- A+
所属分类:linux技术
1.shell命令的执行机制:fork+exec执行命令(任何的shell都会执行)
2.shell中的用户输入处理
1 命令行参数:选项、参数 2 运行时输入 3 read命令: 4 1.基本读取、 5 2.超时处理-t选项、 6 3.隐藏方式读取-s选项) 7 4.从文件中读取
3.shell的反引号
1 /* 2 ``反引号在Linux shell命令行中有特殊的含义:反引号间的内容,会被shell先执行。其输出被放入主命令后,主命令再被执行。命令替换,即完成引用的命令的执行,将其结果替换出来,与变量替换差不多 3 */ 4 echo `date '--date=1 hour ago' +%Y-%m-%d-%H` 5 echo $(date '--date=1 hour ago' +%Y-%m-%d-%H)
4.setuid
setuid位是让普通用户可以以root用户的角色运行只有root帐号才能运行的程序或命令。
因此当程序设置了setid权限位时,普通用户会临时变成root权限,但实际用户任然是原来的mike。
5.linux文件
/etc/mtab文件的作用:记载的是现在系统已经装载的文件系统,包括操作系统建立的虚拟文件等;
/etc/fstab是系统准备装载的find命令:以递归的方式进行搜索文件或文件夹
6.find命令


1 1 --查找当前目录下所有文件中包含deposit_account的文件 2 2 -- f 普通文件 l 符号连接 d 目录 c 字符设备 b 块设备 s 套接字 p Fifo 3 3 find . -type f -print |xargs grep "deposit_account" 4 4 --查找根目录下名字为create.txt的文件 5 5 find / -name "create.txt" 6 6 --查找根目录下文件大小大于100M的文件 7 7 find / -size +100M 8 8 --使用find查找png和jpg的文件 -o 指定多个-name选项 9 9 find . -name '*.png' -o -name '*.jpg' -type f
find
7.for循环
1 1 /*for 变量名 in 取值列表({1..100}--1到100依次执行、{1..100..2} --间隔2个) 2 2 do 3 3 命令序列 4 4 done 5 5 --举例*/ 6 6 sum=0 7 7 for ((i=1;i<100;i++)) 8 8 do 9 9 sum=$($i+$sum) 10 10 done 11 11 echo "0-100的和为:" $sum
for循环
8.正则表达式
1 1 --行首定位符“^”:用来匹配行首的字符 2 2 --列出etc目录下以po开头的文件 3 3 str='ls /etc |grep "^po"' 4 4 echo "$str" 5 5 6 6 --行尾定位符“$” 7 7 str='ls /etc |grep "conf$"' 8 8 echo "$str" 9 9 10 10 --单个字符匹配“.”:圆点“.”用来匹配任意单个字符,包括空格,但是不包括换行符“n” 11 11 --列出所有的包含字符串“13”的文件名 12 12 str=`cat dian.txt | grep "13"` 13 13 echo "$str" 14 14 echo "-------------" 15 15 --列出包含字符串'13'以及另外一个字符的文件名 16 16 str=`cat dian.txt | grep "13."` 17 17 echo "$str" 18 18 19 19 --限定符“*”:用来指定其前面的一个字符必须要重复出现多少次才能满足匹配 20 20 str=`ls /etc | grep "^sss*"` 21 21 echo "$str" 22 22 23 23 --字符集匹配“[]” 24 24 /*"[a-f]”表示匹配字母表中a到f中的任意一个字母。 25 25 “[0-9]”表示匹配任意单个数字 26 26 "[^b-d]” 匹配除了从 b 到 d 范围内所有的字符 --取反 27 27 */ 28 28 --筛选所有以字符r开头,并且紧跟着1个字符c的文本行 29 29 str='ls /etc |grep "^rc"' 30 30 echo "$str" 31 31 echo "---------------------" 32 32 --筛选所有以字符r开头,紧跟着1个字符为c,下面1个字符为单个数字的文本行 33 33 str='ls /etc | grep "^rc[0-9]"' 34 34 echo "$str" 35 35 36 36 37 37 --字符集不匹配“[^]”:表示不匹配其中列出的任意字符 38 38 "[^b-d]” 匹配除了从 b 到 d 范围内所有的字符 39 39 40 40 --反斜杠字符 转义 使这个字符表示原来字面上的意思 41 41 “$“表示了原来的字面意思”$”,而不是在正则表达式中表达的匹配行尾的意思. 42 42 43 43 --转义(escape) “尖角号” <...> 44 44 用于表示单词的边界. 尖角号必须被转义,因为不这样做的话它们就表示单纯的字面意思而已."<the>" 匹配单词"the",但不匹配"them", “there”, “other”, 等等.
