- A+
书接上回,OrchardCore的基本设置写了,但是有一说一,这个东西还是挺复杂的,如果需要构建一个简单的企业网站,还需要干点别的活。
本文考虑在尽量少编程的基础上,完成一个Headless网站的设置工作。本文启用了大量的Features,如果在设置过程中发现缺少对应的feature,请在配置界面中启用。
设置基本类型
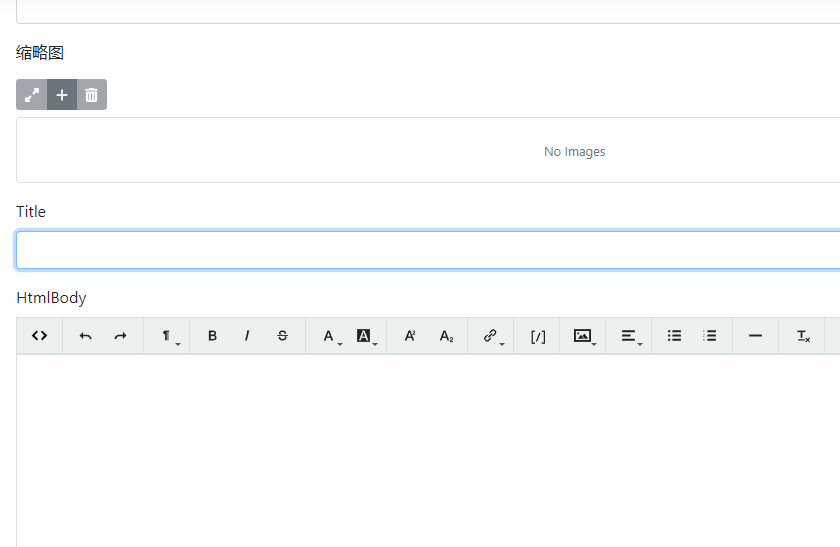
OrchardCore默认只提供Menu数据类型,这个是用来新建菜单的,后面会详细说。我们需要在Content Definition中新建的Content Type。设置很简单,我新建了一个Article类型。
接下来需要给Fields中与Parts中添加必要的内容,Parts中添加Title可以用于在查询系统中显示与设置displayText,然后在Fields中新增需要添加的元素(文章主题,缩略图等)。
Parts指代组件,一般用于此项类型与CMS系统交互设置使用。而Fields则指代此项类型内部的组成。
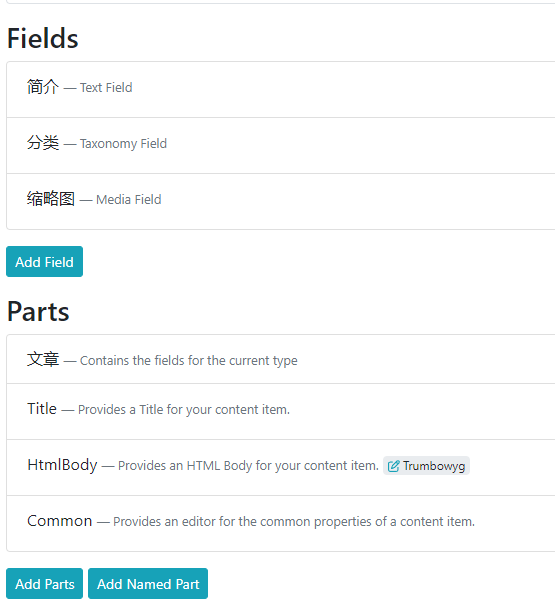
通过以上的设置,为文章(Article)设置了一个简介,定义了分类(Taxonomy)字段,还提供了缩略图。以后发表文章,就可以通过在Content Items中新建Article进行编写。
这里我设置有点问题,正常来说应该在Fields中设置HtmlBody的,不过也没关系,这个只影响在什么地方取得数据。请注意一点,对于一些复杂的Part或者Field,可以点击右边的“修改”以设置必要的形式。这里我对HtmlBody设置了默认的编辑器。
设置目录级别
一般的公司主页类型的网站,都有多层的级别,当然可以通过Menu选项卡进行设置,不过经过我实践,这个Menu的层级设置非常别扭,且无法简单得被前端解析。这里不详细解释了,大家有兴趣可以在配置选项卡下面的GraphiQL中查询体验一下。
设置层级一度卡住了我,通过查找资料,我发现有三种形式可以表述层级结果,我个人感觉通过Taxonomy处理层级关系最简单直接。
直观感觉在层级不超过3的时候,使用Taxonomy比较舒服,更深的层级应该依然可用,但是查询可能比较麻烦。
首先需要在Feature上启用Taxonomy,可以理解这个东西是一个Tag,文档添加了这个Field之后,即可勾选已经设置好的类别了。
在Content Types中找到Taxonomy,然后新建一个Taxonomy,设置了基本信息后,下面的Term Content Type,对一级目录,请设置为Taxonomy,并继续添加二级目录名称;对二级目录,设置该项为Article,这样就能在文章的编辑中找到对应的选项,实现对文章(三级项目)的归类。
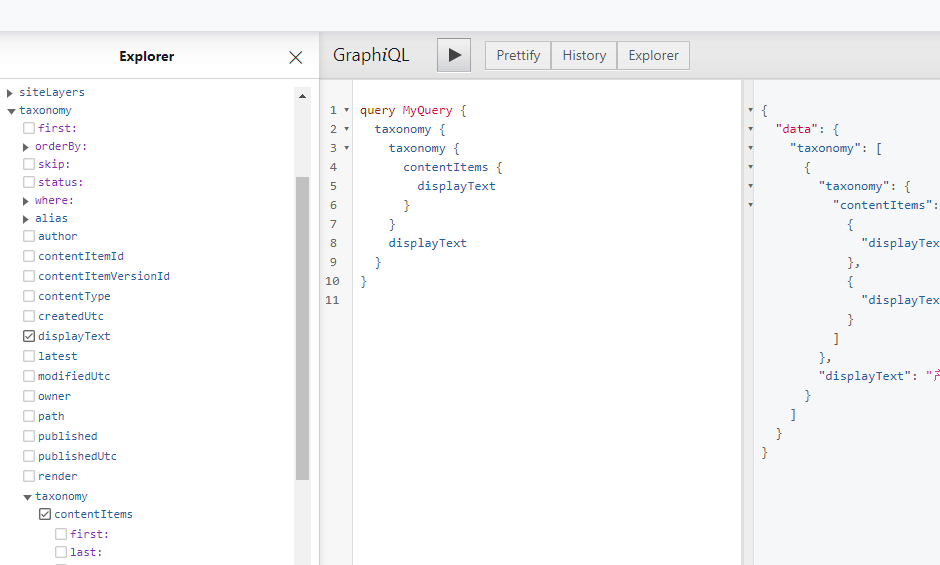
设置完毕即可通过GraphQL查询出2层级的目录,第三级别已经是文章了,不会显示在这里,而是需要另外查询。
设置自定义函数
我们的目标很简单,通过二级Taxonomy的id,查询到在这个类别下面的所有文章。但理想很丰满,现实很骨感:虽然设置了目录,也可以通过GraphQL查询到目录的层级,但OrchardCore內建的GraphQL只能依据其固定的几个参数进行的条件筛选,无法依据自定义的字段进行查询。
只能曲线救国,自己定义一个查询!
需要在Feature中启用Queries与SQL Queries。当然OrchardCore还支持Lucene全文索引,有兴趣的同学可以自行探索。
