- A+
前言
在前三章中我们的案例大量使用到了Thread这个类,通过其原始API,对其进行创建、启动、中断、中断、终止、取消以及异常处理,这样的写法不仅不够优雅(对接下来这篇,我称其为.NET现代化并行编程体系中出现的API而言),并且大部分的接口都是极度复杂和危险的。很幸运,如今.NET已经提供,并且普及了一系列多线程API来帮助我们,优雅且安全的达到相同的目的。
其中,Parallel和Task被一起称为TPL(Task Parallel Library,任务并行库),而这对双子星也就是我们本章的主题之一。如果您对线程基础、并行原理不是很了解,我还是强烈建议先学习前面的章节,万丈高楼平地起是前提是地基打的足够结实!
一、PFX
Parallel Framework,并行框架:用于并行编程,帮助你充分利用CPU的多个核心。
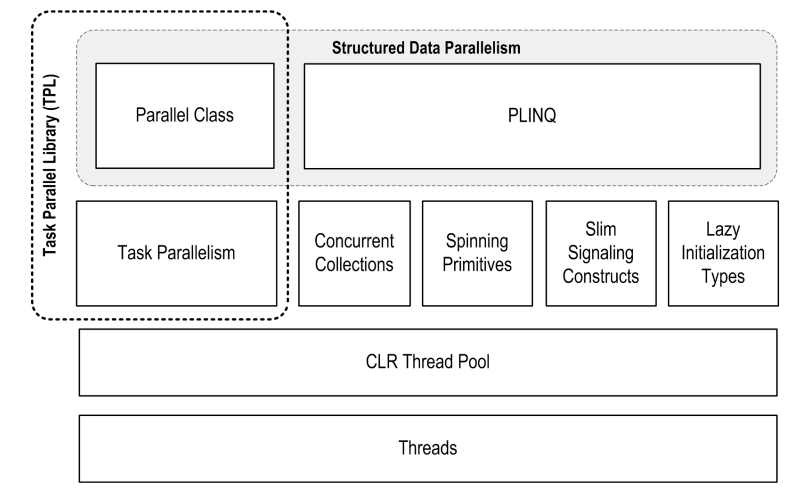
其中PLINQ提供最丰富的功能:它能够自动化并行所有步骤--包括工作分解,多线程执行,并整理结果输出一个序列。它是声明式(declarative)的--你只需构造一个Linq,然后由框架来帮你完成剩下的工作。
Parallel和Task是指令式(imperative)的--你需要自己编写代码来整理结果,甚至分解工作。
| Partitions work | Collates results | |
|---|---|---|
| PLINQ | Yes | Yes |
The Parallel class |
Yes | No |
| PFX’s task parallelism | No | No |
瘦信号Slim Signaling 和 延迟初始化Lazy Initialization我们已经在前面的章节中讲过了,并发集合Concurrent Collections 和 自旋基元Spinning Primitives事实上我们也模拟过,在本章会进一步来讲。
这里可能要解释一下什么是结构化:一切有条不紊、充满合理逻辑和准则的。
在早期使用汇编编程时,为了更加契合计算机运行的实际状况,控制流分为“顺序执行”和“跳转”,这里的跳转也就是著名的--goto,无条件跳转可能会使得代码运行杂乱无章,不可预测。Dijkstra著名的goto有害论的中翻地址:https://www.emon100.com/goto-translation/
一个定律
阿姆达尔定律 Amdahl's law,指出了固定负载(必须顺序执行的部分)情况下,处理器并行运算的最大性能提升
讨论:
综上:
两个密集
CPU密集型(CPU-bound)
也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作CPU读写IO(硬盘/内存)时,IO可以在很短的时间内完成,而CPU还有许多运算要处理,因此,CPU负载很高。
CPU密集表示该任务需要大量的运算,而没有阻塞,CPU一直全速运行。CPU密集任务只有在真正的多核CPU上才可能得到加速(通过多线程),通常,线程数只需要设置为CPU核心数的线程个数就可以了。而在单核CPU上,无论你开几个模拟的多线程该任务都不可能得到加速比,因为CPU总的运算能力就只有这么多。
IO密集型(I/O bound)
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等IO (硬盘/内存) 的读写操作,因此,CPU负载并不高。
IO密集型的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而程序的逻辑做得不是很好,没有充分利用处理器能力。通常就需要开CPU核心数数倍的线程。
CPU密集型 vs IO密集型
CPU密集型任务的特点就是需要进行大量计算(例如:计算圆周率、对视频进行高清解码、矩阵运算等情况)。 这一情况多出现在一些业务复杂的计算和逻辑处理过程中。比如说,现在的一些机器学习和深度学习的模型训练和推理任务,包含了大量的矩阵运算。
IO密集型任务一般涉及到网络、磁盘IO,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
两个大类
使用PFX前需要检查是否真的有必要并行,经过对阿姆达尔定律的了解,我们可以看出,并非使用更多的处理器,性能就能随之水涨船高。如果顺序执行的代码段占了这个工作的三分之二,即使用无数核心,也无法获得哪怕0.5倍的性能提升。
在并行中有可以分为两大类
结构化并行
如果一个工作可以很容易被分解成多个任务,每个任务都能独立高效的执行,那么结构化并行无疑是非常合适的,例如图片处理,光线追踪,密码暴力破解等。
非结构化并行
比方说多线程快排,我们可能需要自己拆解任务然后收集结果
https://cloud.tencent.com/developer/article/1560871
https://github.com/stephen-wang/parallel_quick_sort
二、PINQ