正则表达式
9.扩展正则表达式
1 1 --限定符“+” :匹配一个或多个前面的字符.和*相似,区别是它不匹配零个字符的情况. 2 2 --筛选以字符串“ss”开头,后面至少紧跟着1个字符“s”的文本行 3 3 str=`ls /etc | egrep "^sss+"` 4 4 echo "$str" 5 5 --输出 6 6 sssd 7 7 8 8 --限定符“?”:限定前面的字符最多只出现1次,即前面的字符可以重复0次或者1次。 9 9 str=`ls /etc | egrep "^sss?"` 10 10 echo "$str" 11 11 --输出 12 12 ssh 13 13 ssl 14 14 sssd 15 15 16 16 --竖线“|” 和圆括号“()”: 17 17 --竖线“|” 表示多个正则表达式之间“或”的关系 18 18 --竖线“|” 表示多个正则表达式之间“或”的关系 19 19 #筛选含有字符串“ssh”、“ssl”或者以字符串“yum”开头的文本行 20 20 #grep -E主要是用来支持扩展正则表达式 21 21 #grep -E =egrep 22 22 str=`ls /etc | egrep "(ssh|ssl|^yum)"` 23 23 echo "$str" 24 24 25 25 26 26 --转义“大括号”{}指示前边正则表达式匹配的次数,要转义是因为不转义的话大括号只是表示他们字面上的意思 27 27 “[0-9]{5}” --精确匹配 5 个数字 (从 0 到 9 的数字)
扩展正则表达式
10.perl正则表达式
1 --数字匹配d 符号“d”匹配从0到9中的任意一个数字字符,等价于表达式“[0-9]” 2 --筛选以字符串rc开头,紧跟着一个数字的文本行 -P可以让grep使用perl的正则表达式语法 3 str=`ls /etc | grep -P "^rcd"` 4 echo "$str" 5 6 --非数字匹配D “D”等价于表达式“[^0-9]” 7 --空白字符匹配s :匹配任何空白字符,包括空格、制表符以及换页符=“[fnrtv]”。 8 --非空白字符匹配S:符号“S”匹配任何非空白字符,等价于表达式“[^fnrtv]”
perl正则表达式
处理海量数据的命令:grep、cut、awk、sed
grep、sed命令是对行进行提取
cut、awk命令是对列进行提取
11.grep命令
1 /* 2 grep [选项]...[内容]... 3 -v 对内容进行取反提取 4 -n 对提取的内容排列,显示行号 5 -w 精确匹配 6 -i 忽略大小写 7 ^ 匹配行首 8 -E 正则匹配 9 */ 10 grep 'user' /etc/passwd --匹配包含user的行 11 grep -n 'user' /etc/passwd --显示行号
grep
12.awk命令
1 /* 2 而awk比较倾向于将一行分成多个"“字段"然后再进行处理。awk信 息的读入也是逐行读取的,在使用awk命令的过程 中,可以使用逻辑操作符”&“表示"与”、"||表示"或"、"!“表示非”;还可以进行简单的数学运算,如H+、 -、*、/、%、^分别表示加、减、乘、除、取余和乘方。 3 awk 选项 '{操作}' 文件名 4 */ 5 awk '{print}' zz.txt --默认输出所有 6 awk -F: '{print $1}' zz.txt --分隔符为:输出第一列 7 echo 'this is a test' | awk '{print $NF}' --$NF表示最后一个字段 8 awk -F ':' '{ print toupper($1) }' demo.txt --将输出的字符转成大写 9 --awk '条件 动作' 文件名 结合正则表达式 10 awk -F ':' '/usr/ {print $1}' demo.txt --只输出包含usr的行 11 awk -F ':' 'NR % 2 == 1 {print $1}' demo.txt --输出奇数行 12 awk -F ':' '$1 == "root" {print $1}' demo.txt --输出第一个字段等于指定值的行
awk
13.route命令
1 /* 2 在网络中,route命令用来显示、添加、删除和修改网络的路由。 3 route [-f] [-p] [Command] [Destination] [mask Netmask] [Gateway] [metric Metric] [if Interface] 4 route -f:用于清除路由表 5 route -p:用于创建永久路由 6 route Command:主要有print(打印路由)、ADD(添加路由)、DELETE(删除路由)、CHANGE(修改路由)4个常用命令 7 route Destination:表示到达的目的IP地址 8 route MASK:表示子网掩码的关键字 9 route Netmask:表示具体的子网掩码,如果不进行设置,系统默认设置成255.255.255.255(单机IP地址),添加掩码时要注意,特别是要确认添加的是某个IP地址还是IP网段,如果代表全部出口子网掩码可用0.0.0.0 10 route Gateway:表示出口网关 11 route interface:表示特殊路由的接口数 12 route metric:表示到达目的网络的跳数 13 -net 后面跟的是目标网络,gw就是gateway(网关入口) 14 */ 15 --局域网的网络地址192.168.1.0/24,局域网络连接其它网络的网关地址是192.168.1.1。主机192.168.1.20访问172.16.1.0/24网络时,其路由设置正确的是 16 route add –net 172.16.1.0 gw 192.168.1.1 netmask 255.255.255.0 metric 1
