- A+
实践环境
CentOS-7-x86_64-DVD-1810
Docker 19.03.9
Kubernetes version: v1.20.5
开始之前
1台Linux操作或更多,兼容运行deb,rpm
确保每台机器2G内存或以上
确保当控制面板的结点机,其CPU核数为双核或以上
确保集群中的所有机器网络互连
目标
- 安装一个
Kubernetes集群控制面板 - 基于集群安装一个
Pod network以便集群之间可以相互通信
安装指导
安装Docker
安装过程略
注意,安装docker时,需要指Kubenetes支持的版本(参见如下),如果安装的docker版本过高导致,会提示以下问题
WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.5. Latest validated version: 19.03 安装docker时指定版本
sudo yum install docker-ce-19.03.9 docker-ce-cli-19.03.9 containerd.io 如果没有安装docker,运行kubeadm init时会提示以下问题
cannot automatically set CgroupDriver when starting the Kubelet: cannot execute 'docker info -f {{.CgroupDriver}}': executable file not found in $PATH [preflight] WARNING: Couldn't create the interface used for talking to the container runtime: docker is required for container runtime: exec: "docker": executable file not found in $PATH 安装kubeadm
如果没有安装的话,先安装kubeadm,如果已安装,可通过apt-get update && apt-get upgrade或yum update命令更新kubeadm最新版
注意:更新kubeadm过程中,kubelet每隔几秒中就会重启,这个是正常现象。
其它前置操作
关闭防火墙
# systemctl stop firewalld && systemctl disable firewalld 运行上述命令停止并禁用防火墙,否则运行kubeadm init时会提示以下问题
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly 修改/etc/docker/daemon.json文件
编辑/etc/docker/daemon.json文件,添加以下内容
{ "exec-opts":["native.cgroupdriver=systemd"] } 然后执行systemctl restart docker命令重启docker
如果不执行以上操作,运行kubeadm init时会提示以下问题
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ 安装socat,conntrack等依赖软件包
# yum install socat conntrack-tools 如果按未安装上述依赖包,运行kubeadm init时会提示以下问题
[WARNING FileExisting-socat]: socat not found in system path error execution phase preflight: [preflight] Some fatal errors occurred:` [ERROR FileExisting-conntrack]: conntrack not found in system path` 设置net.ipv4.ip_forward值为1
设置net.ipv4.ip_forward值为1,具体如下
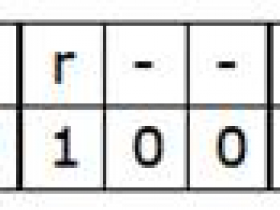
# sysctl -w net.ipv4.ip_forward=1 net.ipv4.ip_forward = 1 说明:net.ipv4.ip_forward如果为0,则表示禁止转发数据包,为1则表示允许转发数据包,如果net.ipv4.ip_forward值不为1,运行kubeadm init时会提示以下问题
ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1 以上配置临时生效,为了避免重启机器后失效,进行如下设置
# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf 注意:网上有推荐以下方式进行永久配置的,但是笔者试过,实际不起作用
# echo "sysctl -w net.ipv4.ip_forward=1" >> /etc/rc.local # chmod +x /etc/rc.d/rc.local 设置net.bridge.bridge-nf-call-iptables值为1
做法参考 net.ipv4.ip_forward设置
注意:上文操作,在每个集群结点都要实施一次
初始化控制面板结点
控制面板组件运行的机器,称之为控制面板结点,包括 etcd (集群数据库) 和 API Server (供 kubectl 命令行工具调用)
-
(推荐)如果打算升级单个控制面板
kubeadm集群为高可用版(high availability),应该为kubeadm init指定--control-plane-endpoint参数选项以便为所有控制面板结点设置共享endpont。该endpont可以是DNS名称或者本地负载均衡IP地址。 -
选择一个网络插件,并确认该插件是否需要传递参数给
kubeadm init,这取决于你所选插件,比如使用flannel,就必须为kubeadm init指定--pod-network-cidr参数选项 -
(可选)1.14版本开始,
kubeadm会自动检测容器运行时,如果需要使用不同的容器运行时,或者有多于1个容器运行时的情况下,需要为kubeadm init指定--cri-socket参数选项 -
(可选)除非指定了其它的,
kubeadm使用与默认网关关联的网络接口为指定控制面板结点API服务器设置advertise地址。如果需要指定其它的网络接口,需要为kubeadm init指定apiserver-advertise-address=<ip-address>参数选项。发布IPV6Kubernetes集群,需要为kubeadm init指定--apiserver-advertise-address参数选项,以设置IPv6地址,形如--apiserver-advertise-address=fd00::101 -
(可选)运行
kubeadm init之前,先运行kubeadm config images pull,以确认可连接到gcr.io容器镜像注册中心
如下,带参数运行kubeadm init以便初始化控制面板结点机,运行该命令时会先执行一系列的预检,以确保机器满足运行kubernetes。如果预检发现错误,则自动退出程序,否则继续执行,下载并安装集群控制面板组件。这可能会花费几分钟