PLINQ就是Parallel LNQ,熟悉LNQ的小伙伴几乎没有额外的学习成本。
只需要在集合后面加个AsParallel(),就可以像平时写LNQ一样继续使用了,Framework会自动的进行工作分解,然后调用核心执行任务,最终将各个核心的结果整理并返回给你。
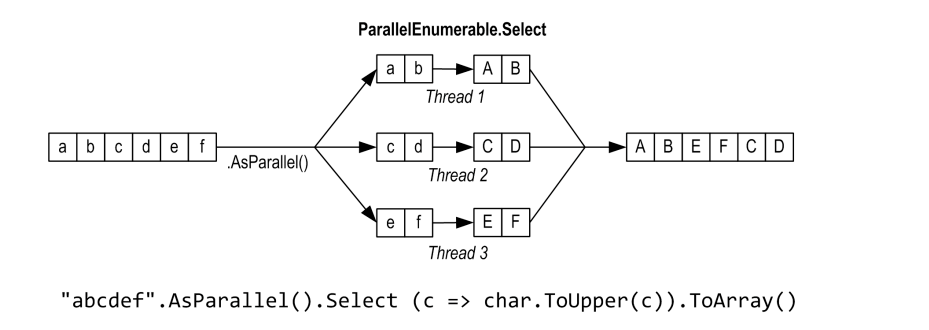
下面的例子利用PLINQ查询3到100,000内的所有素数
注意:这一部分提供的所有代码都可以在 LINQPad 中试验。
IEnumerable<int> numbers = Enumerable.Range(3, 100000 - 3); var parallelQuery = from n in numbers.AsParallel() where Enumerable.Range(2, (int)Math.Sqrt(n)).All(i => n % i > 0) select n; int[] primes = parallelQuery.ToArray(); 当然你也可以
var parallelQuery = numbers.AsParallel().Where(x => Enumerable.Range(2, (int)Math.Sqrt(x)).All(i => x % i > 0)); 但一定不要,先操作再分区等于分了个寂寞
var parallelQuery = numbers.Where(x => Enumerable.Range(2, (int)Math.Sqrt(x)).All(i => x % i > 0)).AsParallel(); 这里我不再过多讨论语法上的东西,大家自己多尝试。
注意事项:
- PLINQ仅适用于本地集合
- 查询过程中各个分区产生的异常会封送到
AggregateException然后重新抛出 - 默认情况下是无序的,但可以使用
AsOrdered有序,但是性能也会有所消耗 - 执行过程必须是线程安全的,否则结果不可靠
- 并行化过程的任务分区,结果整理,以及线程开辟和管理都需要成本
- 如果它认为并行化是没有必要的,会使查询更慢的,会转为顺序执行
- 默认情况下,PLINQ总会认为你执行的是CPU Bound,然后开启核心数个任务
缓冲行为
PLINQ和LINQ一样,也是延迟查询。不同的是,
LINQ完全由使用方通过“拉”的方式驱动:每个元素都在使用方需要时从序列中被提取。
而PLINQ通常使用独立的线程从序列中提取元素,然后通过查询链并行处理这些元素,将结果保存在一个小缓冲区中,以准备在需要的时候提供给使用方。如果使用方在枚举过程中暂停或中断,查询也会暂停或停止,这样可以不浪费 CPU 时间或内存。
你可以通过在AsParallel之后调用WithMergeOptions来调整 PLINQ 的缓冲行为,ParallelMergeOptions有以下几种模式
Default,默认使用AutoBuffered通常能产生最佳的整体效果NoBuffered,禁用缓冲,一旦计算出结果,该元素即对查询的使用者可用AutoBuffered,由系统选择缓冲区大小,结果会在可供使用前输出到缓冲区FullyBuffered,完全缓冲,使用时可以得到全部计算结果(OrderBy,Reverse)。
顺序性
PLINQ的结果默认就是无序的,无法像LINQ那样保证输出顺序与输入顺序一致。如果你希望保持一致,可以在AsParallel()后添加AsOrdered()
var parallelQuery = from n in numbers.AsParallel().AsOrdered() where Enumerable.Range(2, (int)Math.Sqrt(n)).All(i => n % i > 0) select n; 如何序列元素过多,AsOrdered会造成一定性能损失,因为 PLINQ 必须跟踪每个元素的原始位置。你可以通过AsUnordered来取消AsOrdered的效果:这会引入一个“随机洗牌点(random shuffle point)”,允许查询从这里开始不再跟踪。
限制
目前,PLINQ 在能够并行化的操作上有些实用性限制。
-
Aggregate操作符的带种子(seed)的重载是不能并行化的,ForAll可以解决这个问题。其它所有操作符都是可以并行化的,然而使用这些操作符并不能确保你的查询会被并行化。
-
默认情况PLINQ 将检查查询的结构,并且只有在可能导致加速的情况下才会并行化查询。 如果查询结构表明不可能获得加速比,则 PLINQ 将执行查询作为普通的 LINQ to Objects 查询。你可以覆盖这个默认行为,强制开启并行化:
AsParallel().WithExecutionMode(ParallelExecutionMode.ForceParallelism) -
对于那些接受两个输入序列的查询操作符,必须在这两个序列必须都是
ParallelQuery(否则将抛出异常)
