- A+
问题背景
大一点的公司都会建立一套规章流程来避免低级错误,例如合入代码前必需经过同行评审;上线前必需提测且通过 QA 验证;全量前必需经过 1%、5%、10%、20%、50% 的灰度过程。尤其是最后一步,需要严密的监控发版指标来保证新版本的质量,如果与主力版本的指标相比有异常变动,就需要及时停止放量并分析原因。
一个版本的重点观察指标,除崩溃率外有小 20 项,分布在系统的 10 多个页面,且每个指标均需要指定多达 6-10 个过滤条件,最常用的包括版本号、端类型 (PC/ Mac/Android/iOS/…)、用户类型 (user/vip/svip),此外还有一些复杂的下拉列表选项,每次都记不住,需要参考文档才能确定选对了 ?;另外像版本号这种选项,系统需要很长时间才能刷出来全部版本列表,有时等了很长时间也出不来,还得手动刷一下才能好;最后,有一些指标系统里没有直接给出,需要综合多个指标数据进行计算,例如版本流量占比是由版本流量除以总流量得出的,类似的还有播放流量占比;另外还有一些通用的计算,例如速度的单位是 B/s,实际上使用 MB/s 更贴切,人工记录数据时,一般直接除以 1000 来进行简单估算,与除以 1024 相比还是有比较大误判的。走一遍完整流程下来,快了也得半小时,慢了一上午就过去了。
解决方案
凡是重复性的劳动都有优化空间,凡是收集数据的工作都能用脚本完成——本着这两个原则,尝试做一个自动获取发版指标数据的 shell 脚本。之前有使用 curl 访问 restful api 的经验 (用 shell 脚本做 restful api 接口监控),这次访问 web 服务器原理也是一样的,通过浏览器的页面调试功能,可以查看到一次请求的详细信息:
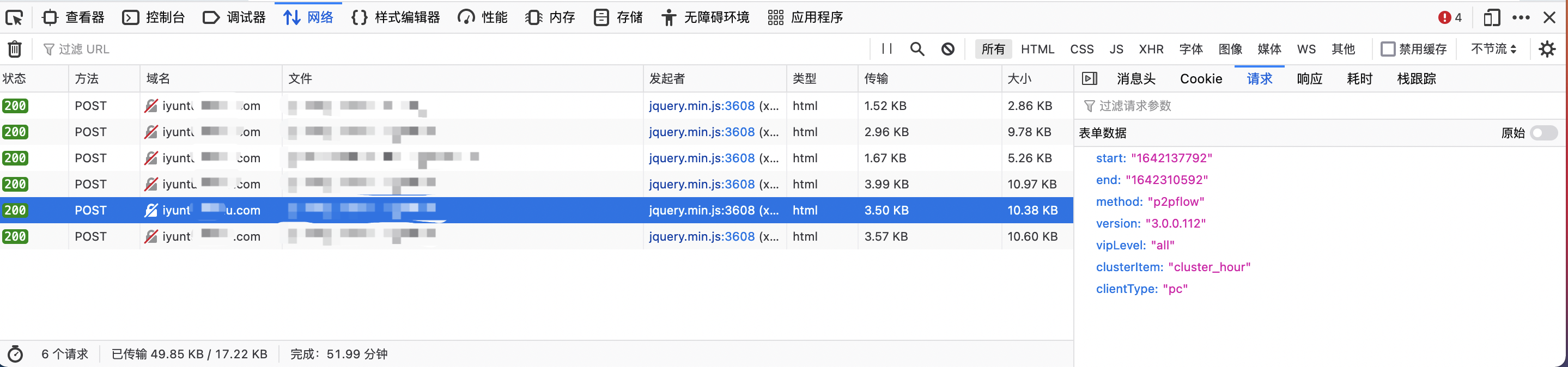
主要使用的是 http post 数据,数据基于 json 格式返回:
不同请求返回的 json 格式不同,不过都可以使用 jq 命令处理。
拉取数据
用 curl 尝试一下:
curl -s "http://iyuntu.xxxxx.com/xxxxxx/api/xxxxxxxxxxxxx/" -H "Accept: */*" -H "Connection: keep-alive" -H "Content-Type: application/x-www-form-urlencoded; charset=UTF-8" -H "Accept-Encoding: gzip, deflate" -d "start=1642137792&end=1642310592&method=p2pflow&version=3.0.0.112&vipLevel=all&clusterItem=cluster_hour&clientType=pc"提交的表单数据与 web 请求完全一致,然而得到了服务器错误:
{"error_code":1006,"message":"userinfo is wrong.","data":[]}提示用户信息错误,难道是因为没有携带登录信息?再看一下浏览器中请求的 cookie 信息:
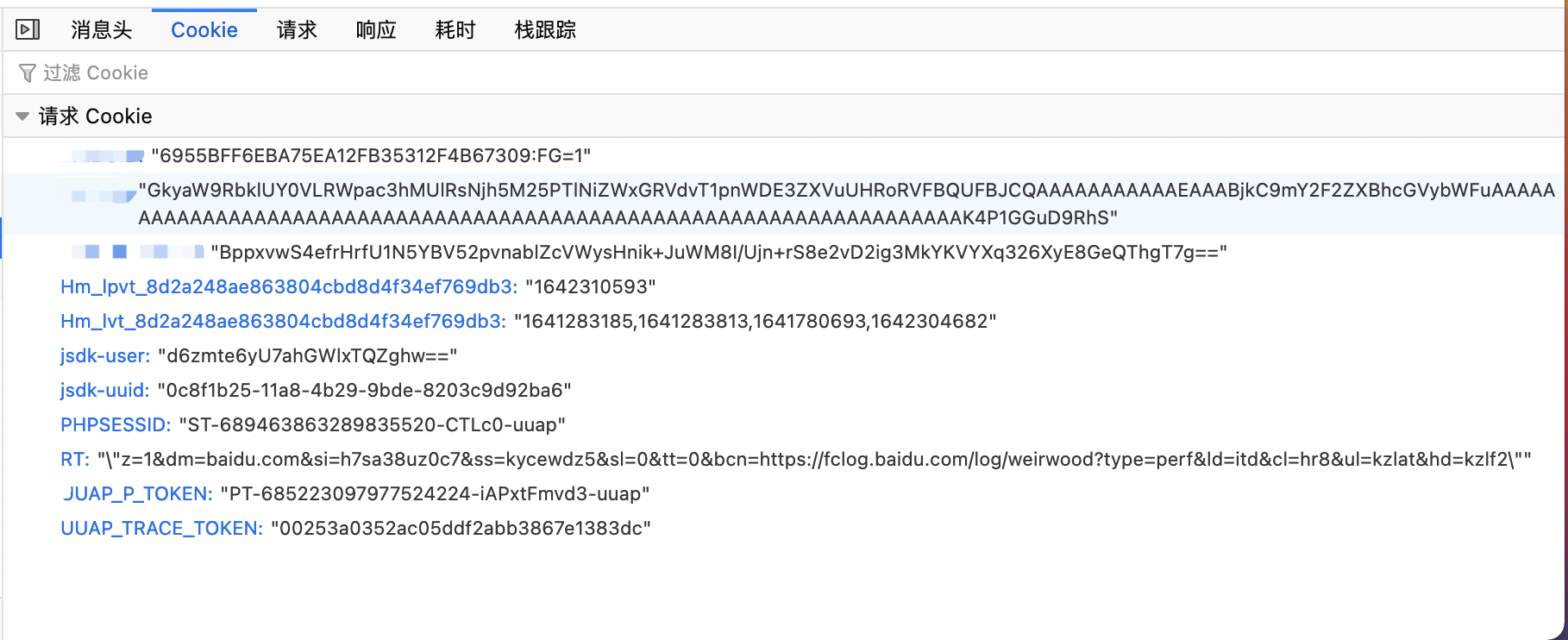
确实不少,将整个 cookie 携带到 curl 的请求中:
curl -s "http://iyuntu.baidu.com/clientive" -H "Content-Type: application/x-www-form-urlencoded; charset=UTF-8" -H "Accept-Encoding: gzip, deflate" -d "start=1642137792&end=1642310592&method=p2pflow&version=3.0.0.112&vipLevel=all&clusterItem=cluster_hour&clientType=pc" --cookie 'XXXXXXX=6955BFF6EBA75EA12FB35312F4B67309:FG=1; UUAP_TRACE_TOKEN=00253a0352ac05ddf2abb3867e1383dc; Hm_lvt_8d2a248ae863804cbd8d4f34ef769db3=1641283185,1641283813,1641780693,1642304682; jsdk-uuid=0c8f1b25-11a8-4b29-9bde-8203c9d92ba6; RT="z=1&dm=baidu.com&si=h7sa38uz0c7&ss=kycewdz5&sl=0&tt=0&bcn=https%3A%2F%2Ffclog.xxxxx.