- A+
本来闲来无事,准备看看Dapper扩展的源码学习学习其中的编程思想,同时整理一下自己代码的单元测试,为以后的进一步改进打下基础。
突然就发现问题了,源码也不看了,开始改代码,改了好久。
测试Dapper.LiteSql数据批量插入的时候,耗时20秒,感觉不正常,于是我测试了非Dapper版的LiteSql的批量插入,仅需100毫秒,速度差了200倍。
同样的数据库、同样的Npgsql.dll、同样的测试代码,产生的SQL和参数集合也是一样的,最后不得不怀疑Dapper。
引用Dapper的源码,修改调试之后,我决定提个PR。我之前没想过提PR,我想我也不是为了提PR而提PR,我也不想费时费力。
没想到提PR的过程很不顺利,原来提的PR需要单元测试全部通过才行。
先是提交了一行代码,认为没有问题,结果被打了个叉。仔细一看才发现,原来是单元测试不通过。
改了又改,有几个存储过程相关的单元测试总是不通过。
都快要放弃了,后来想到是不是我定义的cleanNames变量随着DynamicParameters类的创建,又清空了,但cleanNames又不能定义成全局的。后来我加了几行代码。
一共提交了12次,单元测试终于全部通过,共增加了11行代码。
PR是提交了,是否被采纳就不知道了。也许代码写的比较挫,也许审核人员不认可我对Dapper的这种用法,是我用错了,没有修改的必要。
修改DynamicParameters.cs文件
变量定义:
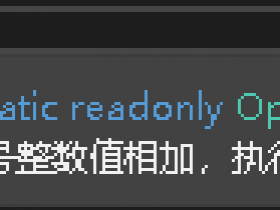
private readonly HashSet<string> cleanNames = new HashSet<string>(); 单元测试始终无法全部通过,我添加了下面几行代码,终于成功了。原来cleanNames被重新new了之后,command.Parameters里可能是有值的,它的作用域更大一些。
foreach (IDbDataParameter param in command.Parameters) { if (!cleanNames.Contains(param.ParameterName)) { cleanNames.Add(param.ParameterName); } } 关键的修改就一行
原代码(参数很多时性能不行,参数什么情况下会很多呢?就是通过一条SQL批量Insert时会有很多参数,我是500条数据插入一批,参数根据表字段多少可能有几千个):
bool add = !command.Parameters.Contains(name); 当command.Parameters中有几千个参数的时候,性能就惨不忍睹了。
集合查找的时间复杂度是O(N/2)。
修改为(HashSet性能很高):
bool add = !cleanNames.Contains(name); 通过HashSet查找,时间复杂度是O(1)。
往cleanNames中添加字段名:
if (add) { command.Parameters.Add(p); cleanNames.Add(name); } 总结
-
关于List集合的Contains方法
当你使用Contains方法的时候,你要考虑这个集合有没有可能突然变的数据量很大?如果是在循环中频繁调用,并且List的数据量比较大,它的性能就比较差,建议使用HashSet或Dictionary来判查找。
但是HashSet、Dictionary和List转来转去也有代价,IDbCommand接口的Parameters属性的类型是IDataParameterCollection,它是一个集合,并没有HashSet或Dictionary类型的属性,又必须要转换才能得到。
提的issue和PR
issue:https://github.com/DapperLib/Dapper/issues/1817
PR:https://github.com/DapperLib/Dapper/pull/1816
LiteSql源码
LiteSql源于DBHelper,里面的接口是做过实际项目的,主要是ERP、CRM系统。
简单支持了Lambda表达式、增加了SqlString之后,使用上似乎变复杂了一点,不过原来的使用方式依然支持。
也许这里面的接口和设计思想,体现的是我上家公司的前辈们的技术水准。比如实体类用partial修饰分成两个文件,可能有利有弊吧。自动生成的Model类是不建议修改的,否则数据库变动的时候你还怎么自动生成?不把你的改动冲掉了?
一个ORM有它的设计思想和理念,比如DapperExtensions就不建议对实体类加特性,而是通过独立的映射类来处理表、字段别名,优缺点我还不清楚。
LiteSql的后续改进,还没有新的指导思想,所以一直都是小改,基本没怎么动。
https://gitee.com/s0611163/Dapper.LiteSql
https://gitee.com/s0611163/LiteSql
即使是大名鼎鼎的Dapper我依然不放心,所以保留了ADO.NET的版本。