# kubeadm init --image-repository=registry.aliyuncs.com/google_containers --kubernetes-version stable --pod-network-cidr=10.244.0.0/16 [init] Using Kubernetes version: v1.20.5 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local localhost.localdomain] and IPs [10.96.0.1 10.118.80.93] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost localhost.localdomain] and IPs [10.118.80.93 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost localhost.localdomain] and IPs [10.118.80.93 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed. [apiclient] All control plane components are healthy after 89.062309 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.20" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node localhost.localdomain as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)" [mark-control-plane] Marking the node localhost.localdomain as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: 1sh85v.surdstc5dbrmp1s2 [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.118.80.93:6443 --token ap4vvq.8xxcc0uea7dxbjlo --discovery-token-ca-cert-hash sha256:c4493c04d789463ecd25c97453611a9dfacb36f4d14d5067464832b9e9c5039a 如上,命令输出Your Kubernetes control-plane has initialized successfully!及其它提示,告诉我们初始化控制面板结点成功。
注意:
-
如果不使用
--image-repository选项指定阿里云镜像,可能会报类似如下错误failed to pull image "k8s.gcr.io/kube-apiserver:v1.20.5": output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 -
因为使用
flannel网络插件,必须指定--pod-network-cidr配置选项,否则名为coredns-xxxxxxxxxx-xxxxx的Pod无法启动,一直处于ContainerCreating状态,查看详细信息,可见类似如下错误信息networkPlugin cni failed to set up pod "coredns-7f89b7bc75-9vrrl_kube-system" network: open /run/flannel/subnet.env: no such file or directory -
--pod-network-cidr选项参数,即Pod网络不能和宿主主机网络相同,否则安装flannel插件后会导致路由重复,进而导致XShell等工具无法ssh宿主机,如下:实践宿主主机网络
10.118.80.0/24,网卡接口ens33--pod-network-cidr=10.118.80.0/24 -
另外,需要特别注意的是,``--pod-network-cidr
的选项参数,必须和kube-flannel.yml文件中的net-conf.json.Network键值保持一致(本例中,键值如下所示,为10.244.0.0/16,所以运行kubeadm init命令时,--pod-network-cidr选项参数值设置为10.244.0.0/16`)# cat kube-flannel.yml|grep -E "^s*"Network" "Network": "10.244.0.0/16",初次实践时,设置
--pod-network-cidr=10.1.15.0/24,未修改kube-flannel.yml中Network键值,新加入集群的结点,无法自动获取pod cidr,如下# kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system kube-flannel-ds-psts8 0/1 CrashLoopBackOff 62 15h ...略 # kubectl -n kube-system logs kube-flannel-ds-psts8 ...略 E0325 01:03:08.190986 1 main.go:292] Error registering network: failed to acquire lease: node "k8snode1" pod cidr not assigned W0325 01:03:08.192875 1 reflector.go:424] github.com/coreos/flannel/subnet/kube/kube.go:300: watch of *v1.Node ended with: an error on the server ("unable to decode an event from the watch stream: context canceled") has prevented the request from succeeding I0325 01:03:08.193782 1 main.go:371] Stopping shutdownHandler...后面尝试修改
kube-flannel.yml中``net-conf.json.Network键值为10.1.15.0/24还是一样的提示(先下载kube-flannel.yml`,然后进行配置修改,再安装网络插件)针对上述
node "xxxxxx" pod cidr not assigned的问题,网上也有临时解决方案(笔者未验证),即为结点手动分配podCIDR,命令如下:kubectl patch node <NODE_NAME> -p '{"spec":{"podCIDR":"<SUBNET>"}}'
参照输出提示,为了让非root用户也可以正常执行kubectl,运行以下命令
# mkdir -p $HOME/.kube # sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config # sudo chown $(id -u):$(id -g) $HOME/.kube/config 可选的,如果是root用户,可运行以下命令
export KUBECONFIG=/etc/kubernetes/admin.conf 记录kubeadm init输出中的kubeadm join,后面需要用该命令添加结点到集群中
token用于控制面板结点和加入集群的结点之间的相互认证。需要安全保存,因为任何拥有该token的人都可以添加认证结点到集群中。 可用 kubeadm token展示,创建和删除该token。命令详情参考kubeadm reference guide.
