- A+
了解 PaddleOCR 之前,首先了解一下 PaddlePaddle。飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。目前,飞桨已凝聚超265万开发者,服务企业10万家,基于飞桨开源深度学习平台产生了34万个模型。飞桨助力开发者快速实现AI想法,快速上线AI业务。帮助越来越多的行业完成AI赋能,实现产业智能化升级。
官网:https://www.paddlepaddle.org.cn/
PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库,助力使用者训练出更好的模型,并应用落地。
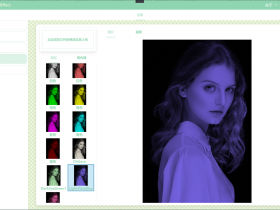
首先看效果图:

(原图)

(识别后,标注的边框是自己根据返回的结果绘出来的)
百度飞桨需要的 Windows 环境
Windows 7/8/10 专业版/企业版 (64bit)
GPU版本支持CUDA 9.0/10.0/10.1/10.2/11.0,且仅支持单卡
Python 版本 2.7.15+/3.5.1+/3.6+/3.7+/3.8+ (64 bit)
pip 版本 20.2.2+ (64 bit)
注意:使用高版本的 python,如:python 3.9 会报错如下:
ERROR: Could not find a version that satisfies the requirement paddlepaddle (from versions: none)
ERROR: No matching distribution found for paddlepaddle
解决方案:
下载支持的版本,例如:3.8.8 版本,下载地址:https://www.python.org/ftp/python/3.8.8/python-3.8.8-amd64.exe
python --version
pip --version
python -c "import platform;print(platform.architecture()[0]);print(platform.machine())"
需要确认Python和pip是64bit,并且处理器架构是x86_64(或称作x64、Intel 64、AMD64)架构,目前PaddlePaddle不支持arm64架构。下面的第一行输出的是”64bit”,第二行输出的是”x86_64”、”x64”或”AMD64”即可。

D:itsvse>python --version
Python 3.8.8D:itsvse>pip --version
pip 20.2.3 from c:program filespython38libsite-packagespip (python 3.8)D:itsvse>python -c "import platform;print(platform.architecture()[0]);print(platform.machine())"
64bit
AMD64
Windows 10 安装 PaddlePaddle CPU 版本
命令:
python -m pip install paddlepaddle==2.0.1 -i https://mirror.baidu.com/pypi/simple
验证安装
安装完成后您可以使用 python 或 python3 进入python解释器,输入import paddle ,再输入 paddle.utils.run_check()
如果出现 PaddlePaddle is installed successfully!,说明您已成功安装。如下图:

(不要执行)卸载命令:
python -m pip uninstall paddlepaddle
安装 paddlehub
命令:
pip install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
下载克隆 PaddleOCR
有条件的使用 git clone 命令下载,没条件的直接下载成压缩包再解压,地址:https://github.com/PaddlePaddle/PaddleOCR
我直接下载后,解压到:D:itsvsePaddleOCR-release-2.0 文件夹下面。
下载推理模型
安装服务模块前,需要准备推理模型并放到正确路径。
检测模型:https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar
方向分类器:https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
识别模型:https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar
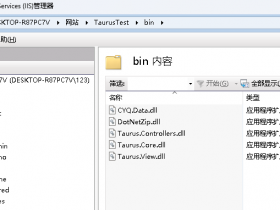
我是下载后,放在了 D:itsvsePaddleOCR-release-2.0deploymodel 文件夹下面,如下图:

安装检测+识别串联服务模块
修改 "D:itsvsePaddleOCR-release-2.0deployhubservingocr_systemparams.py" 配置,如下:
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from __future__ import division
from __future__ import print_functionclass Config(object):
passdef read_params():
cfg = Config()#params for text detector
cfg.det_algorithm = "DB"
cfg.det_model_dir = "D:itsvsePaddleOCR-release-2.0deploymodelch_ppocr_server_v2.0_det_infer"
cfg.det_limit_side_len = 960
cfg.det_limit_type = 'max'#DB parmas
cfg.det_db_thresh = 0.3
cfg.det_db_box_thresh = 0.5
cfg.det_db_unclip_ratio = 1.6
cfg.use_dilation = False#EAST parmas
cfg.det_east_score_thresh = 0.8
cfg.det_east_cover_thresh = 0.1
cfg.det_east_nms_thresh = 0.2#params for text recognizer
cfg.rec_algorithm = "CRNN"
cfg.rec_model_dir = "D:itsvsePaddleOCR-release-2.0deploymodelch_ppocr_server_v2.0_rec_infer"cfg.rec_image_shape = "3, 32, 320"
cfg.rec_char_type = 'ch'
cfg.rec_batch_num = 30
cfg.max_text_length = 25cfg.rec_char_dict_path = "./ppocr/utils/ppocr_keys_v1.txt"
cfg.use_space_char = True#params for text classifier
cfg.use_angle_cls = True
cfg.cls_model_dir = "D:itsvsePaddleOCR-release-2.0deploymodelch_ppocr_mobile_v2.0_cls_infer"
cfg.cls_image_shape = "3, 48, 192"
cfg.label_list = ['0', '180']
cfg.cls_batch_num = 30
cfg.cls_thresh = 0.9cfg.use_pdserving = False
cfg.use_tensorrt = False
cfg.drop_score = 0.5return cfg
使用 cmd 窗口在 D:itsvsePaddleOCR-release-2.0 文件夹下面执行如下命令:
hub install deployhubservingocr_system
备注:修改 hubservingocr_system 下的 python 文件,需要重新安装部署,还是执行如上命令即可。
可能会报错如下:

ModuleNotFoundError: No module named 'imgaug'
ModuleNotFoundError: No module named 'pyclipper'
ModuleNotFoundError: No module named 'lmdb'
使用 pip 安装即可,例如:pip install imgaug
安装成功如下图:
[2021-03-15 15:59:37,549] [ INFO] - Successfully uninstalled ocr_system
[2021-03-15 15:59:38,237] [ INFO] - Successfully installed ocr_system-1.0.0

启动 ocr_system 服务
这里配置参数使用配置文件,首先修改"D:itsvsePaddleOCR-release-2.0deployhubservingocr_systemconfig.json"配置,如下:
{
"modules_info": {
"ocr_system": {
"init_args": {
"version": "1.0.0",
"use_gpu": false
},
"predict_args": {
}
}
},
"port": 8866,
"use_multiprocess": true,
"workers": 2
}
使用如下命令启动服务:
hub serving start -c "D:itsvsePaddleOCR-release-2.0deployhubservingocr_systemconfig.json"

使用 python 客户端测试图片
将需要测试的图片放入 "D:itsvsePaddleOCR-release-2.0docimgs1" 文件夹内,在 D:itsvsePaddleOCR-release-2.0 执行如下命令:

test_hubserving.py 源码如下:
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
sys.path.append(os.path.abspath(os.path.join(__dir__, '..')))from ppocr.utils.logging import get_logger
logger = get_logger()import cv2
import numpy as np
import time
from PIL import Image
from ppocr.utils.utility import get_image_file_list
from tools.infer.utility import draw_ocr, draw_boxesimport requests
import json
import base64def cv2_to_base64(image):
return base64.b64encode(image).decode('utf8')def draw_server_result(image_file, res):
img = cv2.imread(image_file)
image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
if len(res) == 0:
return np.array(image)
keys = res[0].keys()
if 'text_region' not in keys: # for ocr_rec, draw function is invalid
logger.info("draw function is invalid for ocr_rec!")
return None
elif 'text' not in keys: # for ocr_det
logger.info("draw text boxes only!")
boxes = []
for dno in range(len(res)):
boxes.append(res[dno]['text_region'])
boxes = np.array(boxes)
draw_img = draw_boxes(image, boxes)
return draw_img
else: # for ocr_system
logger.info("draw boxes and texts!")
boxes = []
texts = []
scores = []
for dno in range(len(res)):
boxes.append(res[dno]['text_region'])
texts.append(res[dno]['text'])
scores.append(res[dno]['confidence'])
boxes = np.array(boxes)
scores = np.array(scores)
draw_img = draw_ocr(image, boxes, texts, scores, drop_score=0.5)
return draw_imgdef main(url, image_path):
image_file_list = get_image_file_list(image_path)
is_visualize = True
headers = {"Content-type": "application/json"}
cnt = 0
total_time = 0
for image_file in image_file_list:
img = open(image_file, 'rb').read()
if img is None:
logger.info("error in loading image:{}".format(image_file))
continue# 发送HTTP请求
starttime = time.time()
data = {'images': [cv2_to_base64(img)]}
r = requests.post(url=url, headers=headers, data=json.dumps(data))
elapse = time.time() - starttime
total_time += elapse
logger.info("Predict time of %s: %.3fs" % (image_file, elapse))
res = r.json()["results"][0]
logger.info(res)if is_visualize:
draw_img = draw_server_result(image_file, res)
if draw_img is not None:
draw_img_save = "./server_results/"
if not os.path.exists(draw_img_save):
os.makedirs(draw_img_save)
cv2.imwrite(
os.path.join(draw_img_save, os.path.basename(image_file)),
draw_img[:, :, ::-1])
logger.info("The visualized image saved in {}".format(
os.path.join(draw_img_save, os.path.basename(image_file))))
cnt += 1
if cnt % 100 == 0:
logger.info("{} processed".format(cnt))
logger.info("avg time cost: {}".format(float(total_time) / cnt))if __name__ == '__main__':
if len(sys.argv) != 3:
logger.info("Usage: %s server_url image_path" % sys.argv[0])
else:
server_url = sys.argv[1]
image_path = sys.argv[2]
main(server_url, image_path)
使用 .NET Core 客户端测试图片
直接上代码,如下:
using Newtonsoft.Json;
using System;
using System.Net.Http;namespace PaddleOCRDemo
{
class Program
{
static void Main(string[] args)
{
var base64 = Convert.ToBase64String(System.IO.File.ReadAllBytes(System.IO.Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "xzz.jpg")));
Console.WriteLine(base64);
HttpClient client = new HttpClient();
HttpContent content = new StringContent(JsonConvert.SerializeObject(new { images = new string[] { base64 } }));
content.Headers.ContentType = new System.Net.Http.Headers.MediaTypeHeaderValue("application/json");
var ret = client.PostAsync("http://192.168.120.78:8866/predict/ocr_system", content).Result;
if (ret.IsSuccessStatusCode)
{
Console.WriteLine(ret.Content.ReadAsStringAsync().Result);
}
Console.WriteLine("Hello World!");
}
}
}
响应如下
{"msg":"","results":[[{"confidence":0.9994004964828491,"text":"博客统计","text_region":[[23,18],[85,18],[85,33],[23,32]]},{"confidence":0.9951881170272827,"text":"大家好,我是小渣渣,于2015年4月5日开通了博客","text_region":[[22,74],[471,74],[471,93],[22,93]]},{"confidence":0.9985174536705017,"text":"截至此时2021-03-1516:19:52","text_region":[[23,111],[217,111],[217,126],[23,126]]},{"confidence":0.9762932062149048,"text":"累计关于.NET的文章1184篇,累计阅读6844154次,累计评论10505次","text_region":[[24,153],[448,153],[448,165],[24,165]]},{"confidence":0.9847920536994934,"text":"累计所有文章2807 篇,累计阅读14210224次,累计评论19074次","text_region":[[24,177],[414,177],[414,188],[24,189]]}]],"status":"000"}

由于我是用的是虚拟机部署的服务端,有时候会报内存的错误:
Fail to alloc memory of 268418688 size.
临时的解决方案,重新启动服务端。
参考资料:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/deploy/hubserving/readme.md
https://www.paddlepaddle.org.cn/install/quick