Join、GroupJoin、Contact、Union、Intersect、Except和Zip- 这些操作可以并行化,但会使用代价高昂的散列分区(Hash partitioning),有时可能比顺序执行还慢。
- 大多数查询操作都会改变元素的索引位置(包括可能移除元素的那些操作,例如
Where)。这意味着如果你希望使用这些操作,就要在查询开始的地方使用。 - PLINQ会并行的在多个线程上运行,不要执行非线程安全的操作。虽然可以使用前面讲过的同步构造来解决线程安全问题,但是为了达到最佳性能,确保并行能力不会受到限制。
CPU密集型案例
在这个案例中我们下载了约 150,000 个单词放到HashSet中
if (!File.Exists("WordLookup.txt")) // 包含约 150,000 个单词 { var res = new HttpClient().GetByteArrayAsync(new Uri("http://www.albahari.com/ispell/allw .GetAwaiter().GetResult(); File.WriteAllBytes("WordLookup.txt", res); } var wordLookup = new HashSet<string>( File.ReadAllLines("WordLookup.txt"), StringComparer.InvariantCultureIgnoreCase); 然后随机生成一份100,0000万单词的测试数据,由于是并行生成,随机需要考虑线程安全
string[] wordList = wordLookup.ToArray(); var localRandom = new ThreadLocal<Random> ( () => new Random (Guid.NewGuid().GetHashCode()) ); string[] wordsToTest = Enumerable.Range(0, 100_0000).AsParallel() .Select(i => wordList[localRandom.Value.Next(0, wordList.Length)]) .ToArray(); wordsToTest[12345] = "woozsh"; // 引入两个拼写错误 wordsToTest[23456] = "wubsie"; 现在,根据workLookup检查每一个测试数据,最后输出检查到的错误拼写
var query = wordsToTest .AsParallel() .Select((word, index) => new IndexedWord { Word = word, Index = index }) .Where(iword => !wordLookup.Contains(iword.Word)) .OrderBy(iword => iword.Index); //query.Dump(); // 在 LINQPad 中显示输出 foreach (var item in query) { _testOutputHelper.WriteLine($"单词:{item.Word} 拼写错误,索引:{item.Index}"); } 其中IndexedWord是一个自定义的结构体。
struct IndexedWord { public string Word; public int Index; } 使用类也能获得相同的结果,但是性能会有所下降。因为类是引用类型,在堆中分配,只后还有垃圾回收。
这个区别对LINQ而言影响并不是很大,但对于PLNQ而言,基于栈的内存分配相当有利。因为每个线程都有自己的独立栈,可以高度并行化,而堆内存会使多个线程竞争同一个堆(竞态),它是由单一的内存管理器和垃圾回收器管理的。
输出,成功的找到了刚刚故意引入拼写错误的两个单词
单词:woozsh 拼写错误,索引:12345 单词:wubsie 拼写错误,索引:23456 IO密集型案例
Ping
这个案例中我们希望同时ping 2个网站,如果我们运行在的是一个单核机器上,PLINQ 只会默认运行 1 个任务,显然这不是我们希望的。
我们可以使用WithDegreeOfParallelism强制 PLINQ 同时运行指定数量的任务:
注意,PLINQ 切分的任务是由线程池线程执行,线程池的线程并不是取之不尽用之不竭的,具体在下一part讲。
new[] { "www.oreilly.com", "stackoverflow.com", } .AsParallel().WithDegreeOfParallelism(2).Select(site => { var p = new Ping().Send(site); return new { site, Result = p.Status, Time = p.RoundtripTime }; }).ForAll(res => { _testOutputHelper.WriteLine(res.site + $" coast {res.Time}:" + res.Result); }); 输出:
stackoverflow.com coast 173ms : Success www.oreilly.com coast 219ms : Success 监控系统
假设我们要实现一个,希望它不断将来自 4 个安全摄像头的图像合并成一个图像,并在闭路电视上显示。使用下边的Camera类来表示一个摄像头:
class Camera { public readonly int CameraID; public Camera(int cameraID) { CameraID = cameraID; } // 获取来自摄像头的图像: 返回一个字符串来代替图像 public string GetNextFrame() { Thread.Sleep(123); // 模拟获取图像的时间,真实情况下这部分应该是IO密集操作 return "Frame from camera " + CameraID; } } 要获取一个合成图像,我们必须分别在 4 个摄像头对象上调用GetNextFrame。假设操作主要是受 I/O 影响的,即使是在单核机器上,通过并行化我们都能将帧率提升 4 倍。
Camera[] cameras = Enumerable.Range(0, 4) // 创建 4 个摄像头对象 .Select(i => new Camera(i)) .ToArray(); while (true) { string[] data = cameras .AsParallel() .AsOrdered() // 这里这有四个元素,追踪的成本几乎可以忽略不计算 .WithDegreeOfParallelism(4) .Select(c => c.GetNextFrame()).ToArray(); _testOutputHelper.WriteLine(string.Join(", ", data)); // 显示数据... } 在一个 PLINQ 中,仅能调用
WithDegreeOfParallelism一次。如果你需要再次调用它,必须再次调用AsParallel()强制进行查询的合并和重新分区
取消
Parallel切分多个任务,将任务交由线程池线程处理,线程池的任务是支持取消令牌(安全取消协作模式),Parallel同理支持CancellationToken。我们使用之前使用的找PLINQ 素数案例,然后起一个任务,在2ms后取消。
IEnumerable<int> numbers = Enumerable.Range(3, 1000000 - 3); var cancelSource = new CancellationTokenSource(); var parallelQuery = numbers .AsParallel() //.WithMergeOptions(ParallelMergeOptions.FullyBuffered) .WithCancellation(cancelSource.Token) .Where(x => Enumerable.Range(2, (int)Math.Sqrt(x)).All(i => x % i > 0)); Task.Run(() => { Thread.Sleep(2); cancelSource.Cancel(); }); 下面是消费者代码,为了防止打印太多,我们间隔500个打印一次
try { int cnt = 0; foreach (var prime in parallelQuery) { if (cnt % 500 == 0) _testOutputHelper.WriteLine(prime.ToString()); cnt++; } } catch (OperationCanceledException e) { _testOutputHelper.WriteLine("工作已经被取消"); } 结果是打印了一些后抛出OperationCanceledException
23 9341 12941 16879 ... 工作已经被取消 PLINQ 不会直接中止线程,因为这么做是危险的。在取消时,它会等待所有工作线程处理完当前的元素,然后才抛出
OperationCanceledException结束查询。接下来我们会大量出现这种模式,这也是受益PFX底层设计保持高度一致。
聚合
PLINQ 可以在无需额外干预的情况下有效地并行化Sum、Average、Min和Max操作,但自定义聚合Aggregate是个例外。
我们先看一下LINQ 中用Aggregate 是如何实现Sum 的:
int sum = Enumerable.Range(1, 10).Aggregate((pre, cur) => pre + cur); 对于第一次见到Aggregate 的同学,可能会很难理解上面这段代码,那我们先来看一下源码:
public static TSource Aggregate<TSource>( this IEnumerable<TSource> source, Func<TSource, TSource, TSource> func) { if (source == null) ThrowHelper.ThrowArgumentNullException(ExceptionArgument.source); if (func == null) ThrowHelper.ThrowArgumentNullException(ExceptionArgument.func); using (IEnumerator<TSource> enumerator = source.GetEnumerator()) { if (!enumerator.MoveNext()) ThrowHelper.ThrowNoElementsException(); TSource source1 = enumerator.Current; while (enumerator.MoveNext()) source1 = func(source1, enumerator.Current); return source1; } } 就这?是不是简单的令人发指。。没错就是拿到第一个元素,如果没有就抛异常(带seed参数的重载不会哦)然后开始循环迭代,每次迭代用上个元素pre的当前元素cur计算下一次迭代的pre
正因为他如此简单,因为但凡能用Aggregate 解决的问题,都能用循环轻松解决。。那大家为啥不选后面这种更为熟悉的语法呢?其实啊,Aggregate 并非一无是处,在PLINQ 中他是大有可为的,为什么?因为结构化并行啊 ^ v ^ ...
给大家看一个假象:
int sum = Enumerable.Range(1, 100_0000).AsParallel().Aggregate(0,(pre, cur) => pre + cur); 我们在限制中明确指明了,带seed的Aggregate 是不支持并行的,因为多个分区依赖同一个种子,解决方案是ForAll,这里Aggregate其实还提供一种:指定种子工厂,形成局部种子,每个线程独立一个累加器,最终merge时,合并到主累加器
int sum = Enumerable.Range(1, 100_0000).AsParallel().Aggregate( () => 0, (pre, cur) => pre + cur, (main, local) => main + local, x => x); 不要拿大炮打蚊子
"Let’s suppose this is a really long string" .AsParallel() .Aggregate( () => new int[26], (pre, cur) => { int index = char.ToUpper(cur) - 'A'; if (index is >= 0 and <= 26) pre[index]++; return pre; }, (main, local) => main.Zip(local, (a, b) => a + b).ToArray(), x => x); 优化
输入端优化
PLINQ有三种分区策略,来将序列元素分配到各个任务
| Strategy | Element allocation | Relative performance |
|---|---|---|
| Chunk partitioning | Dynamic | Average |
| Range partitioning | Static | Poor to excellent |
| Hash partitioning | Static | Poor |
对于那些需要比较元素的查询操作符(GroupBy、Join、GroupJoin、Intersect、Except、Union和Distinct),PLINQ 总是使用散列分区(Hash partitioning)。散列分区相对低效,因为它必须预先计算每个元素的散列值(Hash code)(拥有同样散列值的元素会在同一个线程中被处理)。如果你发现运行太慢,唯一的选择是调用AsSequential来禁止并行处理。
对于其它所有查询操作符,你可以选择使用范围分区(Range partitioning)或块分区(Chunk partitioning),默认情况下:
- 如果输入序列可以通过索引访问(
Array或IList<T>的实现),PLINQ 选用范围分区,范围分区会为每个工作线程平均的分配元素。如果序列中每个元素处理时间接近,那范围分区是效率最高的分区策略,因为他几乎没有额外的分区成本。
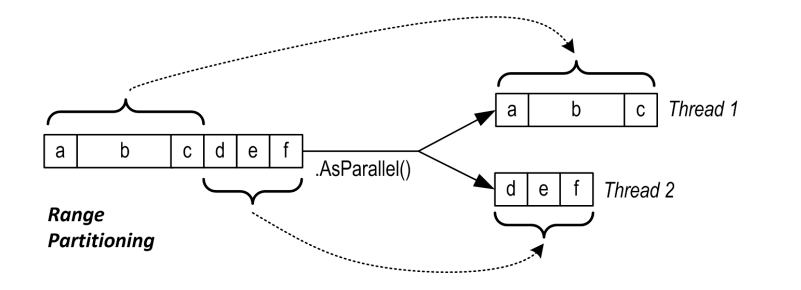
并不一定是相邻分配,也可能采用条纹式(striping)策略
