.com/p/505338841
[5]博客园博主[李大嘴]:[字符设备和块设备的区别]https://www.cnblogs.com/qlee/archive/2011/07/27/2118406.html
[6]博客园博主[赛艇队长]:[Linux文件系统详述]https://www.cnblogs.com/bellkosmos/p/detail_of_linux_file_system.html
[7]StackExchange:[What are directories, if everything on Linux is a file?]
[8] [The Linux Documentation Project: Filesystem]http://www.tldp.org/LDP/tlk/fs/filesystem.html#tth_sEc9.1.4)
2. 概述:
本文主要从四个角度对Linux文件系统进行总结整理;
-
Linux文件系统的组织方式;
-
Linux的VFS机制和统一文件模型(common file model);
-
Linux系统IO缓冲机制;
3. Linux文件组织方式:
3.1 基础知识:
老调重弹:Linux设计的思路,就是一切皆文件,因此Linux中的一切文件都以文件格式保存,而文件根据各自不同的功能分为一下几类:
-
普通文件:
-,常规的文件类型,在Linux中,以.开头的文件为隐藏文件;
-
目录文件;
d, 目录文件,目录文件实际包含两部分Inode和entry(实际所有文件都是这样,不同的是,目录中保存了相关文件的信息);
Linux通过Inode结构体存储目录的基础信息,系统调用stat(),用来访问这个结构和相应信息。
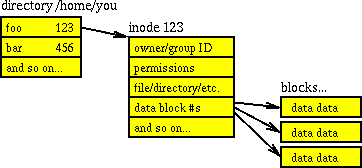
(图1 源自引用文献[7])
-
字符设备文件;
c, character device,字符设备是以字符为最小单位进行数据交互的文件,用以驱动字符交互的应用,如键盘(有文章提到oracle是以字符为格式进行数据传输的,记个ToDo);
而对于字符设备而言,仅支持顺序访问数据,不支持随机访问。
-
块设备文件;
B,block device driver
块设备传输,实际是以固定大小进行数据传输的文件类型,和字符设备不同的是,block支持我们对设备随机访问。最典型的例子即硬盘,操作系统/数据库/其他和磁盘交互应用,实际可以根据自己的规则,去随机访问磁盘的位置,去在该位置写入数据。而通过块设备进行读写时,也需要以bolck为最小单位进行操作(实际上,无论是OS还是DBS,都是以Page去容纳多个Block,然后通过Page进行数据加载,然后以block进行数据解析的)
-
符号链接;(软链接,硬链接实际是生成了一个相应文件,该文件名和原始文件名指向同一个inode):
符号链接可以理解成一种快捷方式,允许我们通过符号链接快速访问目标文件。
-
套接字;
S,socket,用于网络通信的文件,通过套接字API形成的一个简单协议族,成对出现进行通信。
-
管道;
P,进行进程间通信的文件,将一个进程的输出,通过管道,输入到另一个文件。
3.2 文件系统的基本组成
(Note: 本部分仅介绍基础部分,磁盘分区,初始化,数据在磁盘上的组织后续再进行补充)
Linux操作系统支持很多不同的文件系统,ext2,ext3,XFS,FAT等等,而Linux把对不同文件系统的访问,交给VFS(virtual file system)来进行。
Linux的文件系统会为每个文件分配两个数据结构:
索引节点(index node) 和 目录项(directory entry),用来记录文件的元信息(meta data)如inode编号,文件大小,访问权限,修改时间,磁盘位置等。索引节点和磁盘上的每个物理文件相对应,而索引节点本身,也存储在磁盘上。
目录项(directory entry)用来记录文件的名字,索引节点指针,和其他目录项的层次关系。多个目录项关联起来,就形成了目录结构,和索引节点不同,目录项是由内核维护的数据结构,缓存在内存中;(note:实际上系统启动时,会将相应的数据,加载到树形结构中,维护在内存中)
目录项的结构体,dentry