安装Pod网络插件
**必须基于Pod网络发布一个 Container Network Interface (CNI) ,以便Pod之间可相互通信。Pod网络安装之前,不会启动Cluster DNS (CoreDNS) **
- 注意Pod 网络不能和主机网络重叠,如果重叠,会出问题(如果发现网络发现网络插件的首选Pod网络与某些主机网络之间发生冲突,则应考虑使用合适的CIDR块,然后在执行
kubeadm init时,增加--pod-network-cidr选项替换网络插件YAML中的网络配置. - 默认的,
kubeadm设置集群强制使用 RBAC (基于角色访问控制)。确保Pod网络插件及用其发布的任何清单支持RBAC - 如果让集群使用
IPv6--dual-stack,或者仅single-stack IPv6网络,确保往插件支持IPv6.CNIv0.6.0中添加了IPv6的支持。
好些项目使用CNI提供提供Kubernetes网络支持,其中一些也支持网络策略,以下是实现了Kubernetes网络模型的插件列表查看地址:
可在控制面板结点机上或者拥有kubeconfig 凭据的结点机上通过执行下述命令安装一个Pod网络插件,该插件直接以daemonset的方式安装,并且会把配置文件写入/etc/cni/net.d目录:
kubectl apply -f <add-on.yaml> flannel网络插件安装
手动发布flannel(Kubernetes v1.17+)
# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created 参考连接:https://github.com/flannel-io/flannel#flannel
每个集群只能安装一个Pod网络,Pod网络安装完成后,可通过执行kubectl get pods --all-namespaces命令,查看命令输出中coredns-xxxxxxxxxx-xxx Pod是否处于Running来判断网络是否正常
查看flannel子网环境配置信息
# cat /run/flannel/subnet.env FLANNEL_NETWORK=10.244.0.0/16 FLANNEL_SUBNET=10.244.0.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true flannel网络插件安装完成后,宿主机上会自动增加两个虚拟网卡:cni0 和 flannel.1
# ifconfig -a cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.244.0.1 netmask 255.255.255.0 broadcast 10.244.0.255 inet6 fe80::705d:43ff:fed6:80c9 prefixlen 64 scopeid 0x20<link> ether 72:5d:43:d6:80:c9 txqueuelen 1000 (Ethernet) RX packets 312325 bytes 37811297 (36.0 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 356346 bytes 206539626 (196.9 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255 inet6 fe80::42:e1ff:fec3:8b6a prefixlen 64 scopeid 0x20<link> ether 02:42:e1:c3:8b:6a txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 3 bytes 266 (266.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.118.80.93 netmask 255.255.255.0 broadcast 10.118.80.255 inet6 fe80::6ff9:dbee:6b27:1315 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:d3:3b:ef txqueuelen 1000 (Ethernet) RX packets 2092903 bytes 1103282695 (1.0 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 969483 bytes 253273828 (241.5 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.244.0.0 netmask 255.255.255.255 broadcast 10.244.0.0 inet6 fe80::a49a:2ff:fe38:3e4b prefixlen 64 scopeid 0x20<link> ether a6:9a:02:38:3e:4b txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 30393748 bytes 5921348235 (5.5 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 30393748 bytes 5921348235 (5.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 重新初始化控制面板结点
实践过程中因选项配置不对,在网络插件安装后才发现需要,需要重新执行kubeadm init命令。具体实践操作如下:
# kubeadm reset [reset] Reading configuration from the cluster... [reset] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted. [reset] Are you sure you want to proceed? [y/N]: y [preflight] Running pre-flight checks [reset] Removing info for node "localhost.localdomain" from the ConfigMap "kubeadm-config" in the "kube-system" Namespace [reset] Stopping the kubelet service [reset] Unmounting mounted directories in "/var/lib/kubelet" [reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki] [reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf] [reset] Deleting contents of stateful directories: [/var/lib/etcd /var/lib/kubelet /var/lib/dockershim /var/run/kubernetes /var/lib/cni] The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d The reset process does not reset or clean up iptables rules or IPVS tables. If you wish to reset iptables, you must do so manually by using the "iptables" command. If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar) to reset your system's IPVS tables. The reset process does not clean your kubeconfig files and you must remove them manually. Please, check the contents of the $HOME/.kube/config file. # rm -rf /etc/cni/net.d # rm -f $HOME/.kube/config # 执行完上述命令后,需要重新执行 初始化控制面板结点操作,并且重新安装网络插件
遇到的问题总结