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=itd&cl=hr8&ul=kzlat&hd=kzlf2"; XXX_X_XXXXX=BppxvwS4efrHrfU1N5YBV52pvnablZcVWysHnik+JuWM8I/Ujn+rS8e2vD2ig3MkYKVYXq326XyE8GeQThgT7g==; XXXXX=GkyaW9RbklUY0VLRWpac3hMUlRsNjh5M25PTlNiZWxGRVdvT1pnWDE3ZXVuUHRoRVFBQUFBJCQAAAAAAAAAAAEAAABjkC9mY2F2ZXBhcGVybWFuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAK4P1GGuD9RhS; UUAP_P_TOKEN=PT-685223097977524224-iAPxtFmvd3-uuap; jsdk-user=d6zmte6yU7ahGWlxTQZghw==; PHPSESSID=ST-689506677214060545-7KJVo-uuap; Hm_lpvt_8d2a248ae863804cbd8d4f34ef769db3=1642320803'这次不报错了,但是也没有请求到任何结果,查看 curl 返回值:
$ echo $? 23百度了一下,curl 23 错误是写失败,难道需要重定向到文件?为上面的命令加入:
--output temp.dat将结果保存在 temp.dat 文件中,这次 curl 正常了,但查看 temp.dat 却是一团乱麻:
$ head -n 1 temp.dat ?ٮ?E?E?7?!?b A,9p?6 ???YuN?n ?c?'??n?5????[?????c/?>??_?????????????̥?z_?_??m>~?R?ʥ??gI?=_????G_????Xş??????9k?5????难道是被压缩了?使用 gunzip 解压试试:
$ cat temp.dat | gunzip {"p2pu6d41u91cf":[[1642140000000,28249601382.447],[1642143600000,29701279461.349],[1642147200000,30004732054.571], [1642150800000,28226621579.753],[1642154400000,27565004131.18],[1642158000000,30050204384.371],[1642161600000,34357590257.653], [1642165200000,37445146977.384],[1642168800000,37507405282.629],……确实是,解压后得到的就是 json 内容了,内容解析暂时放一下,先聚焦一下 cookie 。
使用浏览器 cookie 可以得到想要的结果,但会对浏览器形成依赖——每次跑脚本前需要从浏览器抓一份 cookie 保存在本地。经过一番探究,发现只要保留 cookie 中的这一条就能访问:
PHPSESSID=ST-689506677214060545-7KJVo-uuap;应该是 SSO 登录后的访问凭证。从浏览器复制一条 cookie 虽然有一点麻烦,但也不是不能接受,相比手工记录发版指标数据,还是友好不少了嘛~
下面以流量指标为例,串起来上面的一系列命令:
# @param: starttime # @param: endtime # @param: version # @param: clienttype # @param: cookie # @param: select-time [option] function fetch_flow() { local starttime="$1" local endtime="$2" local version="$3" local clienttype="$4" local cookie="$5" local selecttime="" if [ $# -gt 5 ]; then selecttime="$6" fi local data="start=${starttime}&end=${endtime}&method=p2pflow&version=${version}&vipLevel=all&clusterItem=cluster_hour&clientType=${clienttype}" curl -s "http://${HOST}/client/api/xxxxxxxxxxxx/" -H "Accept: */*" -H "Connection: keep-alive" -H "Content-Type: application/x-www-form-urlencoded; charset=UTF-8" -H "Accept-Encoding: gzip, deflate" -H "Origin: ${HOST}" -H "Referer: http://${HOST}/stability/main?typeName2=total_flow&typeName2=cluster_hour&typeName2=${clienttype}&datepicker0=${starttime}&datepicker1=${endtime}" -H "X-Requested-With: XMLHttpRequest" --cookie "$cookie" -d "$data" --output temp.gzip if [ $? -eq 0 ]; then echo "request flow ok" cat temp.gzip | gunzip > temp.txt # handle data here... fi }做个简单说明:
- 一些参数是从外部传入的,详见参数命名
- 提前拼接好表单数据备用
- curl 发送请求,多了一些 http 头,主要是参考 web 请求设置的,实测可有可无
- 请求中指定的 cookie 是从外部传入的,这个参数其实就是从浏览器存储到文件后传递进来的
- curl 响应存放在 temp.gzip 文件中,使用 gunzip 解压缩到 temp.txt 文件,后面就可以用 txt 进行数据解析了
实测 cookie 中的 PHPSESSID 失效时间非常短,可能也就半个小时,基本每次执行脚本时都需要重新抓取。
解析数据
有了 json 数据,剩下的就是从中取得关心的部分。从上一节的示例可以看出,Web 接口返回的数据都是按时间顺序排列的,而发版数据只记录某一个断面的指标 (精确到小时) ,一般是选取流量高峰时刻。结合以上两个需求,首先需要按时间的顺序列出总流量的列表,用户根据这个信息选取流量高峰,或者选择某个时刻;然后根据选取的时刻,所有指标数据向这个时刻看齐,保证数据的一致性。
例如对于上一节获取到的数据,如何选取总流量呢:
{ "p2pu6d41u91cf":Array[48], "dcdnu6d41u91cf":Array[48], "third_httpu6d41u91cf":Array[48], "onecloudu6d41u91cf":Array[48], "relayu6d41u91cf":Array[48], "u603bu6d41u91cf":Array[48], "cdnu603bu6d41u91cf":Array[48], "btu603bu6d41u91cf":Array[48], "onecloud-httpu603bu6d41u91cf":[ [ 1642140000000, 84124693465.349 ], [ 1642143600000, 90980062017.307 ], [ 1642147200000, 86051227112.929 ], ... ] }整个 json 的结构是这样的:
- key-value 构成的二值数组 (更像 pair) 是最基本的单位,代表一个时刻的流量值
- pair 组成的数组构成一个维度,代表某一分量随时间变化的曲线,每条曲线的维度由名称确定
- 多个维度组合成一个最终的 json object
首先要确认获取哪个维度,json 中的汉字会被转码为 utf8,"u603bu6d41u91cf" 代表的就是"总流量"了,在 jq 中可以直接指定汉字:
$ cat temp.txt | jq '."总流量"' [ [ 1642140000000, 1126527342256.8 ], [ 1642143600000, 1176541641172.7 ], [ 1642147200000, 1177760044237.3 ], ... ]注意这里汉字必需用引号包裹,否则会报错:
jq: error: syntax error, unexpected INVALID_CHARACTER (Unix shell quoting issues?) at <top-level>, line 1: .总流量 jq: error: try .["field"] instead of .field for unusually named fields at <top-level>, line 1: .总流量 jq: 2 compile errors接着通过数组符将数据一维化 (去掉最外层数组),方便后续处理:
$ cat temp.txt | jq '."总流量"[]' [ 1642140000000, 1126527342256.8 ] [ 1642143600000, 1176541641172.7 ] [ 1642147200000, 1177760044237.3 ] ...将 key-value 的二值数组也去掉,这个费了很大周折,不过总算找到了的办法:
$ cat temp.txt | jq '."总流量"[]|.[0],.[1]' 1642140000000 1126527342256.8 1642143600000 1176541641172.7 1642147200000 1177760044237.3 ...使用了 jq 的内置管道,在数组中挑选要提取的元素下标,关于 jq 语法可参考文末链接。
简化为这样的形式,再展示给用户就方便多了:
# @param data-file # @param unit # @param select-time [option] function pick_time() { local file="$1" local unit="$2" local selecttime="" if [ $# -gt 2 ]; then selecttime="$3" fi local n=0 local m=0 local line="" local stamp=0 local time=() local value=() local match=-1 while read line; do if [ "$(($n%2))" -eq 0 ]; then # time field at event line stamp=$(($line/1000)) if [ ${is_macos} -eq 1 ]; then time[$m]=$(date -j -r "$stamp" "+%Y%m%d%H") #time[$m]=$(date -j -f "%Y%m%d%H" -r "$stamp") else time[$m]=$(date -d "@$stamp" "+%Y%m%d%H") fi if [ -z "$selecttime" ]; then if [ ${is_macos} -eq 1 ]; then # macos builtin echo does not recognize -n #echo "$stamp" /bin/echo -n "$m: ${time[$m]} " else echo -n "$m: ${time[$m]} " fi else if [ "$selecttime" = "${time[$m]}" ]; then # match selected time picked_time="$selecttime" match=$m fi fi else # value field at odd line value[$m]="$line" if [ -z "$selecttime" ]; then if [ "${unit:0:1}" = ' ' ]; then # unit start with a space means no byte transfer echo "${value[$m]}${unit}" else # append their unit after B/KB/MB/GB format_bytes "${value[$m]}" fi else if [ $match -eq $m ]; then # the value is what we want picked_value="${value[$m]}" #echo "matched: $picked_value" fi fi m=$(($m+1)) fi n=$(($n+1)) done < $file if [ $n -lt 2 ]; then echo "no data" picked_time=0 picked_value=0 return 1 fi if [ -z "$selecttime" ]; then # only prompt user when: # 1. no time provided read -p "pick a time to record (-1 to quit): " n if [ $n -lt 0 ]; then exit 1 fi picked_time="${time[$n]}" picked_value="${value[$n]}" echo "pick ${picked_time} ${picked_value}" elif [ $match -eq -1 ]; then # only prompt user when: # 2. provided time but no match # # call myself without 2nd parameter to make prompt echo "given time ${selecttime} not find" pick_time "$file" "$unit" else echo "pick ${picked_time} ${picked_value}" fi }脚本接受的三个参数分别是:
- data-file:上面 json 过滤掉括号后的结果,key、value 交替存放,key 位于奇数行,value 位于偶数行
- unit:展示给用户的数值单位,如 B/KB/MB/GB ...