- 否则,PLINQ 选用块分区。块分区定期从序列中抓取小块(一个或两个元素),块大小随查询的进度逐渐变大。如果一个工作线程恰好拿到了一些相对容易的块,它最终会获取更多块,这个设计可以使核心负载均衡。但由于线程从序列中抓取块是需要同步的,因此会有一定的开销和竞争。
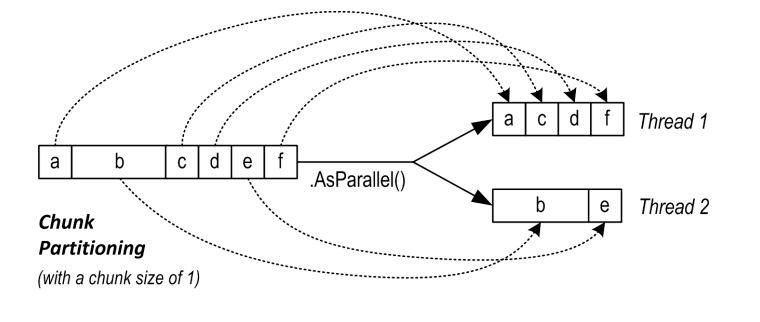
每个元素处理时间接近的适合范围分区,否则块分区更快,你也可以强制指定分区策略:
-
强制使用范围分区
-
使用
ParallelEnumerable下的方法,可以主动激活范围分区。ParallelEnumerable.Range(1,10); ParallelEnumerable.Repeat(1,10); ... -
在输入序列上调用
ToList或ToArray,使其走默认的范围分区(显然,你需要考虑在这里产生的性能开销)。使用
ParallelEnumerable中返回IParallelQuery的方法不需要再调用AsParallel(这里有防呆设计)
-
-
强制使用块分区
-
调用命名空间
System.Collection.Concurrent下Partitioner.Create来封装输入序列int[] numbers = { 3, 4, 5, 6, 7, 8, 9 }; var parallelQuery = Partitioner.Create(numbers, true) .AsParallel() ...第二个参数一定要传
true,表示开启负载均衡,使用动态分区。否则用的是静态索引做范围分区。到底是什么分区,用的时候还是建议自己去看一下源码,这一块策略较多,讲不完。
-
输出端优化
PLINQ 的一个优点是它能够很容易地将并行化任务的结果整理成一个输出序列。有时,我们要在输出序列的每个元素上运行一些方法:
foreach (var item in "abcdef".AsParallel().Select (c => char.ToUpper(c))) { _testOutputHelper.WriteLine(item.ToString()); } 如果不不关心处理顺序,那么可以使用ForAll 跳过对结果的整理来提效:
"abcdef".AsParallel().Select (c => char.ToUpper(c)).ForAll(item => _testOutputHelper.WriteLine(item.ToString())); 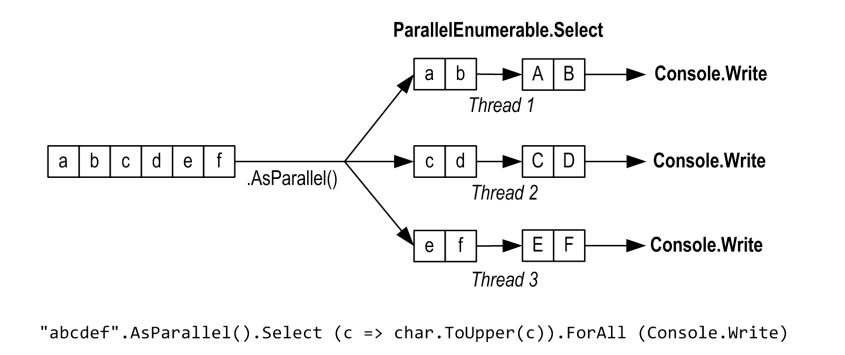
结果的整理和枚举开销相对并不大,只有当序列非常大且执行迅速时才能体现,例如图片处理,整理几百万个像素到输出序列可能形成性能瓶颈。更好的方法是把像素直接写入数组或非托管的内存块,然后使用
Parallel类或Task来管理多线程也可以直接使用ForAll来绕过结果整理。
.NET现代化并行编程系统的双子星即将登场。。。
三、Parallel
命名空间System.Threading.Tasks下的Parallel,API奇了怪的精简
Parallel.Invoke并行执行一组任务ActionParallel.Forfor循环的并行版本Parallel.ForEachforeach循环的并行版本Parallel.ForEachAsyncforeach的异步并行版本,返回一个Task
没了,就这四种。。前面三个方法都会在全部工作完全前阻塞,类似PLINQ,如果发生异常,工作线程会在完成当前迭代后退出,然后讲异常封送到AggregateException 最终抛给调用方。
这些API在你传递远超于处理器核心数量的任务时仍然能够高效功能,他们会对任务进行分区,再对其分配底层的Task,而非对每一个任务创建独立的Task
Invoke
Parallel.Invoke 并行执行一组任务Action,然后等待他们完成
Parallel.Invoke( () => new Ping().Send("www.oreilly.com"), () => new Ping().Send("stackoverflow.com")); Parallel的所有方法都不会自行对结果收集,我们需要自己收集
var res = new List<string>(); Parallel.Invoke( () => { var p = new Ping().Send("www.oreilly.com"); res.Add(p.Address + $" coast {p.Status}ms : " + p.RoundtripTime); }, () => { var p = new Ping().Send("stackoverflow.com"); res.Add(p.Address + $" coast {p.Status}ms : " + p.RoundtripTime); }); foreach (var item in res) { _testOutputHelper.WriteLine(item); } 输出:
151.101.193.69 coast Successms : 166 23.7.172.78 coast Successms : 227 上面这份代码有个陷阱,由于两个任务之间没有发生竞态(他们相隔实在太远啦),因此让我们忽略了线程安全问题。哪怕是在收集数据,也请不要忽略,这两个委托可能是在不同线程上执行的,对公共数据写入当然会引发线程安全问题,这一点我们在前面的章节中已经讲烂了。
只要将List 替换成ConcurrentBag即可,并发集合也属于PFX的组成部分,下文再具体讲。
var res = new ConcurrentBag<string>(); ParallelOptions
Parallel 的四种方法均提供重载接受一个参数ParallelOptions
new ParallelOptions { CancellationToken = default, // 取消令牌,默认CancellationToken.None,没得 MaxDegreeOfParallelism = Environment.ProcessorCount, // 最大并发度,默认是CPU核心数 TaskScheduler = null // 任务调度器,默认TaskScheduler.Default,由线程池调度 }, 取消
ok,我们给上面那个ping加个超时取消看看
... var source = new CancellationTokenSource(); source.CancelAfter(1); Parallel.Invoke( new ParallelOptions { CancellationToken = source.Token, }, ... 结果是不管我在多久后取消,哪怕1ms后就取消令牌,结果都没变化。。莫非取消令牌坏了吗?当然不是啦,还记得我们从第一章讲线程基础的时候就提到的取消协作模式吗,这种模式是安全的,他不会立即干掉正在执行迭代中的线程,而是等待线程执行完本次迭代,这种思路贯彻整个线程取消设计。
For与ForEach
命名上大家就应该能看懂这在干什么了,没错,就是并行版本的循环
public static ParallelLoopResult For(int fromInclusive, int toExclusive, Action<int> body) public static ParallelLoopResult ForEach<TSource>(IEnumerable<TSource> source, Action<TSource> body) 使用Parallel.For并行生成六组密钥对
var keyPairs = new string[6]; Parallel.For(0, keyPairs.Length, i => keyPairs[i] = RSA.Create().ToXmlString(true)); 同样可以使用PLINQ,他们在结构和结果上是一致的
string[] keyPairs = ParallelEnumerable.Range(0, 6) .Select(i => RSA.Create().ToXmlString(true)) .ToArray(); 索引
Parallel.ForEach 中使用索引需要用另一个重载:
public static ParallelLoopResult ForEach<TSource>(IEnumerable<TSource> source, Action<TSource, ParallelLoopState, long> body) 第三个参数long类型的i,就是索引
Parallel.ForEach("Hello, worldmmmmmmmmmmmm", (c, state, i) => { _testOutputHelper.WriteLine(i++ + c.ToString()); }); 那我们继续,用Parallel.ForEach 来改造一下之前的拼写检查。由于我们不需要在去Select一次了,这次不用结构体也无所谓,因为Add不会成为瓶颈。
var errors = new ConcurrentBag<(long Index, string Word)>(); Parallel.ForEach(wordsToTest, (word, state, i) => { if (!wordLookup.Contains(word)) errors.Add((i, word)); }); 跳出循环
Parallel循环 并不能像普通循环那样使用 break 语句来跳出循环,不过它提供了 ParallelLoopState来帮助你完成这个需求
Parallel.ForEach("Hello, worldmmmmmmmmmmmmmmm", (c, state) => { if (c == 'l') state.Stop(); _testOutputHelper.WriteLine(c.ToString()); } 你会发现输出了核心数个字符。