重新执行kubeadm init命令后,执行kubectl get pods --all-namespaces查看Pod状态,发现coredns-xxxxxxxxxx-xxxxxx 状态为ContainerCreating,如下
# kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-7f89b7bc75-pxvdx 0/1 ContainerCreating 0 8m33s kube-system coredns-7f89b7bc75-v4p57 0/1 ContainerCreating 0 8m33s kube-system etcd-localhost.localdomain 1/1 Running 0 8m49s ...略 执行kubectl describe pod coredns-7f89b7bc75-pxvdx -n kube-system命令查看对应Pod详细信息,发现如下错误:
Warning FailedCreatePodSandBox 98s (x4 over 103s) kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "04434c63cdf067e698a8a927ba18e5013d2a1a21afa642b3cddedd4ff4592178" network for pod "coredns-7f89b7bc75-pxvdx": networkPlugin cni failed to set up pod "coredns-7f89b7bc75-pxvdx_kube-system" network: failed to set bridge addr: "cni0" already has an IP address different from 10.1.15.1/24 如下,查看网卡信息,发现 cni0已分配了IP地址(网络插件上次分配的),导致本次网络插件给它设置IP失败。
# ifconfig -a cni0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 10.118.80.1 netmask 255.255.255.0 broadcast 10.118.80.255 inet6 fe80::482d:65ff:fea6:32fd prefixlen 64 scopeid 0x20<link> ether 4a:2d:65:a6:32:fd txqueuelen 1000 (Ethernet) RX packets 267800 bytes 16035849 (15.2 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 116238 bytes 10285959 (9.8 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ...略 flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.1.15.0 netmask 255.255.255.255 broadcast 10.1.15.0 inet6 fe80::a49a:2ff:fe38:3e4b prefixlen 64 scopeid 0x20<link> ether a6:9a:02:38:3e:4b txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0 ...略 解决方法如下,删除配置错误的cni0网卡,删除网卡后会自动重建,然后就好了
$ sudo ifconfig cni0 down $ sudo ip link delete cni0 控制面板结点Toleration(可选)
默认的,出于安全考虑,集群不会在控制面板结点机上调度(schedule) Pod。如果希望在控制面板结点机上调度Pod,比如用于开发的单机Kubernetes集群,需要运行以下命令
kubectl taint nodes --all node-role.kubernetes.io/master- # 移除所有Labels以node-role.kubernetes.io/master打头的结点的污点(Taints) 实践如下
# kubectl get nodes NAME STATUS ROLES AGE VERSION localhost.localdomain Ready control-plane,master 63m v1.20.5 # kubectl taint nodes --all node-role.kubernetes.io/master- node/localhost.localdomain untainted 添加结点到集群
修改新结点的hostname
# hostname localhost.localdomain # hostname k8sNode1 以上通过命令修改主机名仅临时生效,为了避免重启失效,需要编辑/etc/hostname文件,替换默认的localhost.localdomain为目标名称(例中为k8sNode),如果不添加,后续操作会遇到一下错误
[WARNING Hostname]: hostname "k8sNode1" could not be reached [WARNING Hostname]: hostname "k8sNode1": lookup k8sNode1 on 223.5.5.5:53: read udp 10.118.80.94:33293->223.5.5.5:53: i/o timeout 修改/ect/hosts配置,增加结点机hostname到结点机IP(例中为 10.118.80.94)的映射,如下
# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.118.80.94 k8sNode1 ssh登录目标结点机,切换至root用户(如果非root用户登录),然后运行控制面板机器上执行kubeadm init命令输出的kubeadm join命令,录入:
kubeadm join --token <token> <control-plane-host>:<control-plane-port> --discovery-token-ca-cert-hash sha256:<hash> 可在控制面板机上通过运行一下命令查看已有且未过期token
# kubeadm token list 如果没有token,可在控制面板机上通过以下命令重新生成token
# kubeadm token create 实践如下
# kubeadm join 10.118.80.93:6443 --token ap4vvq.8xxcc0uea7dxbjlo --discovery-token-ca-cert-hash sha256:c4493c04d789463ecd25c97453611a9dfacb36f4d14d5067464832b9e9c5039a [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster. 控制面板节点机即master机器上查看是否新增结点
# kubectl get nodes NAME STATUS ROLES AGE VERSION k8snode1 NotReady <none> 74s v1.20.5 localhost.localdomain Ready control-plane,master 7h24m v1.20.5 如上,新增了一个k8snode1结点
遇到问题总结
问题1:运行]kubeadm join时报错,如下