- selecttime:用户选择的时刻
pick_time 用于三个场景:
- 没有提供第三个参数 (selecttime) 时,展示整个列表,供用户选择;
- 提供了 selecttime 且有数据匹配时,返回匹配的数据;
- 提供了 selecttime 但没有数据匹配时,展示整个列表,供用户重新选择;
第一次展示时走的是场景一;后面再展示时走的是场景三;场景二一般不会出现,只有当后台服务返回的数据集缺失了数据时才会命中,可以起到提醒用户的效果,避免数据不一致。对整个脚本做个简单说明:
- 主体就是一个循环遍历 json 数据源 (去除括号)
- 根据奇偶行将 key 和 value 分别放入 stamp() 和 value() 数组
- 时间戳单位为毫秒,需要转换到 epoch (整点),再基于 date 命令把 unix time 转换为 YYYYMMDDHH 的形式,注意 mac 和 linux 上的 date 命令有差异,需要分平台处理
- 没有给定 selecttime 时,打印转换为时间字符串的 key,这里使用 echo -n 来避免换行,因为紧接着要打印 value 部分,注意 mac 和 linux 上的 echo 命令有差异,需要分平台处理 (mac 上的 bultin echo 不识别 -n 参数,需要调用 echo 命令)
- 如果给定了 selecttime,进行对比,若匹配则记录用户选择的索引至 match 中,用于稍后的 value 匹配
- 处理 value 时也是差不多的逻辑:不给定 selecttime 就输出 value 的值和单位;给定 selecttime 且当前索引匹配 match 值,则记录 value 至 picked_value,这是一个全局变量,稍后可以让调用函数引用来获取结果
- 循环结束后,若未给定 selecttime,要求用户输入索引来选择一个时间,记录对应的 time 和 value 至 picked_time 与 picked_value
- 若给定 selecttime 但未能匹配,再次调用两参数的自己,来打印全部数据供用户选择
- 若给定 selecttime 匹配了,打印用户选择时间的对应值
一般 value 的单位是字节,遇到流量这种上 T 级别的数据,直接给展示给用户一长串数据非常没有可读性,通过 format_bytes 可以将字节按数量自动转换为合适的单位 (B/KB/MB/GB):
# @brief format size into B/KB/MB/GB according to bytes amount # @param size function format_bytes() { local size="$1" echo "${size}" | awk '{ if ($1 <= 1024) { print $1 " B" } else if ($1 <= 1024*1024) { print $1/1024 " KB" } else if ($1 <= 1024*1024*1024) { print $1/1024/1024 " MB"} else { print $1/1024/1024/1024 " GB"} }' }这是一个基于 awk 的实现。除了字节单位,还有一些是百分比,如果对它们也进行转换就闹错误了,可以在这种单位前给一个空格来避免这种转换,例如 " %"。
最终的效果可以看下面这段输出:
$ sh fetch_iyuntu.sh -v '3.0.0.112' -p 'pc' request flow ok 0: 2022011519 1487.74 GB 1: 2022011520 1563.08 GB 2: 2022011521 1636.64 GB 3: 2022011522 1618.64 GB 4: 2022011523 1443.26 GB 5: 2022011600 1205.57 GB 6: 2022011601 1096.95 GB 7: 2022011602 905.025 GB 8: 2022011603 654.045 GB 9: 2022011604 482.283 GB 10: 2022011605 391.029 GB 11: 2022011606 355.738 GB 12: 2022011607 390.631 GB 13: 2022011608 589.954 GB 14: 2022011609 827.38 GB 15: 2022011610 1050.17 GB 16: 2022011611 1242.52 GB 17: 2022011612 1348.08 GB 18: 2022011613 1405.8 GB 19: 2022011614 1472.75 GB 20: 2022011615 1492.5 GB pick a time to record (-1 to quit): 观察列表,发现昨天晚上 21 点是流量高峰,输入索引 2 来收集对应的指标 (场景一);后面就不需要用户再选择了,脚本会自动匹配 2022011521 的时刻去选择其它指标数据 (场景三);如果某个指标的数据列表没有 2022011521 这个时刻,脚本会自动列出指标的全部时刻供用户重新选择 (场景二),一般是由于后台发版数据缺失了 (数据量太大算不过来,偶尔发生),一般输入 -1 退出脚本重新选择一个其它时刻再跑一遍。
把上面的都结合在一起,就是一个完整的拉取和解析总流量的过程啦:
# @param: starttime # @param: endtime # @param: version # @param: clienttype # @param: cookie # @param: select-time [option] function fetch_flow() { local starttime="$1" local endtime="$2" local version="$3" local clienttype="$4" local cookie="$5" local selecttime="" if [ $# -gt 5 ]; then selecttime="$6" fi local data="start=${starttime}&end=${endtime}&method=p2pflow&version=${version}&vipLevel=all&clusterItem=cluster_hour&clientType=${clienttype}" curl -s "http://${HOST}/client/api/xxxxxxxxxxxx/" -H "Accept: */*" -H "Connection: keep-alive" -H "Content-Type: application/x-www-form-urlencoded; charset=UTF-8" -H "Accept-Encoding: gzip, deflate" -H "Origin: ${HOST}" -H "Referer: http://${HOST}/stability/main?typeName2=total_flow&typeName2=cluster_hour&typeName2=${clienttype}&datepicker0=${starttime}&datepicker1=${endtime}" -H "X-Requested-With: XMLHttpRequest" --cookie "$cookie" -d "$data" --output temp.gzip if [ $? -eq 0 ]; then echo "request flow ok" cat temp.gzip | gunzip > temp.txt # to see if 'null' if [ $? -eq 0 -a "$(head -c 4 temp.txt)" != "null" ]; then jq -r '."总流量"[]|.[0],.[1]' temp.txt > data.txt pick_time "data.txt" "" "$selecttime" else echo "null" fi else echo "request flow failed" fi }增加了以下内容:
- 当选择的时间范围内没有任何数据时,temp.txt 将仅包含四个字符:null,这可以通过 head 截取来判断,没有数据时直接输出 null 并跳过这个指标的获取