使用Break也能跳出并行循环,但是可能会多输出几个。原因是Break传达的:是希望系统在方便的时候尽早的跳出。而Stop传达的是:立刻(遵循协作取消模式)。
ParallelLoopState 还提供了一些常用属性:
ShouldExitCurrentIteration:收到任何退出循环的通知,这个属性都会变成true,包括Stop、Break、取消、异常。IsExceptional:可以知晓是否有异常发生。
ParallelLoopResult
Parallel循环 返回的是一个结构体ParallelLoopResult,它有两个属性:
IsCompleted:表示循环是运行完成,False表示提前结束LowestBreakIteration:获取Break调用出的元素索引,如果是通过Stop退出的,则为null
聚合
如果我们要计算1到1000万的平方根之和,并行非常容易(加法满足交换律和结合律)。但是求和就麻烦了,需要加锁,这成为了程序的瓶颈。
var locker = new object(); double total = 0; Parallel.For(1, 1000_0000, x => { lock (locker) { total += Math.Sqrt(x); } }); 在PLINQ 中,我们讲聚合的时候提到一种局部种子的方案,这里是不是也能参考呢?事实上我们真的需要1000w次排队累加吗,我们难道不能在各个线程设置独立的累加器,然后累加这些累加器吗?Parallel的循环还真提供了这样的重载:
var locker = new object(); double total = 0; Parallel.For(1, 1000_0000, () => 0.0, (x, state, local) => local + Math.Sqrt(x), local => { lock (locker) { total += local; } }); 简单一跑,性能百倍提升~
这个案例只是为了说明Parallel,其实用PLINQ 更为简单:
var res = ParallelEnumerable.Range(1, 1000_0000) .Sum(x => Math.Sqrt(x)); ForEachAsync
为什么单独来一part ForEachAsync,这玩意看名字不就是ForEach的异步版本吗。nonono,这玩意我单独拎出来给大家隆重介绍,NET6 引入的
public static Task ForEachAsync<TSource>(IEnumerable<TSource> source, Func<TSource, CancellationToken, ValueTask> body) public static Task ForEachAsync<TSource>(IEnumerable<TSource> source, CancellationToken cancellationToken, Func<TSource, CancellationToken, ValueTask> body) public static Task ForEachAsync<TSource>(IEnumerable<TSource> source, ParallelOptions parallelOptions, Func<TSource, CancellationToken, ValueTask> body) 你仔细想想,在NET6之前,Task的并发度你咋控制?你是不是这样的
using var semaphore = new SemaphoreSlim(6, 6); var tasks = Enumerable.Range(1, 100).Select(async x => { try { await semaphore.WaitAsync(); await Task.Delay(1000); _testOutputHelper.WriteLine("线程 " + Thread.CurrentThread.ManagedThreadId + " 干了活" + x); } finally { semaphore.Release(); } }); Task.WaitAll(tasks.ToArray()); 现在有了Parallel提供的ForEachAsync,你只需要这样:
await Parallel.ForEachAsync(Enumerable.Range(1, 100), new ParallelOptions() { MaxDegreeOfParallelism = 10 }, async (x, _) => { await Task.Delay(1000); _testOutputHelper.WriteLine("线程 " + Thread.CurrentThread.ManagedThreadId + " 干了活" + x); }); 比较遗憾的是,ForEachAsync 并不像ForEach 那样提供了索引。。