route
14.cut命令
1 cut是一个选取命令,就是将一段数据经过分析,取出我们想要的。一般来说,选取信息通常是针对“行”来进行分析的 2 cut [-bn] [file] 或 cut [-c] [file] 或 cut [-df] [file] 3 -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了-n标志。 4 -c :以字符为单位进行分割。 5 -d :自定义分隔符,默认为制表符。 6 -f :与-d一起使用,指定显示哪个区域。 7 -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的<br />范围之内,该字符将被写出;否则,该字符将被排除。 8
cut
15.sed命令
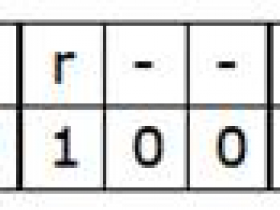
1 -n --把匹配到的行输出打印到屏幕 2 p --以行为单位进行查询,通常与-n一起使用 3 eg:df -h | sed -n '2p' --打印第二行 4 d --删除 eg :df -h |sed '2d' --删除第二行 5 a --在行下边插入新的内容 eg:sed '2d 122344' 1.txt 6 i --在行上边插入新的内容 eg:sed '2i 122344' 1.txt 7 c --替换 eg:sed '2c 122344' 1.txt 8 s/被替换的内容/新的内容/g --eg: sed s/"//g 1.txt 9 -i --对源文件进行修改 --eg: sed -i s/"//g 1.txt 10 -e --表示可以执行多条动作 11 sed -n '/100%/p' 1.txt --匹配到100%的打印出来
sed
16.xargs命令
1 /*xargs是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具,它擅长将标准输入数据转换成命令行采纳数。xargs能够处理管道或者stdin并将其转换成特定命令的命令参数。xargs也可以单行或多行文本输入转换为其他格式,例如多行转单行,单行转多行。xargs的默认命令是echo,空格是默认定界符。 2 */ 3 --多行换入单行输入 4 cat test.txt | xargs 5 ---n 选项多行输出 6 cat test.txt | xargs -n3 7 --d 自定义定界符 8 echo "abcadbsbdkvbwwlg" | xargs -db
xargs
17.sort命令
1 /* 2 sort命令将文件的每一行作为比较对象,通过将不同行进行相互比较,从而得到最终结果。比较原则是从首字符开始,向后依次按ASCII码值进行比较,最后将结果按升序输出 3 参数: 4 sort -u :在输出行中去除重复行 5 sort -r :sort命令默认的排序方式是升序,如果想改成降序,就需要加上 -r 6 sort -o :由于sort默认是把结果输出到标准输出,所以需要用到重定向才能将结果写入文件,形如sort filename > newfile。但是,如果你想把排序结果输出到原文件中,用重定向可就不行了,需要 7 */ 8 sort -n -k 2 -t : facebook.txt --以冒号分割开,以第二列进行排序 9 sort -r number.txt -o number.txt --排序后重定向到number.txt 10 cat words.txt|xargs -n 1 |sort -r
View Code
18.uniq命令
1 /* 2 uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。 3 uniq 可检查文本文件中重复出现的行列,直接去重 4 -c: 在每列旁边显示该行重复出现的次数。 5 -d: 仅显示重复出现的行列,显示一行。 6 -D: 显示所有重复出现的行列,有几行显示几行。 7 -u: 仅显示出一次的行列 8 -i: 忽略大小写字符的不同 9 -f Fields: 忽略比较指定的列数。 10 */ 11 --统计words文件里边每个单词出现的次数 12 cat words.txt|xargs -n 1 |sort -r |uniq -c |awk 'print{$2" "$1}' 13 --忽略第一列的字符 14 uniq -c -f 1 uniq.txt 15 --忽略前边四个字符 16 uniq -c -s 4 uniq.txt
View Code