- jq 解析"总流量"维度并将数据写入 data.txt 文件中
- pick_time 从 data.txt 文件中获取数据,由于第一次请求总流量 (version=pc-all) 时 selecttime 还为空,所以它仅展示列表,当它返回后用户已经选好了时刻;如果是请求版本流量 (version=3.0.0.112) selecttime 不为空,将直接从 data.txt 中选择对应时刻的数据并记录在 picked_value 中,供后面使用
至此,完成了第一个指标从拉取数据、解析内容到获取指标数据的全过程。
联接起来
有了第一个,第二、第三……就容易多了,copy & paste 再改改就行了。来看下脚本 main 函数是如何联接并驱动这一切的:
function main() { local version="" local endtime=$(date +%s) local starttime=0 local cookiefile="cookie.txt" local clienttype="android" #os="${OSTYPE/"darwin"//}" local OSTYPE=$(uname -s) local os="${OSTYPE/"Darwin"//}" if [ "$os" != "$OSTYPE" ]; then # darwin: macos is_macos=1 fi while getopts 'hv:p:s:e:c:' flag; do case "${flag}" in v) version="${OPTARG}" ;; p) clienttype="${OPTARG}" ;; s) if [ ${is_macos} -eq 1 ]; then # convert date as some format to stamp only supported on mac starttime=$(date -j -f "%Y%m%d%H" "${OPTARG}" "+%s") else # date on linux only recongnize date part.. # so: 2021090914 = 20210909 + 14 * 3600 starttime=$(date -d "$((${OPTARG}/100))" "+%s") starttime=$((${starttime}+${OPTARG}%100*3600)) fi if [ $? -ne 0 ]; then echo "convert starttime failed" return 1 fi ;; e) if [ ${is_macos} -eq 1 ]; then # convert date as some format to stamp only supported on mac endtime=$(date -j -f "%Y%m%d%H" "${OPTARG}" "+%s") else # date on linux only recongnize date part.. # so: 2021090914 = 20210909 + 14 * 3600 endtime=$(date -d "$((${OPTARG}/100))" "+%s") endtime=$((${endtime}+${OPTARG}%100*3600)) fi if [ $? -ne 0 ]; then echo "convert endtime failed" return 1 fi ;; c) cookiefile="${OPTARG}" ;; h|*) echo "Usage: sh fetch_iyuntu.sh -v version [-h] [-s starttime(YYYYMMDDHH)] [-e endtime(YYYYMMDDHH)] [-c cookiefile] [-p platform]" return 0 ;; esac done if [ -z "$version" ]; then echo "no version specified" return 1 fi echo "query data for platform: ${clienttype}" if [ $starttime -eq 0 ]; then starttime=$(($endtime-86400)) # default 1 day ago fi echo "starttime: $starttime, endtime: $endtime" if [ "$endtime" -lt "$starttime" ]; then echo "invalid start & end time" return 1 fi if [ ! -f "${cookiefile}" ]; then echo "cookie file not find: ${cookiefile}" return 1 fi local cookie=$(cat ${cookiefile}) #echo "cookie: $cookie" # 1. fetch total flow first to determine time fetch_flow "$starttime" "$endtime" "${clienttype}-all" "${clienttype}" "$cookie" select_time="$picked_time" total_flow="$picked_value" # 2. fetch flow of that version fetch_flow "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "$select_time" version_flow="$picked_value" # 3. fetch slow speed ratio fetch_slow_speed "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" slow_speed="$picked_value" # 4. fetch nat connectivity fetch_nat_connectivity "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" nat_connectivity="$picked_value" # 5. fetch total download speed, 0 - normal user fetch_total_download_speed "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "0" "$select_time" total_download_speed_for_normal_user="$picked_value" # 6. fetch total download speed, 2 - svip user fetch_total_download_speed "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "2" "$select_time" total_download_speed_for_svip_user="$picked_value" # 7. fetch vod result success, 0 - normal user fetch_vod_result_success "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "0" "$select_time" vod_result_success_for_normal_user="$picked_value" # 8. fetch vod result success, 2 - svip user fetch_vod_result_success "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "2" "$select_time" vod_result_success_for_svip_user="$picked_value" # 