首先在Search选项卡的All queries中,新增一个查询,然后选择SQL查询。然后设置查询的函数名称,schema的设置还是需要看官方说明,如果是返回一篇文章的话,那么schema内容填写如下,并且一定要勾选Return Documents这个选项。
{ "type": "ContentItem/Article" } 底端的Query填入:
select DocumentId from TaxonomyIndex where ContentType='Article' and TermContentItemId = @termid:'4v5ww2mv7ys01smccm0qxwepx4' 其中,DocumentId会被GraphQL自动转换成文档,@termid是需要传入的参数,后面接着的是默认的值。SQL的语句结果可以通过Run SQL Query中进行尝试,结合官方的文档,建议自己尝试的时候直接使用select * from...,这样有助于了解每个字段的结构。
设置完毕后,在GraphiQL中就可以看到新建的函数了。
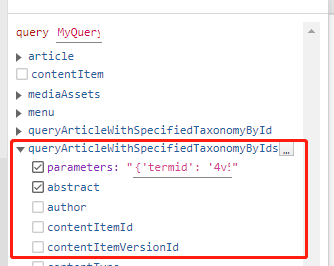
前端调用查询
整体流程如下:
- 查询Taxonomy,获得层级关系。
- 当用户实际点击某一个分类的时候,使用查询获得每个分类的具体下属文章。
可以通过多种形式调用自建的查询:
WebAPI
可以使用GET与POST访问api/queries/{name},参数走body,详情看官方文档
GraphQL
当然也可以直接使用GraphQL,定义好的查询将作为在GraphQL中的顶级元素,参数必须要是json形式,由于放在双引号内,请注意变换成单引号。具体如何调用GraphQL,请看我之前发的文章。

SQL语句
这个套路就比较那个啥了,需要具有Admin的权限,POST访问Admin/Queries/Sql/Query接口,请求body里面直接是SQL查询。这个属于非正常方法。
DecodedQuery:select+DocumentId from+TaxonomyIndex where+ContentType='Article'+and+TermContentItemId+=+@termid:'4v5ww2mv7ys01smccm0qxwepx4' Parameters:{ ++"termid":+"4v5ww2mv7ys01smccm0qxwepx4" } 使用WEBAPI替代GraphQL进行查询
官方文档中,一直在强调使用GraphQL进行各种查询,但是很多同学并不一定喜欢这个东西,其实,使用WebAPI进行简单的查询,OrchardCore还是有內建支持的,不过隐藏的比较深,需要去看看源码(在OrchardCore.Contents/Controllers文件夹下),已知的有以下几个类提供WebAPI接口:
- AdminController
提供几个管理界面使用的API,从代码来看,应该是给管理界面内部使用的。
- ApiController
这个接口提供了POST、DELETE、GET几个接口,最重要的是GET接口可以通过ContentItemId直接取得对应的文档对象,如果知道文章的具体ID,那么可以直接通过这个接口访问获得对应的文章。
- ItemController
应该是给内部预览之类使用的,方法比较少。
如果喜欢使用WEBAPI的形式,大家也可以在这个文件夹里面编写自己的逻辑。
结语
本文可能写的比较晦涩,主要根据个人的实践总结而成。OrchardCore官方提供的资料比较分散,缺少成体系的介绍,建议大家一边实践一边查阅官方文档和issues。