struct dentry { atomic_t d_count; /* 目录项引用计数器 */ unsigned int d_flags; /* 目录项标志 */ struct inode * d_inode; /* 与文件名关联的索引节点 */ struct dentry * d_parent; /* 父目录的目录项 */ struct list_head d_hash; /* 目录项形成的哈希表 */ struct list_head d_lru; /*未使用的 LRU 链表 */ struct list_head d_child; /*父目录的子目录项所形成的链表 */ struct list_head d_subdirs; /* 该目录项的子目录所形成的链表*/ struct list_head d_alias; /* 索引节点别名的链表*/ int d_mounted; /* 目录项的安装点 */ struct qstr d_name; /* 目录项名(可快速查找) */ unsigned long d_time; /* 由 d_revalidate函数使用 */ struct dentry_operations *d_op; /* 目录项的函数集*/ struct super_block * d_sb; /* 目录项树的根 (即文件的超级块)*/ unsigned long d_vfs_flags; void * d_fsdata; /* 具体文件系统的数据 */ unsigned char d_iname[DNAME_INLINE_LEN]; /* 短文件名 */ }; 通过stat访问得到的Inode信息
struct stat { /* when _DARWIN_FEATURE_64_BIT_INODE is NOT defined */ dev_t st_dev; /* device inode resides on */ ino_t st_ino; /* inode's number */ mode_t st_mode; /* inode protection mode */ nlink_t st_nlink; /* number of hard links to the file */ uid_t st_uid; /* user-id of owner */ gid_t st_gid; /* group-id of owner */ dev_t st_rdev; /* device type, for special file inode */ struct timespec st_atimespec; /* time of last access */ struct timespec st_mtimespec; /* time of last data modification */ struct timespec st_ctimespec; /* time of last file status change */ off_t st_size; /* file size, in bytes */ quad_t st_blocks; /* blocks allocated for file */ u_long st_blksize;/* optimal file sys I/O ops blocksize */ u_long st_flags; /* user defined flags for file */ u_long st_gen; /* file generation number */ }; 而索引节点,目录项,以及文件数据间的关系可以用如下结构来表示
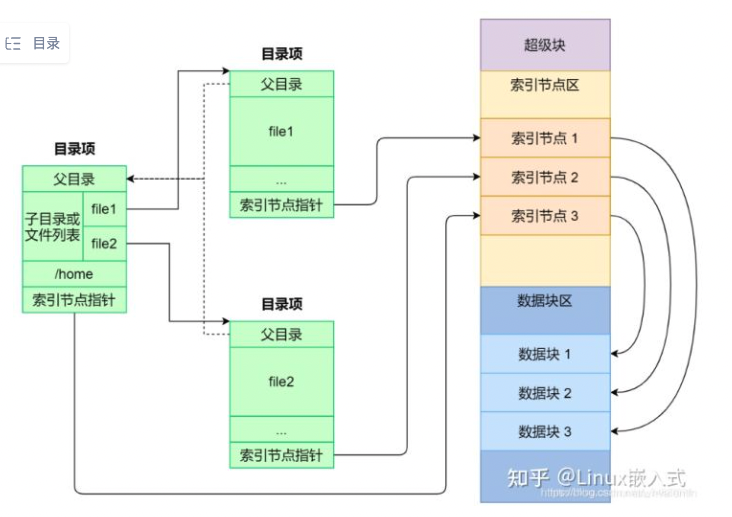
(图2 源自引用4)
4. 虚拟文件系统(Virtual File Switch)
当一个用户应用,通过系统调用函数进行数据读写时会发生什么?
fopen("~"); fwrite("~"); fclose("~"); 在我们的直觉上,会认为用户空间的代码,通过调用库函数唤起系统调用,然后交于OS File System直接写入磁盘(在考虑buffer,page,block,机制后)。但是实际上Linux实际上是将系统调用交付于VFS,即虚拟文件系统,然后由VFS执行后续操作的。
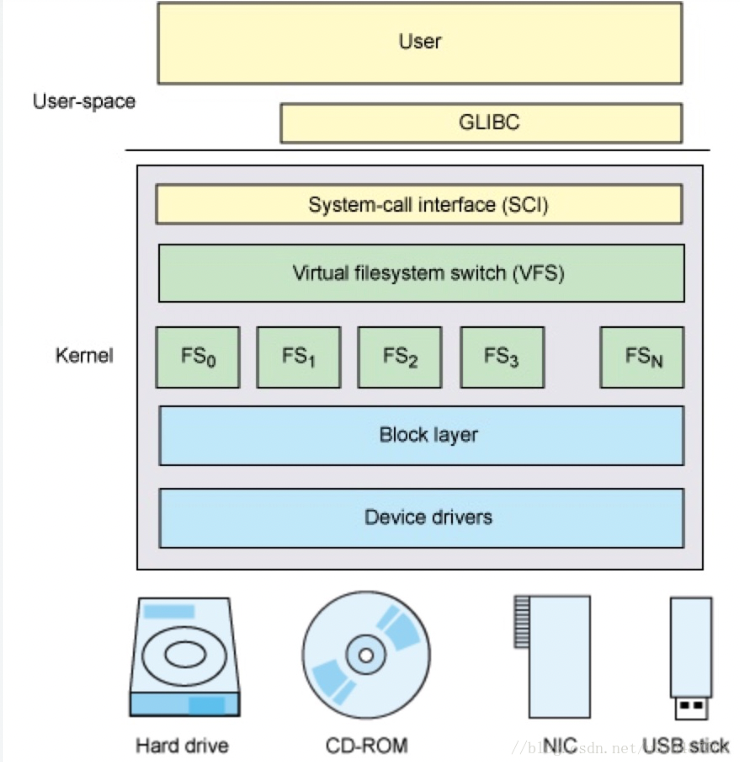