9. fetch vod p2p share ratio, 0 - normal user fetch_vod_p2p_share_ratio "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "0" "$select_time" vod_p2p_share_ratio_for_normal_user="$picked_value" #10. fetch vod p2p share ratio, 2 - svip user fetch_vod_p2p_share_ratio "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "2" "$select_time" vod_p2p_share_ratio_for_svip_user="$picked_value" if [ "${clienttype}" != "pc" ]; then #11. fetch ts download speed, 0 - normal user fetch_ts_download_speed "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "0" "$select_time" ts_download_speed_for_normal_user="$picked_value" #12. fetch ts download speed, 2 - svip user fetch_ts_download_speed "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "2" "$select_time" ts_download_speed_for_svip_user="$picked_value" #13. fetch ts result success, 0 - normal user fetch_ts_result_success "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "0" "$select_time" ts_result_success_for_normal_user="$picked_value" #14. fetch ts result success, 2 - svip user fetch_ts_result_success "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "2" "$select_time" ts_result_success_for_svip_user="$picked_value" #15. fetch ts p2p share ratio, 0 - normal user, 3 - downloading fetch_ts_p2p_share_ratio "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "0" "3" "$select_time" ts_p2p_share_ratio_for_normal_user="$picked_value" #16. fetch ts p2p share ratio, 2 - svip user, 3 - downloading fetch_ts_p2p_share_ratio "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "2" "3" "$select_time" ts_p2p_share_ratio_for_svip_user="$picked_value" else # pc use ts playing share ratio instead of ts downloading #11. fetch ts p2p share ratio, 2 - svip user, 1 - playing fetch_ts_p2p_share_ratio "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "2" "1" "$select_time" ts_p2p_share_ratio_for_svip_user="$picked_value" fi #17. fetch ts flow ratio fetch_ts_play_flow "$starttime" "$endtime" "$version" "${clienttype}" "$cookie" "$select_time" local ts_play_flow_version="$picked_value" fetch_ts_play_flow "$starttime" "$endtime" "${clienttype}-all" "${clienttype}" "$cookie" "$select_time" local ts_play_flow_all="$picked_value" ts_play_flow_ratio=$(echo "${ts_play_flow_version},${ts_play_flow_all}" | awk -F',' '{print $1*100/$2}') print_statistic "${clienttype}" }做个简单说明:
- 脚本可以接收 6 个参数
- -v version,指定收集数据指标的版本
- -p platform,指定收集数据的端,默认为 android,可以指定 pc 或其它端
- -e endtime,指定结束时间,格式为 YYYYMMDDHH,精确到小时,如果不指定,默认为当前时间
- -s starttime,指定开始时间,格式同上,如果不指定,默认为结束时间前推 24 小时
- -c cookiefile,指定 cookie 内容,默认为 cookie.txt
- -h,输出 usage
- 注:mac 上可以直接将字符串 YYYYMMDDHH 转换为 unix time;linux 上不能,需要两步,第一步转换为到日期的时间戳,第二步加上小时数
- 完整性检查,没有版本号、cookie 文件、结束时间小于开始时间等都是致命错误,直接退出
- fetch_flow 获取总流量,记录用户选择时间 (select_time) 和总流量 (total_flow)
- 分别获取各个分量
- fetch_flow 获取版本流量 (version_flow)
- fetch_slow_speed 获取慢速比 (slow_speed)
- fetch_nat_connectivity 获取 NAT 连通率 (nat_connectivity)
- fetch_total_download_speed 分别获取普通 (total_download_speed_for_normal_user) 和 svip 用户总速度 (total_download_speed_for_svip_user)
- fetch_vod_result_success 分别获取普通 (vod_result_success_for_normal_user) 和 svip 用户原画下载成功率 (vod_result_success_for_svip_user)
- fetch_vod_p2p_share_ratio 分别获取普通 (vod_p2p_share_ratio_for_normal_user) 和 svip 用户原画下载分享率 (vod_p2p_share_ratio_for_svip_user)
- fetch_ts_download_speed 分别获取普通 (ts_download_speed_for_normal_user) 和 svip 用户转码下载速度 (ts_download_speed_for_svip_user)
- fetch_ts_result_success 分别获取普通 (ts_result_success_for_normal_user) 和 svip 用户转码下载成功率 (ts_result_success_for_svip_user)