# kubeadm join 10.118.80.93:6443 --token ap4vvq.8xxcc0uea7dxbjlo --discovery-token-ca-cert-hash sha256:c4493c04d789463ecd25c97453611a9dfacb36f4d14d5067464832b9e9c5039a [preflight] Running pre-flight checks error execution phase preflight: couldn't validate the identity of the API Server: could not find a JWS signature in the cluster-info ConfigMap for token ID "ap4vvq" To see the stack trace of this error execute with --v=5 or higher 解决方法:
token过期,运行kubeadm token create命令重新生成token
问题1:运行]kubeadm join时报错,如下
# kubeadm join 10.118.80.93:6443 --token pa0gxw.4vx2wud1e7e0rzbx --discovery-token-ca-cert-hash sha256:c4493c04d789463ecd25c97453611a9dfacb36f4d14d5067464832b9e9c5039a [preflight] Running pre-flight checks error execution phase preflight: couldn't validate the identity of the API Server: cluster CA found in cluster-info ConfigMap is invalid: none of the public keys "sha256:8e2f94e2f4f1b66c45d941c0a7f72e328c242346360751b5c1cf88f437ab854f" are pinned To see the stack trace of this error execute with --v=5 or higher 解决方法:
discovery-token-ca-cert-hash失效,运行以下命令,重新获取discovery-token-ca-cert-hash值
# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //' 8e2f94e2f4f1b66c45d941c0a7f72e328c242346360751b5c1cf88f437ab854f 使用输出的hash值
--discovery-token-ca-cert-hash sha256:8e2f94e2f4f1b66c45d941c0a7f72e328c242346360751b5c1cf88f437ab854f 问题2: cni config uninitialized错误问题
通过k8s自带UI查看新加入结点状态为KubeletNotReady,提示信息如下,
[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful, runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized, CSINode is not yet initialized, missing node capacity for resources: ephemeral-storage] 解决方法: 重新安装CNI网络插件(实践时采用了虚拟机,可能是因为当时使用的快照没包含网络插件),然后重新清理结点,最后再重新加入结点
# CNI_VERSION="v0.8.2" # mkdir -p /opt/cni/bin # curl -L "https://github.com/containernetworking/plugins/releases/download/${CNI_VERSION}/cni-plugins-linux-amd64-${CNI_VERSION}.tgz" | sudo tar -C /opt/cni/bin -xz 清理
如果在集群中使用一次性服务器进行测试,则可以直接关闭这些服务器,不需要进行进一步的清理。可以使用kubectl config delete cluster删除对集群的本地引用(笔者未试过)。
但是,如果您想更干净地清理集群,则应该首先清空结点数据,确保节点数据被清空,然后再删除结点
移除结点
控制面板结点机上的操作
先在控制面板结点机上运行以下命令,告诉控制面板结点机器强制删除待删除结点数据
kubectl drain <node name> --delete-emptydir-data --force --ignore-daemonsets 实践如下:
# kubectl get nodes NAME STATUS ROLES AGE VERSION k8snode1 Ready <none> 82m v1.20.5 localhost.localdomain Ready control-plane,master 24h v1.20.5 # kubectl drain k8snode1 --delete-emptydir-data --force --ignore-daemonsets node/k8snode1 cordoned WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-4xqcc, kube-system/kube-proxy-c7qzs evicting pod default/nginx-deployment-64859b8dcc-v5tcl evicting pod default/nginx-deployment-64859b8dcc-qjrld evicting pod default/nginx-deployment-64859b8dcc-rcvc8 pod/nginx-deployment-64859b8dcc-rcvc8 evicted pod/nginx-deployment-64859b8dcc-qjrld evicted pod/nginx-deployment-64859b8dcc-v5tcl evicted node/k8snode1 evicted # kubectl get nodes NAME STATUS ROLES AGE VERSION localhost.localdomain Ready control-plane,master 24h v1.20.5 目标结点机上的操作
登录到目标结点机上,执行以下命令
# kubeadm reset 上述命令不会重置、清理iptables、IPVS表,如果需要重置iptables还需要手动运行以下命令:
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X 如果需要重置IPVS,必须运行以下命令。
ipvsadm -C 注意:如果无特殊需求,不要去重置网络
删除结点配置文件
# rm -rf /etc/cni/net.d # rm -f $HOME/.kube/config 控制面板结点机上的操作
通过执行命令删除结点kubectl delete node <node name>
###删除未删除的pod # kubectl delete pod kube-flannel-ds-4xqcc -n kube-system --force # kubectl delete pod kube-proxy-c7qzs -n kube-system --force # kubectl delete node k8snode1 node "k8snode1" deleted 删除后,如果需要重新加入结点,可通过 kubeadm join 携带适当参数运行加入
清理控制面板
可以在控制面板结点机上,使用kubeadm reset 命令。点击查看 kubeadm reset 命令参考
参考连接
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/