(图3 源自引用2)
这样做有什么价值呢?如上文所述,Linux存在不同的file system operator,这些不同的文件系统暴漏给上层的接口可能是不同的,如果将这些接口都提供给OS SCI(stsrem call interface),系统调用会过于复杂。而VFS在文件系统和系统调用间提供了一个抽象层,让系统调用的POSIX API和不同存储设备的具体接口实现了分离,实现了一次解耦。

(图4 源自引用2)
4.1 统一文件模型(common file model)
由于VFS将不同的底层接口抽象了统一的标准给系统调用,系统调用层便可以用上文提到的Inode,entry模型将所有文件的模型进行统一。实际上正是VFS层提供了统一的文件模型。
VFS通过四种标准模型来构建统一文件模型:
(1)superblock: 存储文件系统的基本元数据(可以理解成 meta of meta,这词儿没查过,是我现编的)。如文件系统的类型,大小,状态,一起其他元数据的相关信息。
(2)index node(inode):一个用来保存文件相关的元数据。
(3)directory entry: 保存文件名称和inode的对应关系;
每个dentry存在三种状态:
- Used: 和一个inode关联,正被使用,不能被损坏和丢弃;
- Unused: 和inode关联,处于被缓存状态,没有被vfs使用;
- negative: 没有和具体的inode关联(实际相当于一个无效路径);
由于dentry实际是加载在内存里的,系统会对dentry存在优化策略:
1.used dentrie list:把使用的dentry串成一个链表;
2.LRU链表:(least recently used)链表,实际就是最常见的页面置换算法,找出最久没有使用的entry,把它从内存中释放。
3.hash table:用哈希表,来维持dentry的高速查询;
(4) file: 一组逻辑上相关联的数据,实际就是我们通过open函数返回的数据类型,在我们使用open打开函数后,就从磁盘中加载了对于的数据至内存,VFS将数据保存至File模型中,和进程,用户强关联。其中包含了打开的flag,文件名称,当前的便宜。最重要的字段就是f_op,指向了当前文件所支持的操作集合;
struct file { struct dentry *f_dentry; struct vfsmount *f_vfsmnt; struct file_operations *f_op; mode_t f_mode; loff_t f_pos; struct fown_struct f_owner; unsigned int f_uid, f_gid; unsigned long f_version; ... } 5. 系统IO
本部分主要讨论系统IO和缓冲区之间的交互;
传统的(无缓存)文件读写方式

1.用户进程通过read()向kernel进行系统调用,切换上下文,到内核空间。
2.CPU将数据从硬盘or主存拷贝至kernel到读缓冲区;
3.CPU将读缓冲区的数据拷贝回用户缓冲区;
4.上下文从kernelspace 切换回UserSpace,read调用执行返回;
用户态 <---> 内核态切换两次;
拷贝操作,两次;
用户态的切换和系统拷贝,被切开,相较于连续的操作,这种间断式的操作更耗时;
高性能优化的I/O
PageCache
页缓存技术,通过每次从磁盘读取一个Page单位的数据至缓存,来减少对磁盘的读写,来提高系统效率;
当我们进行顺序读写时,页缓存能极大提高我们的读写速度(实际就是直接在memory上读写);
页缓存的优化策略:
读策略:
- 当我们执行read操作时,判断数据在PageCache上吗?如果在,我们就不对磁盘进行读操作;
- 如果不在,调度I/O去读磁盘数据,除了目标文件所在的Page外,还会读多个连续页到页缓存中;
写策略:
当我们执行写操作时,先写进页缓存,此时我们把目标页标记为脏页(dirty page),并把这个页加入脏页链表;
flusher会周期性的回写脏页到磁盘,当磁盘数据和内存一致时,清楚脏页标记,
当满足以下条件时,脏页会被写入内存:
- 空闲内存低于一个特定阈值;
- 脏页在内存驻留时间超过阈值时(LRU)
- 用户进程调用sync()和fsync()时;