- A+
-
BIO模型
在Linux中,默认情况下所有socket都是阻塞模式。用户线程调用系统函数read()【system call】,内核开始准备数据(从磁盘/网络获取数据),内核准备数据完成后,用户线程完成数据从内核拷贝到用户空间的应用程序缓冲区,数据拷贝完成后,请求才返回。从发起read请求到完成内核到应用程序的拷贝,整个过程都是阻塞的。
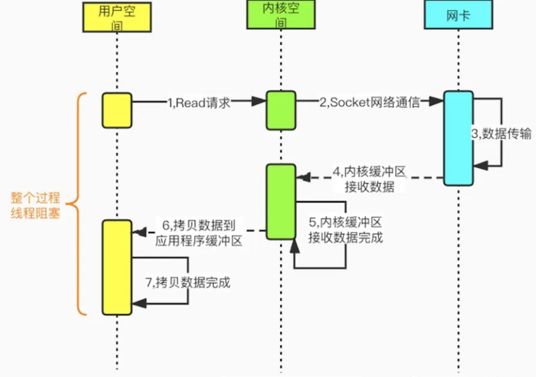
为了减轻线程阻塞的弊端,实际上,每个Read/Write请求都会分配单独线程进行单独处理。在低并发时期,这种每个请求每线程的处理方式是可以应付的,但是如果在高并发期间(如:业务高峰期),就会分配大量的线程完成请求处理。因此会带来非常大的性能损耗。 -
NIO模型
用户线程在发起Read请求后立即返回,不用等待内核准备数据的过程。如果Read请求没读取到数据,用户线程会不断轮询发起Read请求,直到数据到达(内核准备好数据)后才停止轮询。
非阻塞IO模型虽然避免了由于线程阻塞问题带来的大量线程消耗,但是频繁的重复轮询大大增加了请求次数,对CPU消耗也比较明显。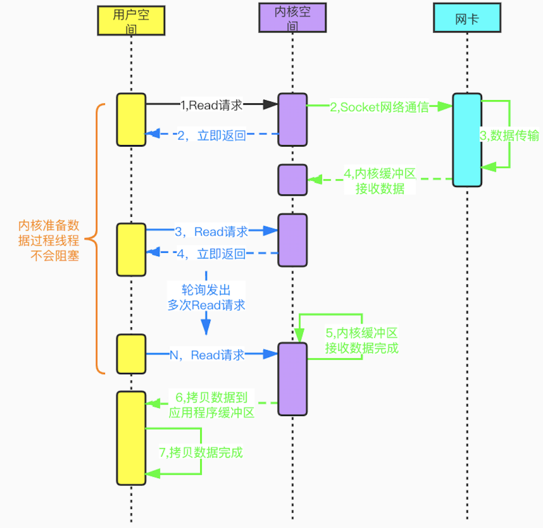
-
多路复用模型
多路复用IO模型,建立在多路事件分离函数select,poll,epoll之上。在发起read请求前,先更新select的socket监控列表,然后等待select(或poll或epoll)函数返回(此过程是阻塞的)。当某个socket有数据到达时,select函数返回。此时用户线程才正式发起read或write请求,处理数据。这种模式用一个专门的监视线程去检查多个socket,如果某个socket有数据到达就交给工作线程处理。由于等待Socket数据到达过程非常耗时,所以这种方式解决了阻塞IO模型一个Socket连接就需要一个线程的问题,也不存在非阻塞IO模型忙轮询带来的CPU性能损耗的问题。
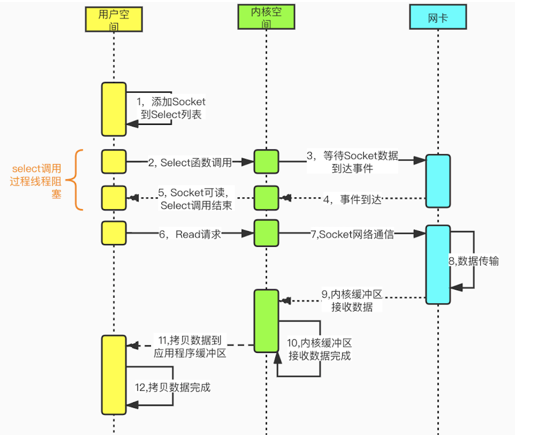
多路复用的本质,在我看来其实就是通过尽可能少(预期一次)的系统调用(system call),就可以拿到所有socket的状态(是否可读),然后程序只需要对那些返回状态为可读或可写的socket进行处理。

1 // NIO核心代码 2 // 初始化 3 channel = ServerSocketChannel.open(); 4 channel.bind(port); 5 channel.configureBlocking(false); 6 // selector 注册accept事件 7 selector = Selector.open(); 8 channel.register(selector, SelectionKey.OP_ACCEPT); 9 while(true){ 10 while(selector.select(timeout)>0){ // 有新的事件 11 // 获取到可处理的 Socket 12 Set<SelectionKey> keySet = selector.selectedKeys(); 13 Iterator<SelectionKey> iter = keySet.iterator(); 14 while (iter.hasNext()) { // 循环处理,处理之后应该从迭代器中移除 15 SelectionKey key = iter.next(); 16 iter.remove(); 17 if (key.isAcceptable()) { // 新连接 acceptHandle(key); } 18 else if (key.isReadable()) { // 读事件 readHandle(key); } 19 else if (key.isWritable()) { // 写事件 writeHandle(key); } 20 } 21 } 22 }
View Code
实际上,linux的多路复用有三种实现方式,select和poll以及epoll,它们之间的关系是进化关系,性能都是递进的。
-
select
select 是操作系统提供的系统调用函数,通过它,我们可以把一个文件描述符的数组【最大为1024个】发给操作系统内核, 让内核去遍历,确定哪个文件描述符可以读写,实际上只是打了一个标志,哪些可读可写,所以在用户程序获取select的返回值的时候,仍然需要遍历文件描述符的数组具有哪些可处理的事件。
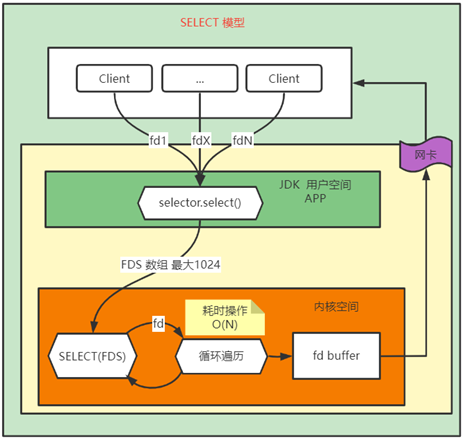
select模型的优化在于将所有的文件描述符【其实就是正在监听的socket连接】批量的传给了内核,降低了系统调用,减少了内核态与用户态的切换。而select的弊端就在于每次最多只能传输1024个文件描述符,这在一些高并发场景【redis缓存】下,仍然是不够看的。此外select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。 -
poll
poll对于select来讲,最大的区别在于只是将每次只能传输1024个文件描述符的限制去掉了
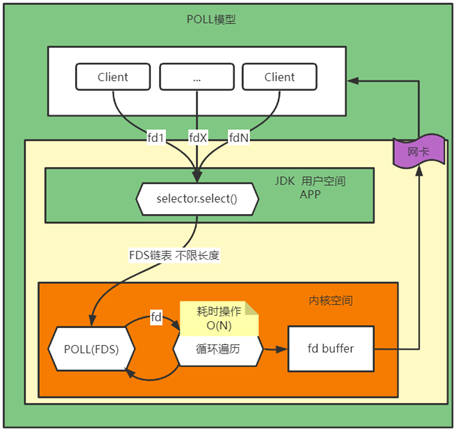
-
epoll
epoll是在select和poll的基础上做出的演进。他主要针对以下3点做出了改进
1.内核中保存一份文件描述符的集合,无需用户程序每次懂重新传递【不需要拷贝】;
2.内核不再通过轮训的方式获取事件就绪的文件描述符,而是通过事件回调的方式将就绪事件放入到一个就绪队列中【内核程序不需要进行O(N)的遍历】;
3.内核仅会将就绪队列中的文件描述符返回给用户程序,用户程序直接处理该描述符对应的事件即可【用户程序不需要再次进行O(N)的遍历,内核将不必要的文件描述符过滤了,因此发生的内存拷贝更少了】。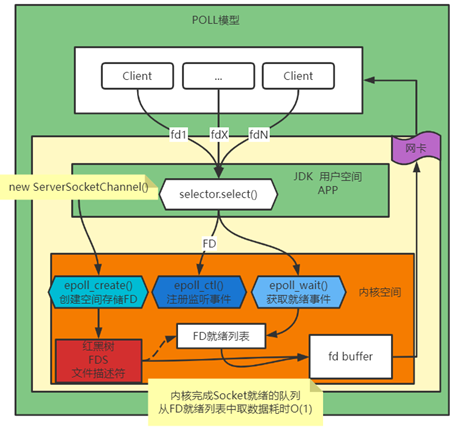
-
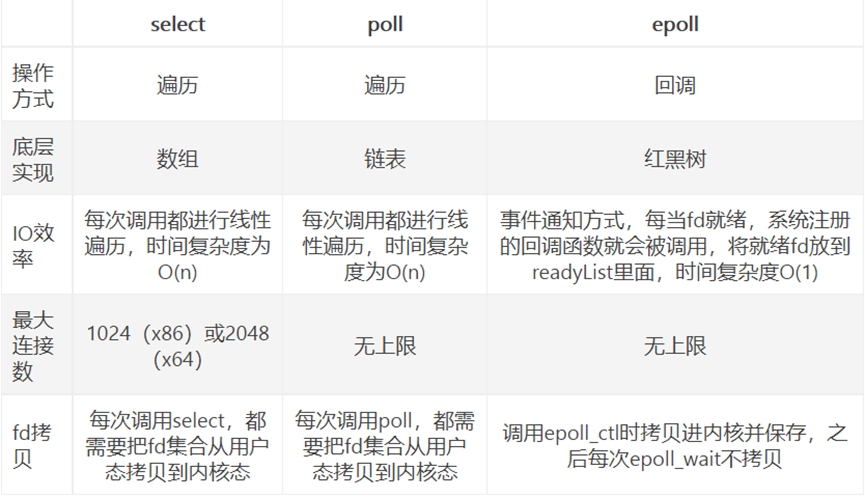
select、poll、epoll对比
AIO
不论是阻塞IO亦或是NIO,它们都是同步IO,即当内核将数据准备好的时候,都是由用户线程将数据拷贝到用户空间。除此之外还有一个异步IO,即非阻塞IO,当数据准备好的时候,不需要用户线程将数据拷贝到程序的运行空间,而是直接由内核线程完成数据的拷贝。
参考文件:
1.彻底搞懂IO多路复用
2.忘了一些重要的文章~~~
-