- fetch_ts_p2p_share_ratio 分别获取普通 (ts_share_ratio_for_normal_user) 和 svip 用户转码下载分享率 (ts_share_ratio_for_svip_user)
- fetch_ts_play_slow 分别获取版本 (ts_play_flow_version) 和总的转码播放流量 (ts_play_flow_all),最后计算出转码播放流量占比 (ts_play_flow_ration)
- 注:pc 端转码指标只有 svip 转码播放分享率 (ts_share_ratio_for_svip_user)
- 最后打印获取到的指标数据 (print_statistic)
在每个 fetch_xxx 函数获取指标数据后都跟着一个赋值操作,将 pick_value 放入对应的全局变量中,在最后打印指标信息时 (print_statistic) 会用到它们:
# @param: clienttype function print_statistic() { local clienttype="$1" local flow_ratio="0" local result_success="0" echo "=======================================" echo "total flow: $(format_bytes ${total_flow})" echo "version flow: $(format_bytes ${version_flow})" # eat divided by zero error flow_ratio=$(echo "${version_flow},${total_flow}" | awk -F',' '{print $1*100/$2}' 2>/dev/null) echo "flow ratio: ${flow_ratio} %" echo "slow speed: ${slow_speed} %" echo "nat connectivity: ${nat_connectivity} %" echo "total download speed (normal) $(format_bytes ${total_download_speed_for_normal_user})/s" echo "total download speed (svip) $(format_bytes ${total_download_speed_for_svip_user})/s" result_success=$(echo "${vod_result_success_for_normal_user}" | awk '{print $1*100}') echo "vod result success (normal) ${result_success} %" result_success=$(echo "${vod_result_success_for_svip_user}" | awk '{print $1*100}') echo "vod result success (svip) ${result_success} %" echo "vod p2p share ratio (normal) ${vod_p2p_share_ratio_for_normal_user} %" echo "vod p2p share ratio (svip) ${vod_p2p_share_ratio_for_svip_user} %" # pc has vod downloading & ts playing & NO ts downloading if [ "${clienttype}" != "pc" ]; then echo "ts download speed (normal) $(format_bytes ${ts_download_speed_for_normal_user})/s" echo "ts download speed (svip) $(format_bytes ${ts_download_speed_for_svip_user})/s" result_success=$(echo "${ts_result_success_for_normal_user}" | awk '{print $1*100}') echo "ts result success (normal) ${result_success} %" result_success=$(echo "${ts_result_success_for_svip_user}" | awk '{print $1*100}') echo "ts result success (svip) ${result_success} %" echo "ts p2p share ratio (normal) ${ts_p2p_share_ratio_for_normal_user} %" echo "ts p2p share ratio (svip) ${ts_p2p_share_ratio_for_svip_user} %" else echo "ts play share ratio (svip) ${ts_p2p_share_ratio_for_svip_user} %" fi echo "ts play flow ratio ${ts_play_flow_ratio} %" }这个函数还负责计算版本流量占比,注意这里采用了 awk 来进行浮点运算,shell 内建的运算只支持整型。
最后来看下运行效果吧:
======================================= total flow: 1636.64 GB version flow: xxxx.xx GB flow ratio: xx.xxxx % slow speed: x.xxxxx % nat connectivity: xx.xxxx % total download speed (normal) x.xxxxx MB/s total download speed (svip) xx.xxxx MB/s vod result success (normal) xx.xxxx % vod result success (svip) xx.xxxx % vod p2p share ratio (normal) xx.xx % vod p2p share ratio (svip) xx.xx % ts play share ratio (svip) xx.xx % ts play flow ratio xx.xxxx %自从有了这个脚本,填个灰度发版指标就是分分钟的事儿了,程序员的效率又有提升,节约下的时间又可以愉快的摸鱼了~
结语
本文介绍了一种使用 shell 脚本自动获取发版指标数据的方法,主要有以下几个关键点:
- curl 基于浏览器 cookie 访问 web 服务器获取指标数据
- jq 解析复杂 json 格式数据
- pick_time 从 key-value 列表中提取某个时刻的指标值
其中第二点又是关键中的关键,之前也用 jq 做过 json 数据的解析,但处理这样复杂的 json 形式还是头一遭,当时差点就在这里卡壳了,对 jq 语法还需要系统的学习一下,不然遇到更复杂的数据形式,可能又要卡壳 ?。
说一下工具与效率的问题,在比较强调流程的公司干活,不断在工作中积累一些工具、脚本是非常必要的,不然随着工作量的加码,个人精力会被消耗在日常重复工作中,导致效率降低。同样一件事,刚入职时花一个小时搞定,入职几年了还需要差不多的时间来搞定,绝对需要考虑下有没有优化空间。把一些流程化的、可自动化的工作提炼出来用脚本、工具完成,会极大的节约时间、保证准确性并将注意力集中于该集中的地方,这就是所谓的工欲善其事、必先利其器吧。
后记
这个脚本总体上已经很方便了,美中不足的地方是前面提到的获取浏览器 cookie,如何自动登录 web 并记录 cookie?这个我又有一系列探索,后面会写成一篇单独的文章分享出来。
参考
[3]. linux工具之jq
[4]. mac date命令
[6]. linux shell实现随机数多种方法(date,random,uuid)